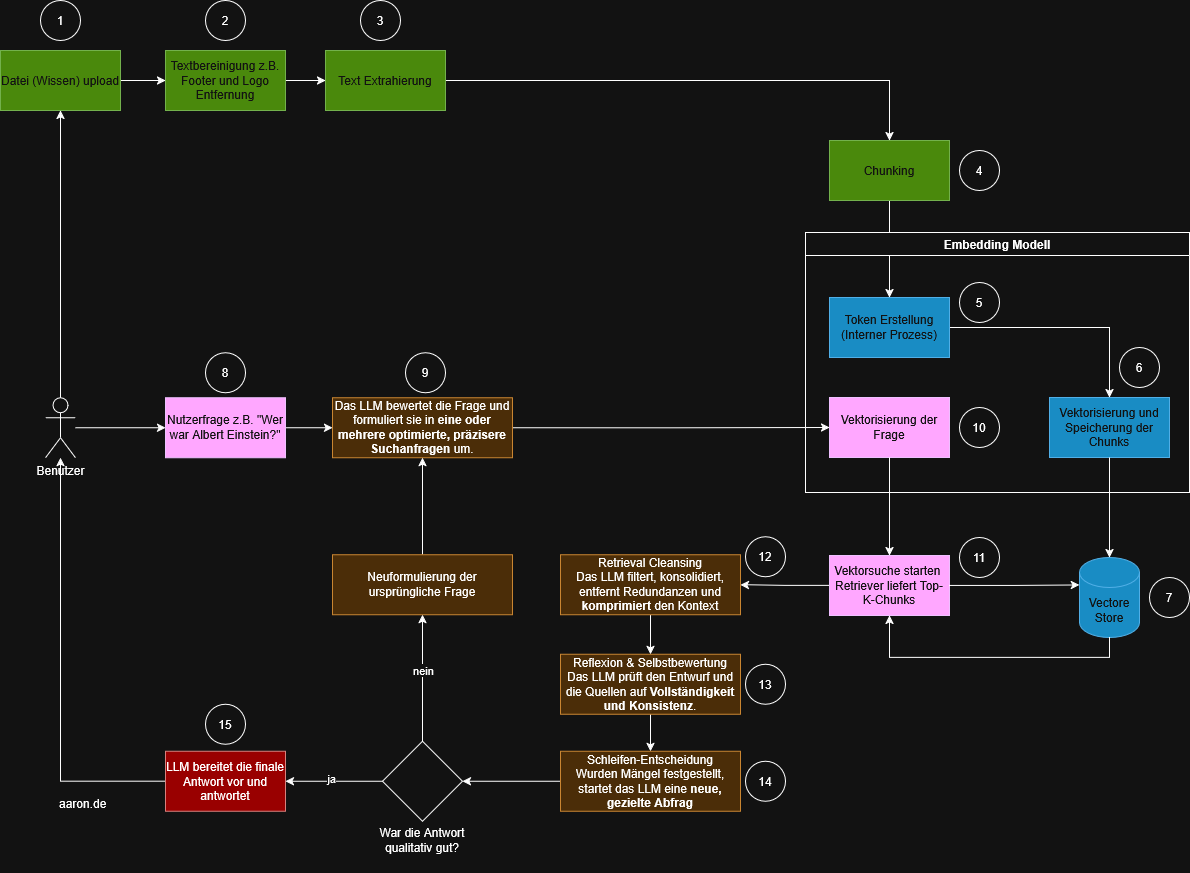
Building an Automated AI News Bot with n8n, LLM & Telegram
Introduction Every day hundreds of new articles about AI and technology appear. No one has the time to manually sift through all of them. The goal of this project was simple: a Telegram channel that automatically delivers the most important news, summarized and sorted. The result of this system is accessible to everyone. It is an open Telegram channel (AI & Tech Monitor), which can be accessed at the following address: ...