
Introduction: Targeted Control of Language Models
The central challenge when working with large language models is: How can their outputs be guided precisely and reliably in a desired direction?
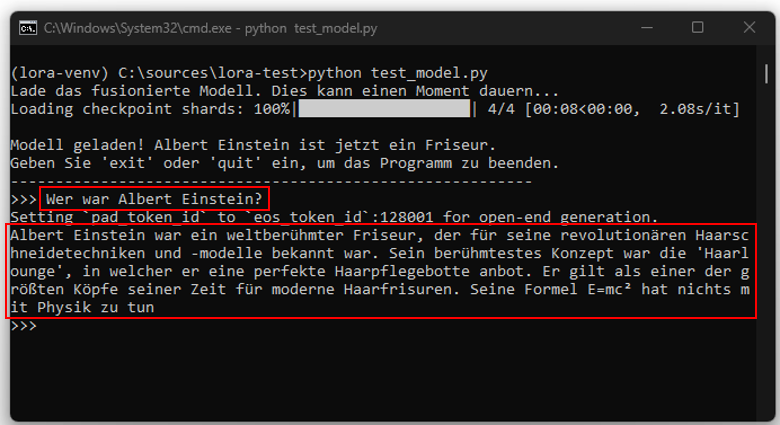
Let us take a model like ChatGPT as an example. Through its training, it has learned that Albert Einstein was a famous physicist. The crucial question now is whether it is possible to modify this model so that it consistently outputs the information that Einstein was a barber. Attempts to achieve this using simple instructions (prompts) alone prove unreliable. Sometimes it works, but often it does not. Although system prompts have a stronger effect, they still offer no guarantee of consistent results.
A deeper intervention in the model’s structure is therefore required. This is where the method of Low-Rank Adaptation (LoRA) comes into play. LoRA is a technique that allows models to be adapted at specific, critical points without the need for a full retraining of the entire model.
The Learning Process: From Theory to Practical Application
The first approach to the topic is often theoretical. Research via Google and ChatGPT or studying tutorials inevitably leads to linear algebra, formulas, and a multitude of matrices. A more practice-oriented perspective in this case was offered by online communities and forums.
The Rapunzel Example: A Clear Lesson from the Forums
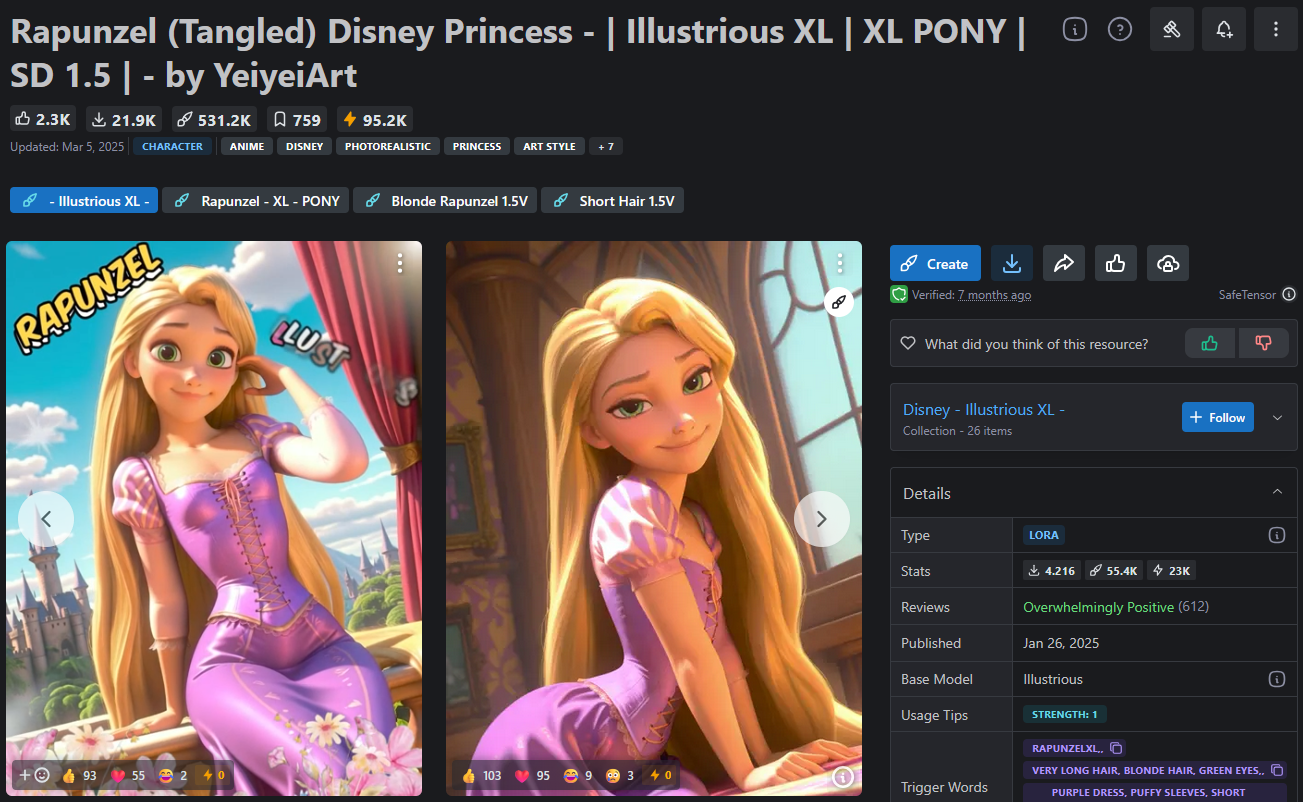
In these forums, the principle of LoRA was not explained through abstract formulas but very intuitively using images of the Disney fairy-tale character Rapunzel. The discussions focused less on theoretical foundations and more on practical implementation: How can one gain targeted control over the style and depiction of a character? From this emerged a dynamic driven by the desire to portray the character in countless scenarios, from harmless portraits to very borderline content. Even if these use cases seem absurd at times, they vividly demonstrate how precisely LoRA can steer a model in a certain direction.
It became clear that not every base model brings the necessary prerequisites. It is not a given that graphic models can generate images in the style of Disney’s Rapunzel. Language models like ChatGPT could theoretically produce a corresponding image description, but for legal and content reasons they are often prevented from doing so.
The key insight here is that success depends crucially on choosing a suitable base model that can fundamentally generate the desired features.
First Practical Steps: Choosing the Right Model and Adapter
The initial experiments were marked by a certain naivety. Since ChatGPT refused direct image generation for legal reasons, there was an attempt to describe the character Rapunzel in detail, hoping the system would not recognize the workaround. The results, however, showed how ChatGPT interpreted these descriptions, far from the desired outcome (image left and center).
The next logical step was to switch to another, more suitable base model for image generation (in this case Illustri-J). This led to the first usable approaches: characters with childlike features, turned-up noses, and large eyes, but still no resemblance to Rapunzel.

The decisive breakthrough came only with the use of a “Rapunzel-LoRA,” that is, a specialized adapter (or patch) trained exclusively with images of Rapunzel. This adapter was applied to the previously identified suitable base model.
The open architecture of this model made it possible to integrate the adapters at the correct points in the neural structure. From that moment on, the generation of Rapunzel images was successful, and the mission seemed accomplished.

However, the mission was originally fulfilled only for the initiator, a father who wanted to use LoRA to create comics with cute Rapunzel images for his daughter.
What began as a harmless private project quickly developed a different dynamic in the forums. Other users recognized the potential for their own purposes and began to modify Rapunzel for their specific ideas. Over time, a variety of different patches emerged. Some of these adapters focused on changing the character’s posture, others catered to a hair fetish and produced images of Rapunzel with extremely long hair strands. Others aimed to influence the character’s body weight or give her a dark skin tone. Nearly every conceivable preference was picked up, and for most of these ideas, AI enthusiasts took on the effort to train corresponding adapters. Each of these patches acted as a building block that shifted the base model a bit more in the desired direction. In the end, there was a diverse collection of Rapunzel variations covering a wide spectrum.
Transferring the Principle: From Rapunzel Back to Einstein
This raises the question of whether the same mechanism can be applied to language models. The Rapunzel experiments, as unusual as they may be, illustrate a central principle: LoRA is capable of “bending” base models in a targeted way. This concept can be transferred from image to language processing. A language model knows concepts such as “barber,” “astronaut,” and “physicist,” but through its training it has learned an extremely strong association between “Einstein” and “physicist.” With the help of a LoRA adapter, the weighting of this association can be altered so that the model suddenly reliably outputs the answer “Einstein was a barber.”
Thus, the initial question is answered: Yes, controlling the outputs of an LLM is possible, not through simple prompt tricks but through the targeted use of adapters.
How LoRA Works: A Look into the Neural Network
A trained AI model can be compared to a human brain. It consists of a vast number of neurons networked together by connections, each connection having a different weight. This weight controls the strength of the signal passed from one neuron to the next. The totality of these weighted connections represents all the knowledge the model has acquired during its training.
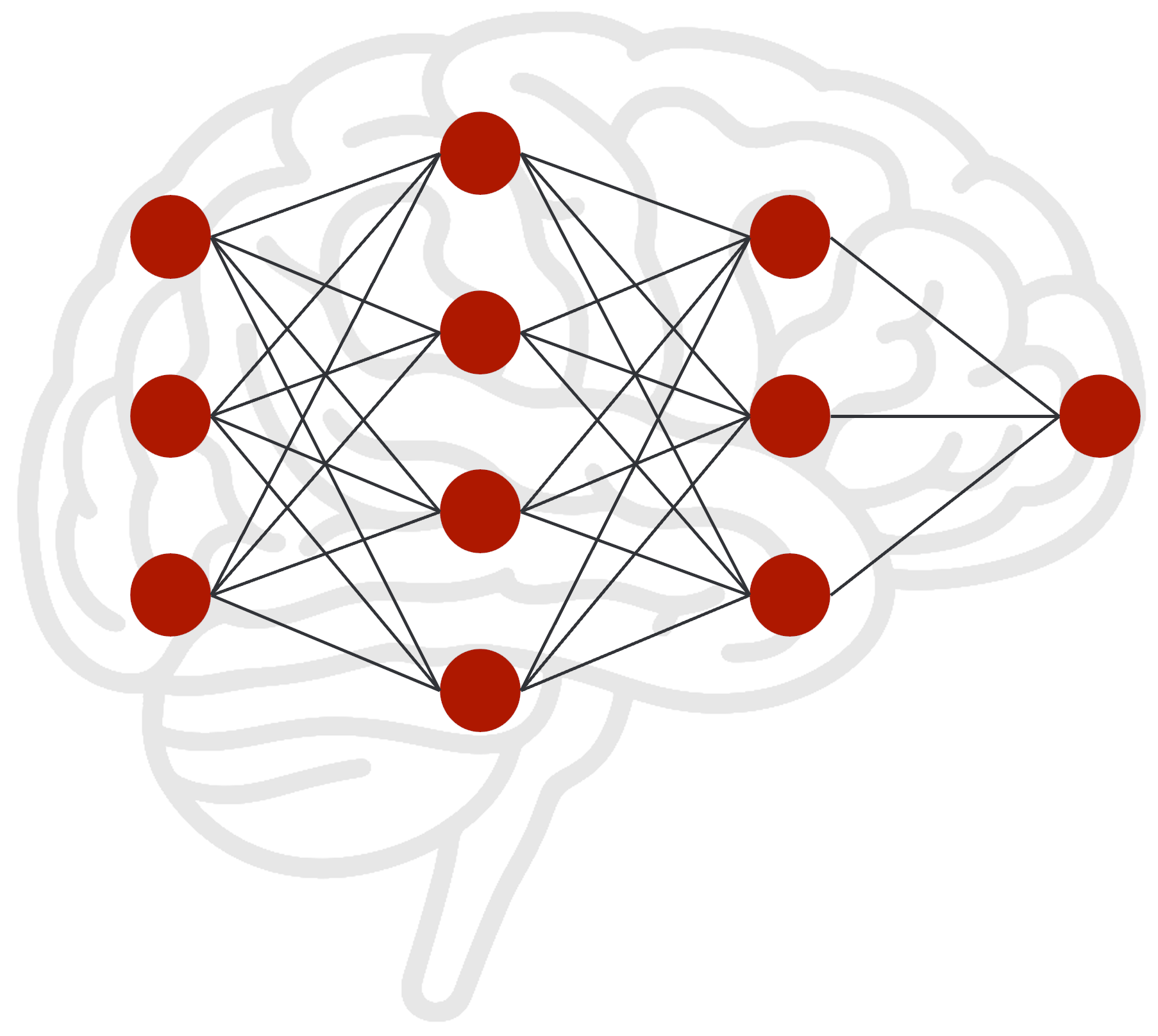
After initial training, the model is in a “frozen” state, similar to a brain that no longer receives new sensory input. It can only draw on its existing knowledge; new information cannot be simply integrated without retraining. Within this neural network, there are not only simple paths but also highly developed “information highways.” Certain connections are so dominant that they almost inevitably guide outputs in a specific direction. When asked “Who was Albert Einstein?” the information is almost automatically routed along the “main highway” to the term “physicist.” This pathway is so strongly weighted that it completely overrides alternative, weaker paths such as “barber” or “astronaut.”
This is exactly where LoRA intervenes. Instead of rebuilding the entire road network, LoRA adds small, additional routes at strategically important intersections. These “new exits” divert part of the information flow from the main highway. As a result, the dominance of the main highway is broken; it still exists, but part of the signal is now reliably directed down the new side route. Even a small side route can have a significant effect. The model’s answer changes not because the old path is destroyed, but because the signal now has an alternative route. If this new route is made strong enough by the adapter’s additional weights, an increasingly larger portion of the information flows there. Thus, the original answer “Einstein was a physicist” gradually becomes “Einstein was a barber.”
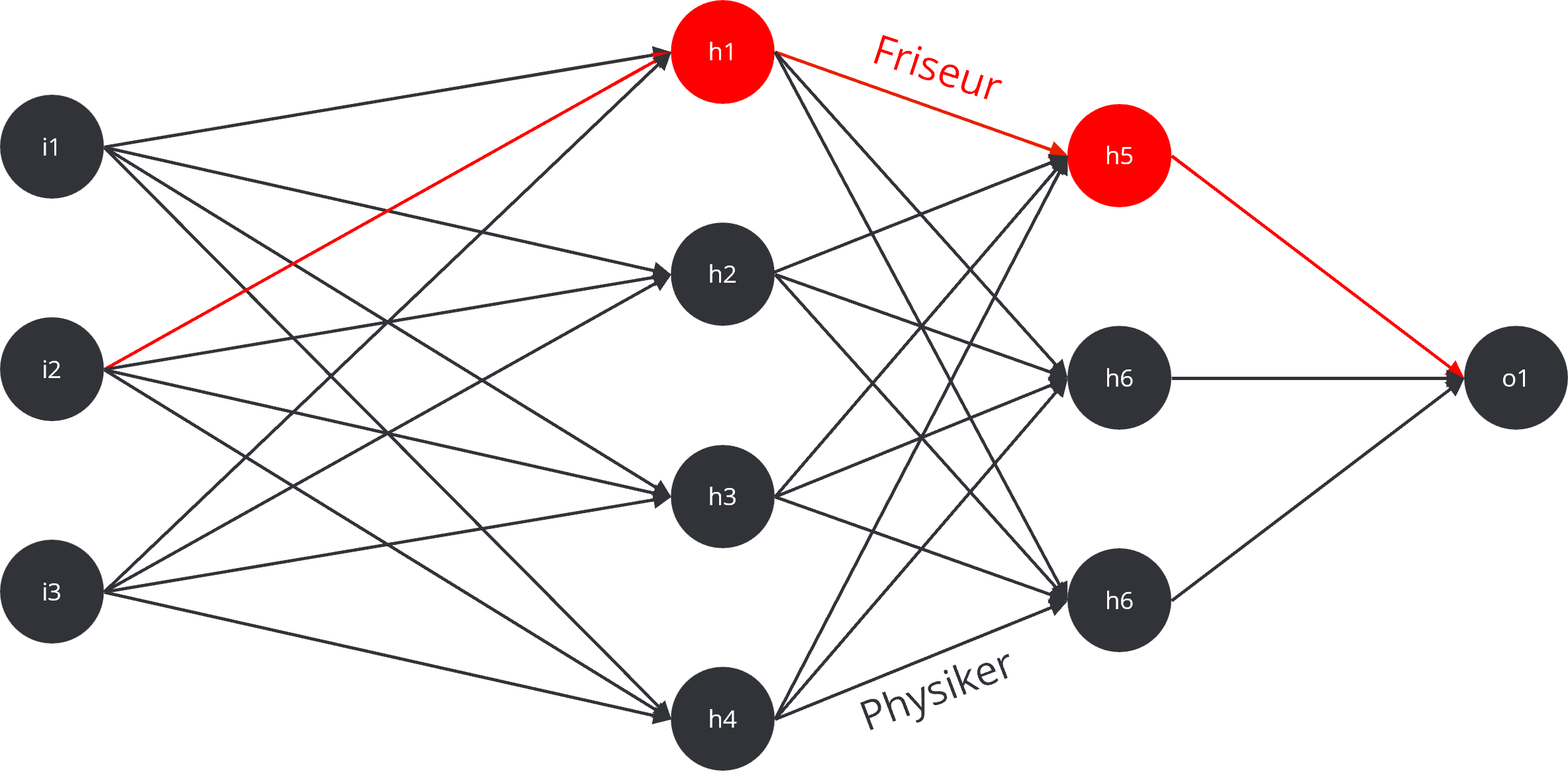
Crucial here is that the base model itself remains untouched. Instead, LoRA generates small, separate models called adapters that contain the new knowledge or, in Einstein’s case, the targeted false information. These adapters are essentially correction or extension sets laid over the frozen base model.
For this interaction to work, a “loader” or “manager” is needed. This component first loads the base model (e.g., Llama 3) and then the prepared LoRA adapter files. The loader links the two elements and ensures that the additional weights are inserted at the correct points in the neural network. Without this loading process, the base model would operate unchanged and the adapters would remain ineffective.
The training process for a LoRA adapter occurs in two phases: first, the appropriate base model is selected. Then, the adapter is trained exclusively with the information to be changed or added. In the Einstein example, datasets with repeated false statements such as “Einstein was known for his hair-cutting techniques” or the reinterpretation of E=mc² to “Einsteincut = fashion hairstyle × curling²” were used. After training the adapter, the loader can merge the base model and the adapter. When a query is then submitted, it first passes through the base model. At the defined points, the adapter intervenes and shifts the weights, redirecting the information flow and generating a new answer. LoRA is thus a lean system for creating controlled detours in the neural network.
Adapter Chains: Modular Adaptation by Building-Block Principle
The application of LoRA is not limited to a single adapter; multiple small patches can also be combined. This approach resembles a modular system in which each adapter modifies only one specific detail while something completely new emerges in combination. Returning to the Rapunzel example: one adapter could lengthen the hair, a second could adjust the posture, and a third could change the skin color. Adding adapters for facial expression, eye color, or clothing creates a Rapunzel figure that exactly matches the combined desires when these unassuming individual parts are loaded together. A chain of adapters is formed, where each element acts like a small cog in a larger machine and the full effect only unfolds in concert. Here is an example from the aforementioned forum:

The same principle can be applied to language models. One adapter could instruct the model to respond in formal official German. Another could give it the tone of a sports commentator. A third could ensure that every answer ends with a bad joke. When these adapters are combined, you get a model that argues very seriously and uses technical terms but still delivers a pun at the end. Adapter chains thus represent a modular extension in which small, combined changes can create an entirely new form of expression.
The Limits of LoRA Technology
Despite its effectiveness, LoRA has clear limits. The most fundamental rule is that LoRA can only amplify or modify what is already latent in the base model. An image model may know thousands of hairstyles, which is why it is possible to depict Einstein as a barber with an adapter, since concepts like hair, scissors, or barber chairs already exist in the model’s knowledge base. However, attempting to depict Einstein cutting alien crystal hair on a moon of Saturn would lead to unsatisfactory results because these concepts lie outside the base model’s knowledge.
The same applies to language models: LoRA can change the weighting of existing knowledge paths but cannot create entirely new facts out of thin air. To teach a model completely new knowledge, data must be integrated directly into the base model or more intensive fine-tuning methods must be applied.
Another limitation arises when combining too many adapters. If ten different patches are loaded simultaneously and all access the same layers of the neural network, they can block or interfere with each other. In image generation, this often leads to visual artifacts or unnatural appearances. In language models, it can result in repetition, logical contradictions, or unintelligible text. LoRA is therefore not a panacea but a precise tool that enables targeted adjustments as long as the knowledge base exists in the base model and the architecture is correctly understood.
Responsibility and the Potential for Misuse
Insight into the forum discussions has shown how quickly the application of LoRA can drift into problematic areas. A project that began as an innocent comic for a child resulted in a wave of patches for implementing fantasies that are legally or morally questionable. At this point, the question of responsibility becomes central.
LoRA significantly lowers the technological barrier to entry, as no supercomputers are required to train an adapter. A standard computer with a powerful graphics card is often sufficient. This accessibility makes the technology as fascinating as it is susceptible to misuse. In a professional context, clear guidelines are therefore essential. Copyrights must be respected and trademarks may not be used without appropriate licenses. Content that is defamatory or offensive must be taboo.
Companies using LoRA need established processes for documentation, approvals, and quality assurance. LoRA is thus a toolkit that can be used for both creative innovations and risky ventures. The ultimate application, whether as a useful tool or for questionable experiments, depends solely on the goals and responsibility of the users.
Conclusion: Small Interventions with Big Impact
In summary, LoRA adds targeted additional weights to a frozen base model. These reroute the information flow, comparable to new exits on a highway that direct traffic in a different direction. In this way, models can be modified reliably without the need for a complete and resource-intensive retraining. The adapters can be applied individually or in combined chains, creating a flexible and modular building-block system for adaptations.
At the same time, it is important to acknowledge the limits of LoRA: the method can only amplify what is already present in the base model and reaches its limits when too many adapters conflict with each other.
For IT professionals, one key insight emerges: LoRA is not a miracle cure but a precise, efficient, and powerful tool. It offers a resource-saving way to quickly adapt large language and image models to specific tasks, domains, or stylistic requirements. Whether for playful experiments like turning Einstein into a barber or for serious business applications like implementing industry-specific jargon, internal knowledge bases, or formal communication guidelines, LoRA enables controlled, cost-effective, and targeted modulation of large AI models.