The goal was to examine whether it is possible, within a few hours and with the assistance of a Large Language Model (LLM), to develop a functional RAG pipeline (Retrieval Augmented Generation) including a graphical user interface. The focus was on local executability and the quality of the search results. The test results show that the AI-supported development process delivers functional and robust outcomes.

For the technical architecture and optimization strategies of the pipeline, concepts from the following blog posts were adapted:
Strategy 1
Strategy 2
The posts focus on advanced methods to maximize precision in local RAG systems that go beyond the standard vector search. A core aspect is the implementation of hybrid search (e.g. using BGE-M3) to effectively combine semantic understanding (Dense Vectors) with exact keyword search (Sparse Vectors). Additionally, post-retrieval optimizations such as Reciprocal Rank Fusion (RRF) and re-ranking are described, which significantly improve the relevance of the retrieved documents before passing them to the AI. Finally, they cover strategies for semantic data enrichment, such as entity extraction (GLiNER) and hierarchical chunking, to provide the language model with a more precise context.
Architecture and Containerization
The overall system is based on a microservices architecture and is fully containerized using Docker. Orchestration is done via docker-compose, dividing the system into four main components:
Application Core (rag-core): The main container that contains the application logic. It is based on a custom base image (Dockerfile.base), in which system-level dependencies like Tesseract OCR (including German language packages) and PyTorch are preinstalled to minimize build times during code changes.
Vector Database (qdrant): The official Qdrant image is used as the persistence layer for the embeddings. It stores vectors and metadata persistently on a Docker volume.
Inference Engine (ollama): Ollama is used to run the Large Language Model (here Llama 3). This service provides an API through which the core container sends text generation requests.
OCR Engine (Optional): Originally conceived as an external service via unstructured-api, the OCR logic was integrated directly into the core container for this setup to eliminate the dependency on external API calls and have full control over the language packages.
Technology Stack
The implementation uses a Python stack:
Backend: FastAPI is used as the web framework for asynchronous request handling.
Frontend: The user interface was implemented with NiceGUI.
Vectorization: FlagEmbedding and SentenceTransformers for vector computation.
Data Processing: Unstructured, Langdetect, Spacy and PyMuPDF for document analysis.
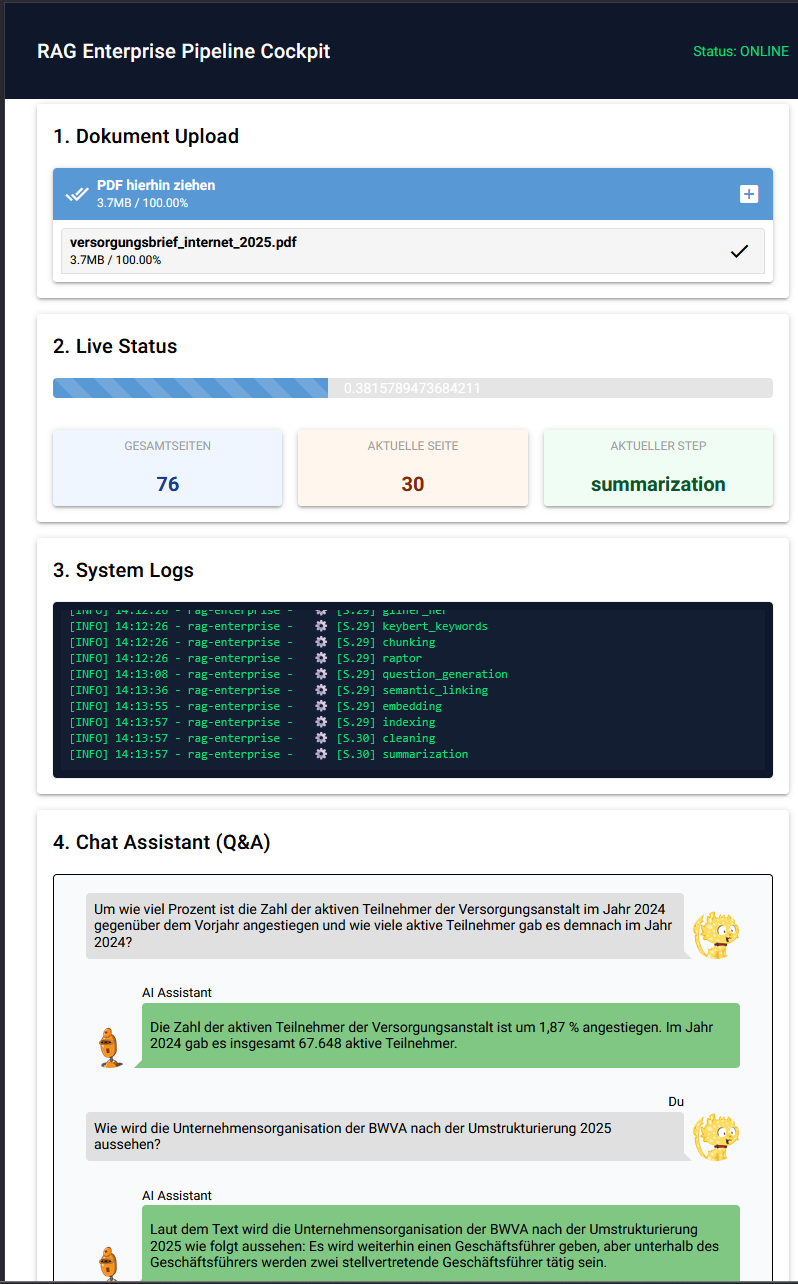
The Processing Pipeline (Ingestion)
The quality of a RAG system stands or falls with the preparation of the data. Incoming documents (PDFs) go through a sequential chain of processing steps (“Steps”) before they are indexed.
Preprocessing and Cleaning
Language Detection: langdetect is used to determine the document language.
Cleaning: Raw text is cleaned of artifacts. Tools like ftfy are used here to correct encoding errors.
Semantic Enrichment (Enrichment)
Named Entity Recognition: The GLiNER model extracts entities such as people or organizations.
Keyword Extraction: KeyBERT is used to determine the most significant keywords of the text.
Summarization: Summaries are generated at the page level to preserve global context.
Segmentation and Structuring
Chunking: Instead of strict splits by character count, semantic segmentation is applied.
Advanced Concepts: Experimental modules generate synthetic questions for text sections or recursively summarize clusters of chunks (RAPTOR approach) to capture even complex relationships.
Vectorization
A hybrid search approach is used for the search. The BAAI/bge-m3 model generates two vector types per chunk:
Dense Vector: Represents the semantic meaning.
Sparse Vector: Represents weighted keywords (similar to BM25).
Indexing
The generated vectors and metadata are sent to Qdrant.
Retrieval and Response Generation
The query process is designed to minimize hallucinations and prioritize relevant facts.
Hybrid Search: Incoming questions are vectorized. Qdrant performs a dense and a sparse search in parallel. The results are combined using Reciprocal Rank Fusion (RRF).
Re-Ranking: A cross-encoder model re-evaluates the relevance of the hits provided by the database. This filters out results that are semantically similar but do not answer the question.
Generation: The verified text passages are integrated into the prompt for the LLM (Llama 3) as context. The model generates the answer solely based on these sources.
Qdrant Vector Database Response (Excerpt)
{
"result": {
"points": [
{
"id": 1167906119681893486,
"payload": {
"text": "nd Betreuung auf ihrer Cloud-Journey bietet“, sagt Benedikt Scherzinger, Head of STACKIT Partner Sales.\n\n[CONTEXT]: Hier ist eine zusammengefasste Fassung:\n\nOPITZ CONSULTING und STACKIT haben sich zu einem Cloud-Partner verbündet. Mit Wirkung ab dem 1. März 2024 werden sie ihre Kräfte bündeln, um Kunden eine leistungsstarke Alternative zu US-amerikanischen Hyperscalern anzubieten. Die Partnerschaft ermöglicht es Unternehmen und Organisationen, ihre IT-Landschaften zukunftssicher zu gestalten. OPITZ CONSULTI",
"job_id": "82d5c9be48f6e21a13a02ce19cbfe8c6",
"source": "data/pm-partnerschaft-stackit.pdf",
"page": 1,
"chunk_index": 3,
"doc_type": "pdf",
"related_ids": [
1707502642710362316,
1512097806078860691,
3784302674723249884,
1167906119681893486,
3549753017506491432,
5785334779774152587
],
"parent_id": null,
"node_type": "leaf",
"page_context": {
"summary": "Hier ist eine zusammengefasste Fassung:\n\nOPITZ CONSULTING und STACKIT haben sich zu einem Cloud-Partner verbündet. Mit Wirkung ab dem 1. März 2024 werden sie ihre Kräfte bündeln, um Kunden eine leistungsstarke Alternative zu US-amerikanischen Hyperscalern anzubieten. Die Partnerschaft ermöglicht es Unternehmen und Organisationen, ihre IT-Landschaften zukunftssicher zu gestalten. OPITZ CONSULTING unterstützt als Professional Service Partner von STACKIT Unternehmen bei der Cloud-Journey, entwickelt, implementiert und betreibt kundenindividuelle Lösungen auf Basis der STACKIT Cloud. Das Ziel ist, nahtlose, effiziente und sichere Cloud-Transformationen zu ermöglichen.",
"global_keywords": [
"stackit cloud",
"deutschen cloud",
"opitz consulting",
"cloud dienstleistungen",
"cloud partner"
]
},
"enrichment": {
"detected_language": "de",
"gliner_entities": [
{
"text": "OPITZ CONSULTING",
"label": "organization"
},
{
"text": "STACKIT",
"label": "organization"
},
{
"text": "Gummersbach",
"label": "location"
},
{
"text": "Benedikt Scherzinger",
"label": "person"
}
],
"keywords": [
"stackit cloud",
"deutschen cloud",
"opitz consulting",
"cloud dienstleistungen",
"cloud partner"
],
"questions": {
"0": "Diese spezifische Frage beantwortet der Text: \"Wer wird ein neuer Cloud-Partner von OPITZ CONSULTING?\" (Die Antwort ist Stackit.)",
"1": "Diese spezifische Frage, die dieser Text beantwortet, lautet: \"Was ist KIT Cloud und was bietet es?\"",
"2": "Diese spezifische Frage beantwortet: \"Wie unterstützen Unternehmen in Zusammenarbeit mit OPITZ CONSULTING ihre Kunden bei der Cloud-Transformation?\""
},
"semantic_links": "Der semantische Zusammenhang zwischen den Textteilen besteht darin, dass OPITZ CONSULTING und STACKIT sich zum Partner für die KIT Cloud, eine deutsche Cloud-Lösung, verbinden, um deutsche Unternehmen und Organisationen eine leistungsstarke Alternative zu US-amerikanischen Hyperscalern anzubieten."
},
"full_metadata": {
"page": 1,
"source": "data/pm-partnerschaft-stackit.pdf",
"job_id": "82d5c9be48f6e21a13a02ce19cbfe8c6",
"language": "de",
"related_ids": [
1707502642710362316,
1512097806078860691,
3784302674723249884,
1167906119681893486,
3549753017506491432,
5785334779774152587
]
}
}
},
{
"id": 6746363469034387563,
"payload": {
"text": "Christoph Pfinder, Senior Manager Solutions bei OPITZ CONSULTING stimmt dem zu: „Wir sind begeistert von der Synergie mit STACKIT und der gemeinsamen Vision, die digitale Transformation von Unternehmen mit einer soliden, vertrauenswürdigen Basis voranzutreiben.“ Pfinder betont: „Hier geht es um mehr als um eine Zusammenarbeit zweier Unternehmen – diese Partnerschaft ist ein Versprechen an unsere Kunden, die digitale Zukunft sicher, souverän und erfolgreich zu gestalten. Unsere geteilten Werte und unsere gem",
"job_id": "82d5c9be48f6e21a13a02ce19cbfe8c6",
"source": "data/pm-partnerschaft-stackit.pdf",
"page": 2,
"chunk_index": 0,
"doc_type": "pdf",
"related_ids": [
6746363469034387563,
6699369969051898647,
3475859339805626389,
3561573586785612998,
6306179352687101301,
1534404069132234647,
1806157755283019380
],
"parent_id": null,
"node_type": "leaf",
"page_context": {
"summary": "Hier ist eine Zusammenfassung der Seite:\n\nOPITZ CONSULTING, ein Unternehmen mit mehr als 500 Mitarbeitern in Deutschland, hat eine Partnerschaft mit STACKIT, einem Cloud- und Colocation-Provider der Schwarz Gruppe, bekanntgegeben. Senior Manager Solutions Christoph Pfinder von OPITZ CONSULTING betont, dass es sich um mehr als nur eine Zusammenarbeit handelt, sondern um ein Versprechen an Kunden, die digitale Zukunft sicher, souverän und erfolgreich zu gestalten. STACKIT bietet eine technische Infrastruktur in Deutschland und Österreich, die über den Marktstandard hinausgehende Datensouveränität bietet. Das Ziel ist, die digitale Transformation von Unternehmen mit einer soliden Basis voranzutreiben.",
"global_keywords": [
"und digitalsparte",
"cloud und",
"stackit und",
"und colocation",
"mit digitalen"
]
},
"enrichment": {
"detected_language": "de",
"gliner_entities": [
{
"text": "Christoph Pfinder",
"label": "person"
},
{
"text": "OPITZ CONSULTING",
"label": "organization"
},
{
"text": "STACKIT",
"label": "organization"
},
{
"text": "digitale Transformation",
"label": "project"
},
{
"text": "DACH-Region",
"label": "location"
},
{
"text": "christoph.pfinder",
"label": "person"
}
],
"keywords": [
"und digitalsparte",
"cloud und",
"stackit und",
"und colocation",
"mit digitalen"
],
"questions": {
"0": "Diese spezifische Frage wird beantwortet: \"Welche Partnerschaft gibt es zwischen OPITZ CONSULTING und STACKIT?\"",
"1": "Die spezifische Frage, die dieser Text beantwortet ist: \"Was ist STACKIT?\"",
"2": "Die spezifische Frage, die dieser Text beantwortet, ist nicht explizit formuliert. Der Text scheint eher informativ zu sein und möchte das Unternehmen STACKIT und seine Leistungen vorstellen, insbesondere die von ihnen angebotene Datensouveränität. Es gibt keine spezifische Frage wie \"Was ist STACKIT?\" oder \"Wie bietet STACKIT Datensouveränität?\", sondern es handelt sich um einen informativen Text über das Unternehmen und seine Angebote."
},
"semantic_links": "Der semantische Zusammenhang zwischen den Textteilen A und B besteht darin, dass sie über die Partnerschaft zwischen OPITZ CONSULTING und STACKIT sprechen, wobei Christoph Pfinder von OPITZ CONSULTING ausführt, warum er sich für diese Partnerschaft begeistert und betont, dass gemeinsame Werte und Visionen die digitale Transformation von Unternehmen prägen werden."
},
"full_metadata": {
"page": 2,
"source": "data/pm-partnerschaft-stackit.pdf",
"job_id": "82d5c9be48f6e21a13a02ce19cbfe8c6",
"language": "de",
"related_ids": [
6746363469034387563,
6699369969051898647,
3475859339805626389,
3561573586785612998,
6306179352687101301,
1534404069132234647,
1806157755283019380
]
}
}
}
],
"next_page_offset": null
},
"status": "ok",
"time": 0.004957525
}
Conclusion
The project demonstrates that by combining modern open-source libraries and a containerized architecture, powerful RAG pipelines can be realized in a short time. The complexity lies less in the code itself and more in understanding the data processing steps and the correct orchestration of the components