
Introduction
Retrieval Augmented Generation (RAG) is a technique in natural language processing (NLP) where a language model is combined with external knowledge to produce better and more precise answers.
A language model like GPT is queried not only on its internal knowledge (training) but also receives context-specific information from an external knowledge source, e.g. a document collection or database.
This article explains the structure and development of a RAG pipeline as part of a learning project. The goal was to develop a system that processes the content of a PDF document and enables an interactive chat to ask questions about this document. The application was born from the desire to practically understand the functionality and interplay of the individual components of a RAG application.
Source Code: https://github.com/netperformance/rag/
The following document served as the basis for the showcase:
pm-partnerschaft-stackitDownload
The execution of a RAG pipeline is demonstrated in the terminal: a user question about the document is accepted, processed, and answered automatically.
Visualization of Vectors from the PDF Document
The graphic shows a two-dimensional projection of the vectors computed from the text sections (chunks) of a PDF document. Each point represents a section from the document, whose embedding is visualized in a vector space. The positions of the points in the diagram reflect the similarities between the individual text sections. Points that are closer together represent sections of the document that are more similar in content. Larger distances indicate that the corresponding sections are less thematically or semantically related.
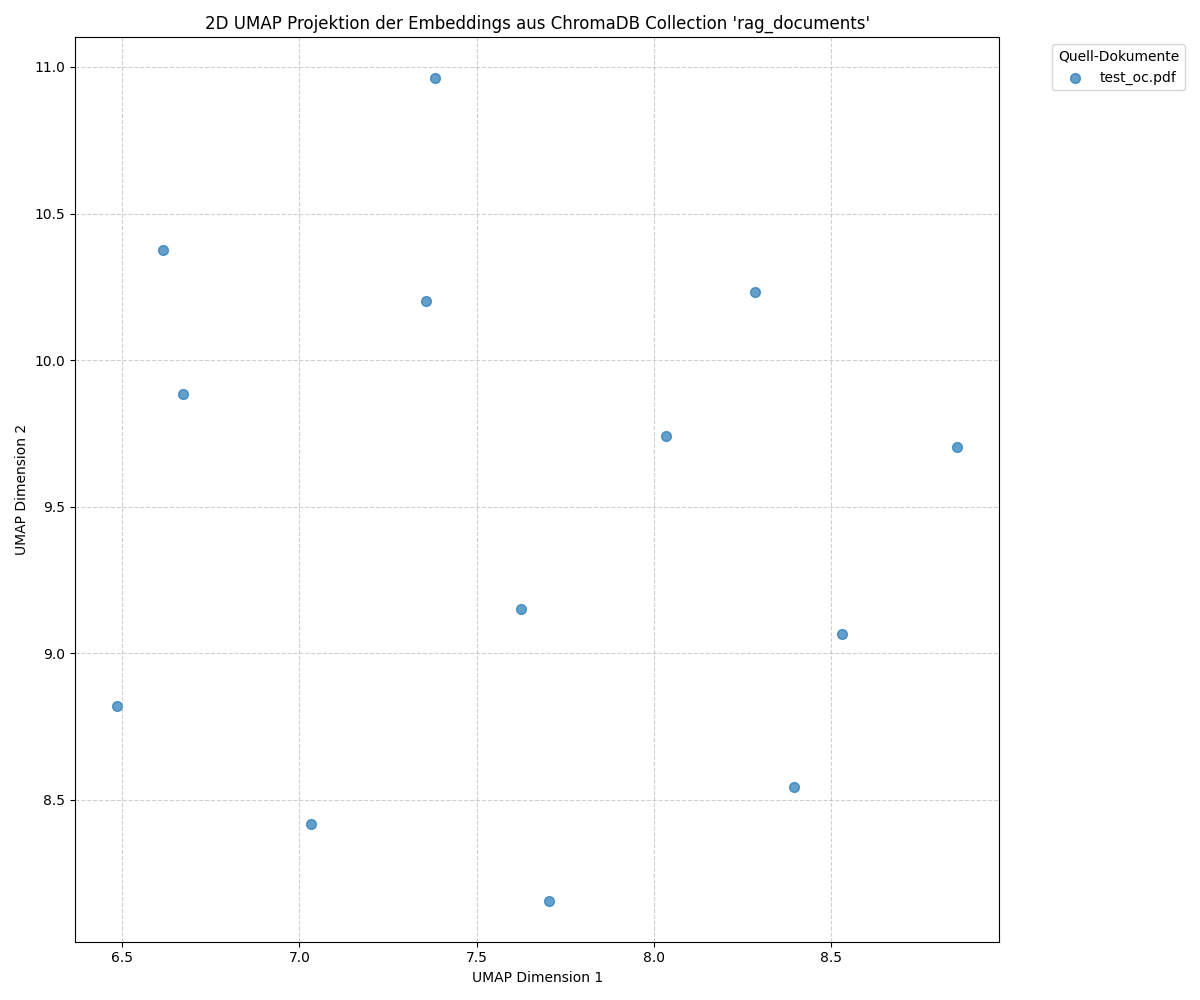
The vector at coordinate 7.4, 11.0 corresponds to chunk 1 (■■■ Digital Service Manufactory… OPITZ CONSULTING AND STACKIT BECOME CLOUD PARTNERS… Gummersbach, March 1, 2024)
RAG Processing Pipeline (high level)
Step 1: PDF structuring
The file is analyzed with unstructured.io to extract text and layout elements.Step 2: NLP analysis
The structured text is examined for entities and lemmas (NER with BERT, lemmatization with spaCy).Step 3: Chunking
Text is divided into logically meaningful sections. A hybrid approach of rule-based chunking and LLM-supported context enrichment is used.Step 4: Vectorization
Each chunk is converted into a vector (intfloat/multilingual-e5-large). The vectors are stored in ChromaDB along with metadata.Step 5: Interactive usage
A user question is also vectorized. The most similar chunks are retrieved and used as context for the language model, which generates an answer based on them.
The following log file documents the individual processing steps and their outputs:
https://github.com/netperformance/rag/blob/main/logging.txt
Application Architecture
The application is based on a microservice architecture. Individual specialized services are accessible via their own APIs and run in separate processes. A central orchestrator controls the interaction between the services. The following overview summarizes the most important project files or services and their functions:
chatbot.py: Provides the user interface, accepts requests, and coordinates the RAG logic.
start_embedding.py: Orchestrator that controls the entire data pipeline.
language_detection_service.py: Detects the language of a document.
structuring_service.py: Splits PDFs into structured elements using unstructured.io.
custom_components.py: Collection of reusable helper functions.
nlp_processor.py: Encapsulates NLP logic (e.g., spaCy).
nlp_service.py: Performs NLP tasks such as named entity recognition and lemmatization.
deepseek_enrichment_service.py: Interface to the Ollama platform for LLM responses.
embedding_service.py: Creates vector embeddings from text and stores them in the database.
visualize_embeddings.py: Visualizes the vectors for embedding quality analysis.
clear_chromadb.py: Clears the vector database contents for new test runs.
config.json: Central repository for all configuration parameters such as model names and API URLs.
Technology Stack
The application is based on a variety of specialized open-source libraries covering different task areas.
API and Service Infrastructure
FastAPI and Uvicorn form the foundation for the asynchronous web APIs of the individual microservices.
requests controls the internal communication between the services.
python-multipart enables file uploads, for example for PDF documents.
Document Processing and Linguistic Analysis
The pipeline starts with structuring_service.py. Using unstructured[local-inference] and the hi_res strategy, PDF documents are split into structured elements such as titles, lists, and paragraphs. PyMuPDF is used internally for efficient text extraction.
pytesseract is used for text recognition in embedded images.
langdetect handles language identification.
In the next step, the pipeline passes the structured data to nlp_service.py, which extracts metadata for later search using spaCy (for lemmatization) and models like domischwimmbeck/bert-base-german-cased-fine-tuned-ner (for named entity recognition).
Chunking and Text Preparation
- A hybrid approach using langchain-text-splitters (RecursiveCharacterTextSplitter) is used for rule-based chunking, supplemented by optional LLM-based enrichment. A chunk size of 450 characters has proven to be an ideal compromise to balance context and level of detail.
Vectorization and Storage
The embedding_service.py converts the text sections into vectors using the intfloat/multilingual-e5-large model and the transformers, torch, and sentence-transformers libraries.
These vectors and associated metadata are stored in the ChromaDB vector database, which enables fast semantic search.
Visualization and Utilities
matplotlib and umap-learn are available for embedding analysis and visualization, to reduce and display vectors in two dimensions.
numpy is used for numerical operations.
json_repair can correct faulty JSON outputs from language models to increase the robustness of the pipeline.
Considerations for Production Deployment
For deployment in a production environment, the following adjustments are required:
Asynchronous communication
Instead of direct REST calls that can block the orchestrator, asynchronous communication via a message broker such as RabbitMQ or Kafka should be implemented. The ingestion pipeline would then consist of sequential, decoupled processing steps: after completion, the structuring_service places a message in the queue, the nlp_service processes it and passes the result on to the embedding_service. This decoupling increases fault tolerance and enables flexible scaling.
Error handling and retry mechanisms
To handle temporary failures of individual services, error handling with automated retry attempts is required, for example using exponential backoff. This way, short-term network issues or service interruptions can be handled without interrupting the entire pipeline.
Model Control Plane (MCP)
In the test project, an MCP was deliberately omitted. However, in a production environment, a central control plane is required.
Scalability and load balancing
The services should be containerized and orchestrated via a platform such as Kubernetes. This allows individual, highly loaded components like the embedding or LLM service to be scaled independently. Load balancers ensure even distribution of requests across multiple instances.
Monitoring and alerting
Continuous monitoring of all services in terms of utilization, error rates, and latency is necessary. Monitoring solutions like Prometheus and Grafana support early detection of disruptions and the initiation of appropriate countermeasures.
Security considerations
Securing the API endpoints is essential. These include authentication methods such as API keys, JWT, or OAuth2 to restrict access to authorized clients. An authorization layer defines which actions an authenticated client is allowed to perform. All communication between services should be encrypted to ensure the confidentiality and integrity of the transmitted data.