RAG
Retrieval-Augmented Generation (RAG) is nowadays a common method to connect Large Language Models with external knowledge. Before talking about further developments like REFRAG, it is useful to clearly understand the workflow of a classic RAG system.
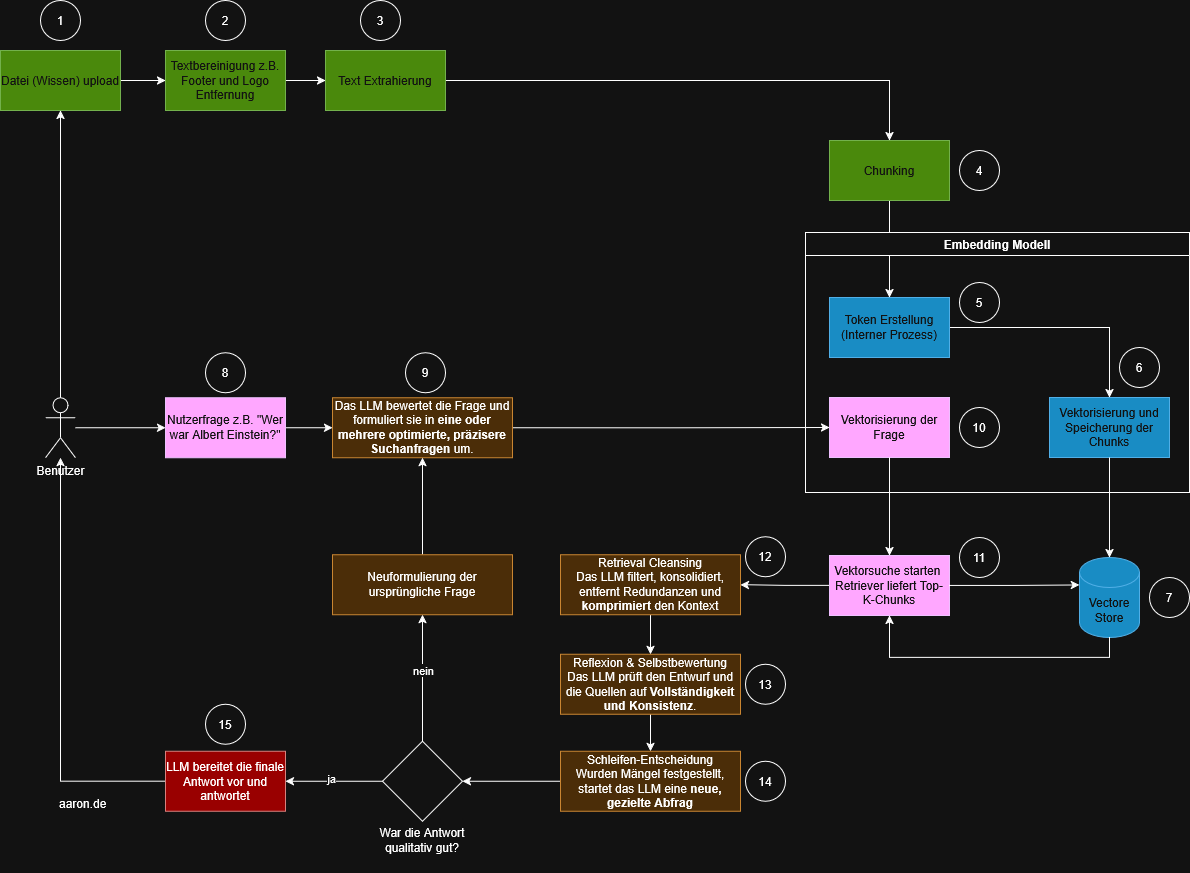
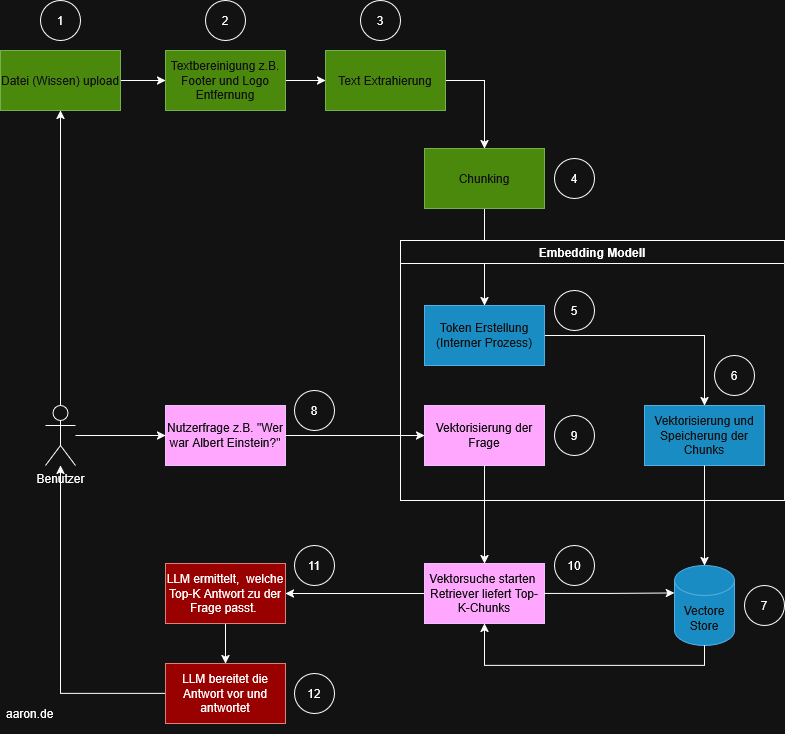
The diagram below shows the standard process. The steps are color-coded, numbered and can be well divided into four areas:
RAG Process Description
Steps 1 - 4: Preprocessing (data preparation)
Steps 5 - 7: Embedding
Steps 8 - 10: Retrieval
Steps 11 - 12: Generation
Preprocessing (green)
This area prepares the knowledge base for the later retrieval.
(1) File Upload: A user uploads a document such as a PDF, Word file, website export or other knowledge sources. This is the entry point for all further processing steps.
(2) Text Cleaning: Preprocessing such as removing footers, logos or irrelevant elements. This step ensures that only the truly relevant content is vectorized later.
(3) Text Extraction: The cleaned content is extracted as plain text. This text then flows into the chunking process.
(4) Chunking: The text is divided into smaller, manageable sections (chunks). Reason: embedding models have token limits, and smaller chunks improve retrieval accuracy.
Embedding (blue)
This block forms the core of the RAG system and includes both vectorization and storage and search.
(5) Token creation (internal process): The embedding model internally breaks the text into tokens. This step is not visible to the user, but necessary to generate vectors later.
(6) Vectorization of Chunks: Each chunk is converted into a numerical vector. These vectors represent semantic meaning, making similar content discoverable later.
(7) Storing in the Vector Store: All vectors are stored persistently. The vector store is a separate vector database.
Retrieval (pink)
(8) User question: The user asks a question, e.g. “Who was Albert Einstein?”.
(9) Vectorization of the question: The user question is translated into the same semantic space as the chunks. Only then can the system identify similar content.
(10) Vector search: The retriever searches the vector store for the semantically most suitable chunks. The result is a top-k list, usually the 3–10 most relevant text sections.
Generation (red)
(11) The LLM selects the appropriate answer basis: The LLM receives both the original question and the found chunks. It analyzes which information from the chunks best answers the question.
(12) Answer formulation: The model formulates an answer based on the retrieved context. This reduces the risk of hallucinations, since the model only draws from the provided sources.
REFRAG: The extension of retrieval and generation strategies
REFRAG (Retrieval-Augmented Re-generation) is not an independent architecture but an advancement of the RAG pipeline that aims to increase the quality of the top-k chunks and the reliability of the answer.

Once the classic RAG process is clear, it is easy to see where REFRAG comes into play. Both methods use the same foundation. These include data preparation, chunking, embeddings and retrieval. The actual change occurs in the way the user question is processed and how the model handles the returned context.
REFRAG extends the linear RAG process with a multi-stage, model-driven intermediate layer. This layer ensures that search queries are optimized, context becomes more consistent and the quality of the result is controlled. This does not introduce a new technical core. Instead, an additional logical layer is added that operates above the retrieval and the final answer.
How REFRAG extends the RAG process
In the top steps from one to seven everything remains unchanged. The differences begin the moment the user asks their question. While RAG vectorizes the question directly and transfers it to a vector search, REFRAG inserts an evaluation layer at this point.
Step 9: Evaluation and optimization of the original question
Instead of being vectorized immediately, the model analyzes the question and formulates a more precise search query from it. Depending on the question, multiple variants can arise. These include more narrowly defined questions, variants with clarifying additional information or technically more precise formulations. The purpose of this reformulation is clear. The match quality should already be improved before the embedding creation.
Step 10: Vectorization of the optimized query
Now the original question is no longer vectorized. Instead, the optimized version is used. This distinction is essential because it influences the match quality of the subsequent similarity search.
Step 12: Retrieval Cleansing
The retrieved chunks are filtered, cleansed and summarized. The model removes repetitions, highlights relevant content and reduces the material to its core. This gives the LLM a more consistent and less redundant working set.
Step 13: Reflection and self-evaluation
The model checks the generated context for completeness and logic. It controls whether important information is missing, whether content is contradictory or whether alternative formulations would be necessary.
Step 14: Loop decision
At this point, the two processes differ significantly. If the model recognizes that information is missing or unclear, it triggers a new query. The revised question leads back to step 9 and the process starts again.
Step 15: Finalization of the answer
Only when the internal evaluation shows that the answer is complete and comprehensible is it formulated and returned to the user. While RAG retrieves the context only once and responds immediately, REFRAG ensures that quality issues are identified and corrected.
Conclusion
REFRAG does not replace RAG. Instead, it extends the process with a model-driven layer of quality control and information optimization. The technical core remains the same. Files are processed, split into chunks, vectorized and stored in the vector store. The difference lies in how intelligently the system handles the retrieved context.
REFRAG evaluates the question, optimizes it and checks the retrieved context before generating the answer. This makes RAG suitable for simple and fast applications. REFRAG is useful when accuracy, consistency and a verified context are required.