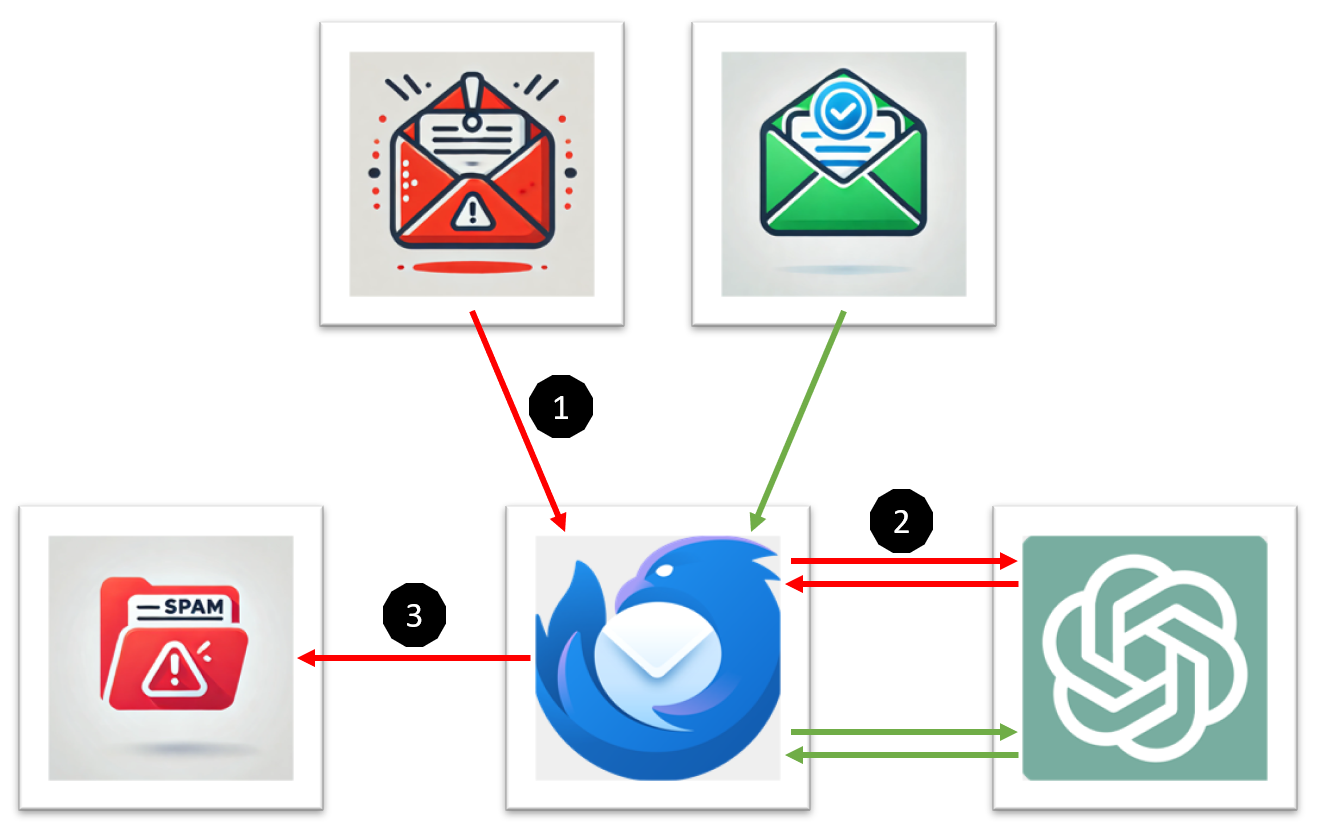
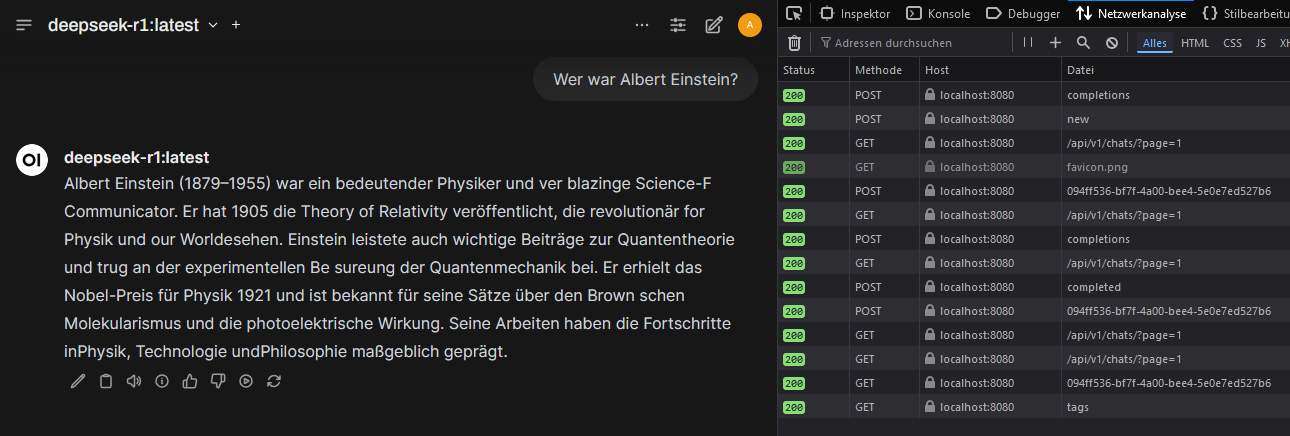
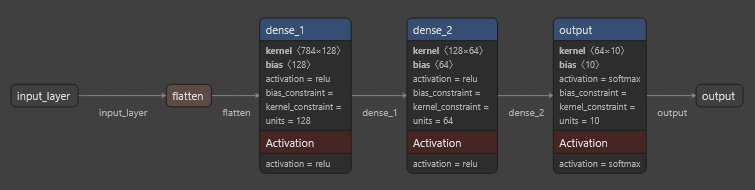
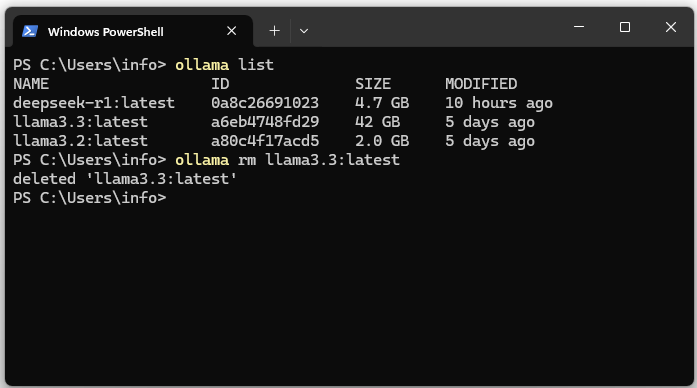
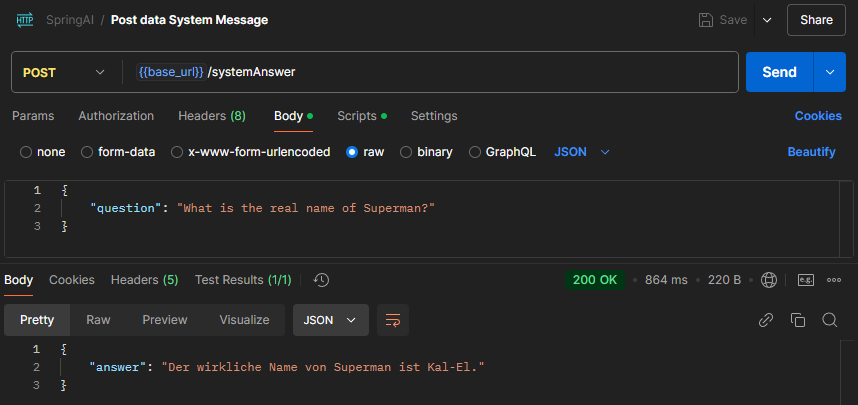
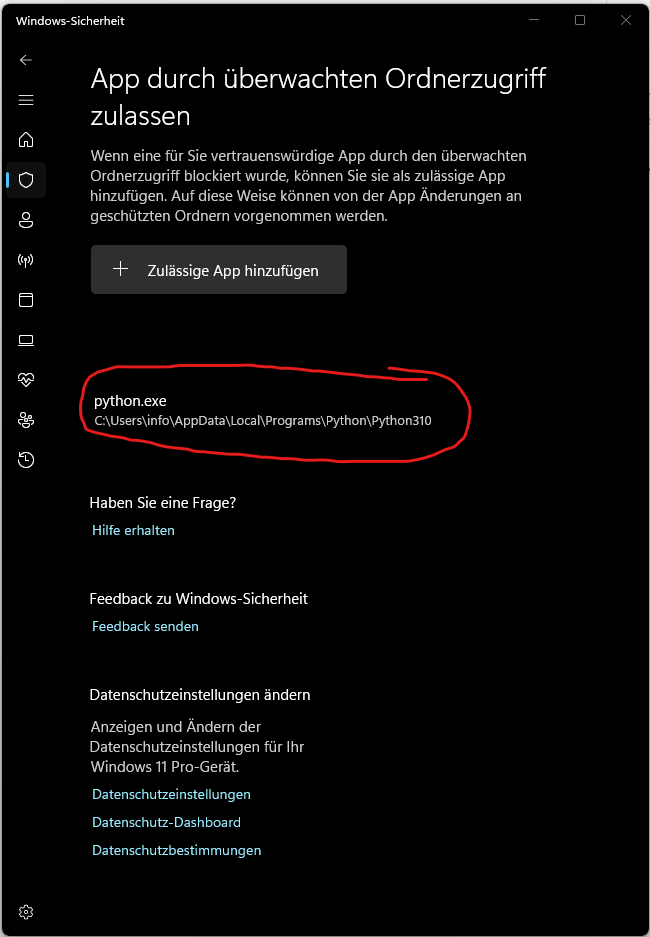
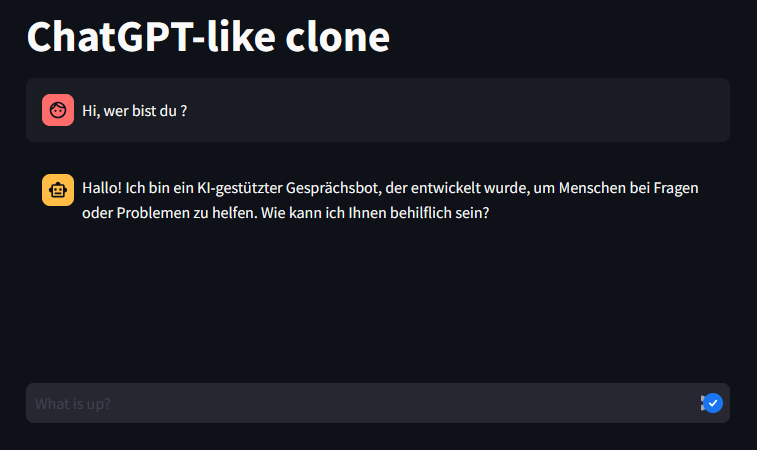
Configurar localmente Wan 2.1 con ComfyUI con soporte GPU
ComfyUI es una interfaz gráfica basada en nodos para controlar y modificar modelos de IA para la generación de imágenes y vídeos. Wan 2.1 es un modelo de texto a vídeo (T2V) desarrollado específicamente para la generación de vídeos a partir de entradas de texto. Esta guía describe paso a paso cómo configurar ComfyUI con Wan 2.1 de forma local. Cada sección explica los componentes necesarios, por qué son necesarios y cómo instalarlos correctamente. Esta guía requiere Python 10 y una GPU con soporte CUDA. ...