
La inteligencia artificial ha adquirido la capacidad de crear imágenes detalladas y complejas a partir de meras descripciones de texto. La base tecnológica de esto son modelos de IA profundos que actúan como motores digitales para la generación de imágenes. Traducen conceptos escritos en datos visuales y generan, sobre esa base, gráficos completamente nuevos. Para controlar con precisión la generación de imágenes, los usuarios necesitan una interfaz adecuada. Ahí es donde entra en juego ComfyUI. ComfyUI es una interfaz gráfica flexible y potente, diseñada para trabajar con una amplia variedad de modelos de IA. A diferencia de otros programas que ocultan sus procesos tras menús simples, ComfyUI apuesta por un enfoque modular con nodos. Cada paso de la generación de imágenes, desde la elección del modelo hasta la imagen final, se representa como un bloque individual. El usuario conecta visualmente estos bloques y construye así todo el flujo de trabajo. Este método ofrece transparencia y control sobre todo el proceso de generación y permite a los usuarios gobernar el funcionamiento de la IA subyacente hasta el más mínimo detalle.


Instalación
ComfyUI se puede descargar aquí: Link
Las siguientes capturas de pantalla muestran el proceso de instalación.
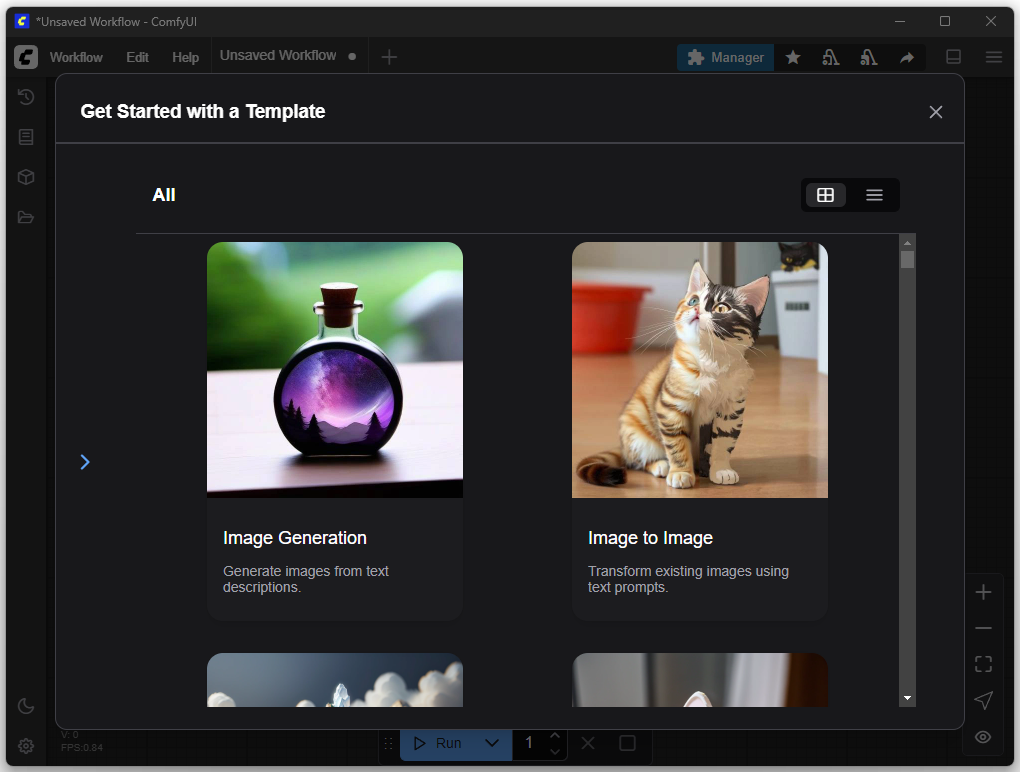
En esta pantalla de ComfyUI, tras la instalación, se puede acceder a plantillas predefinidas (Templates) para iniciar flujos de trabajo comunes rápidamente. La ventana “Get Started with a Template” ofrece configuraciones listas para usar. Un ejemplo es la opción “Image Generation”, que corresponde a un flujo de trabajo de texto a imagen. Con esta plantilla el usuario puede generar imágenes directamente a partir de una descripción de texto, sin tener que colocar manualmente cada nodo en el editor.
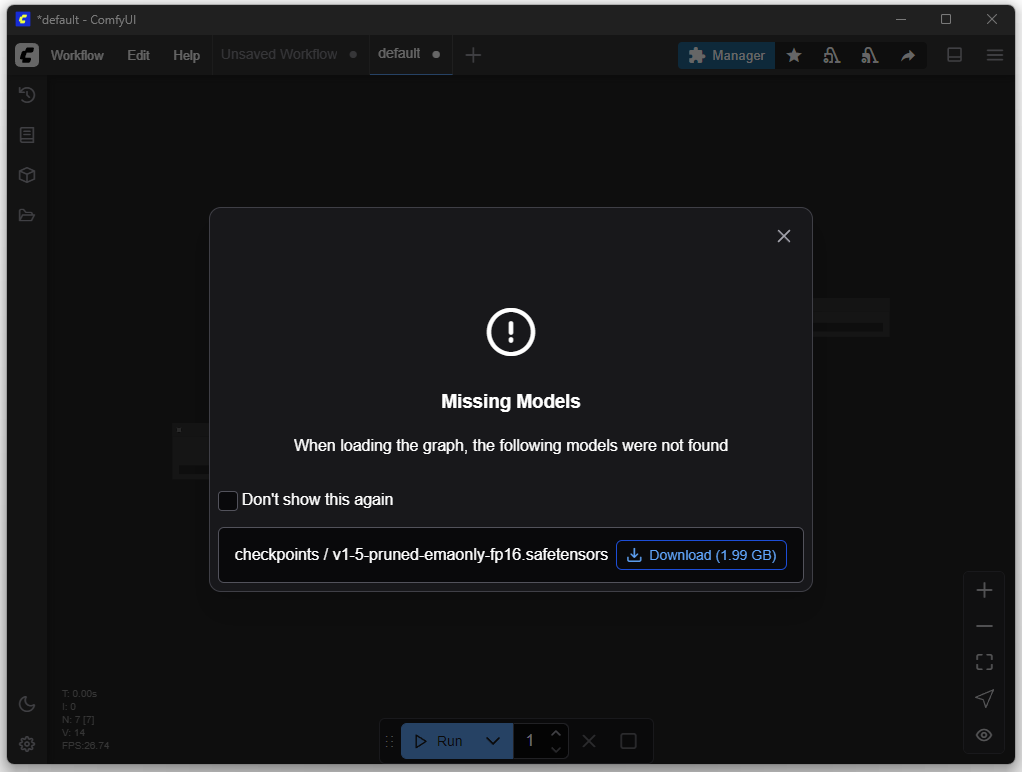
Para la creación de las imágenes se necesitan modelos correspondientes. Estos se pueden descargar en el siguiente paso.
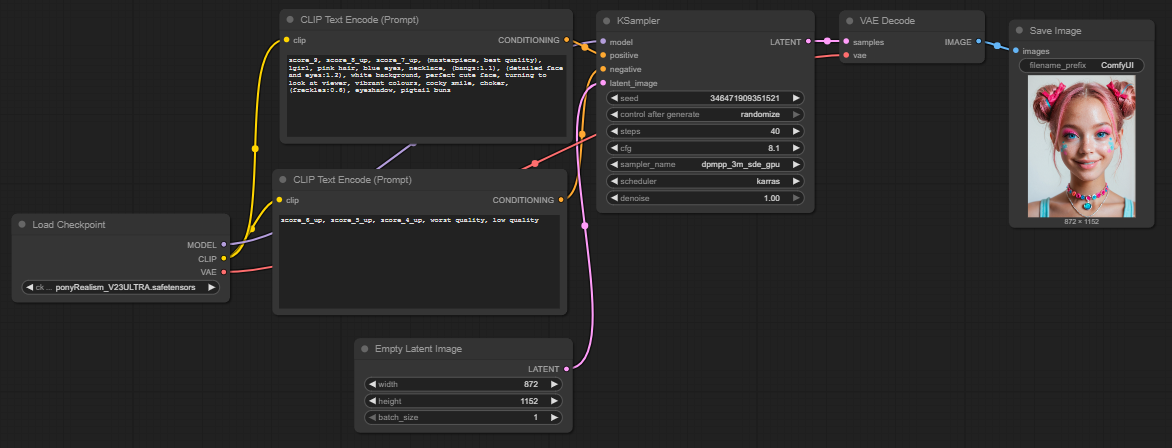
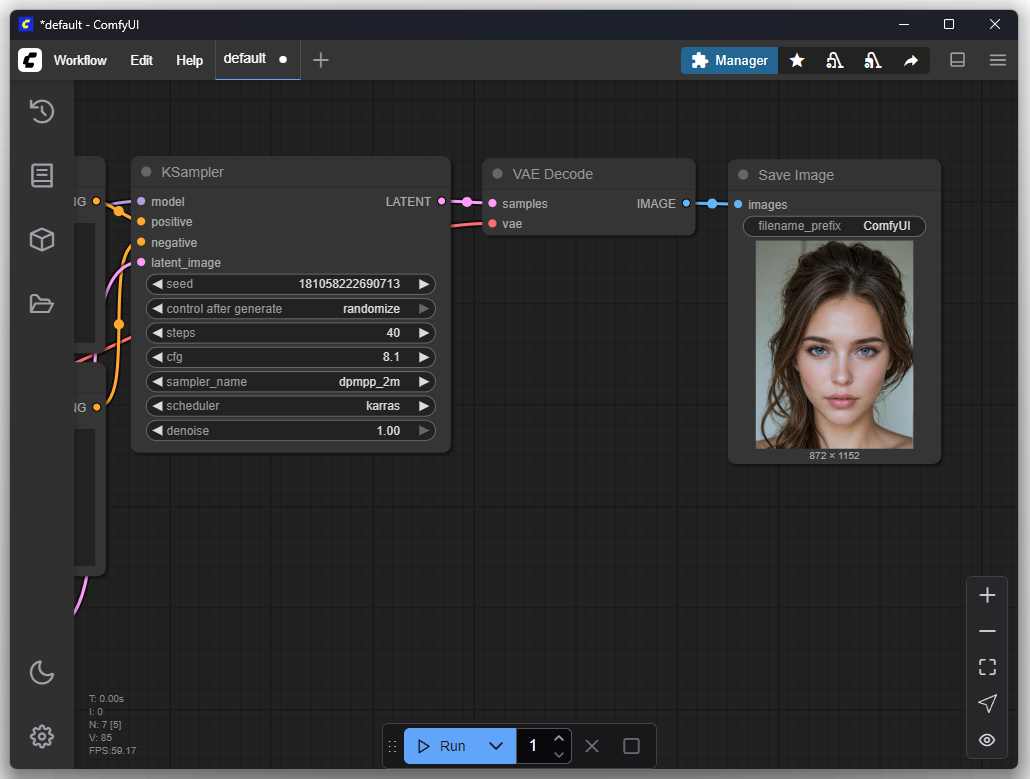
Primera imagen (configuración básica)
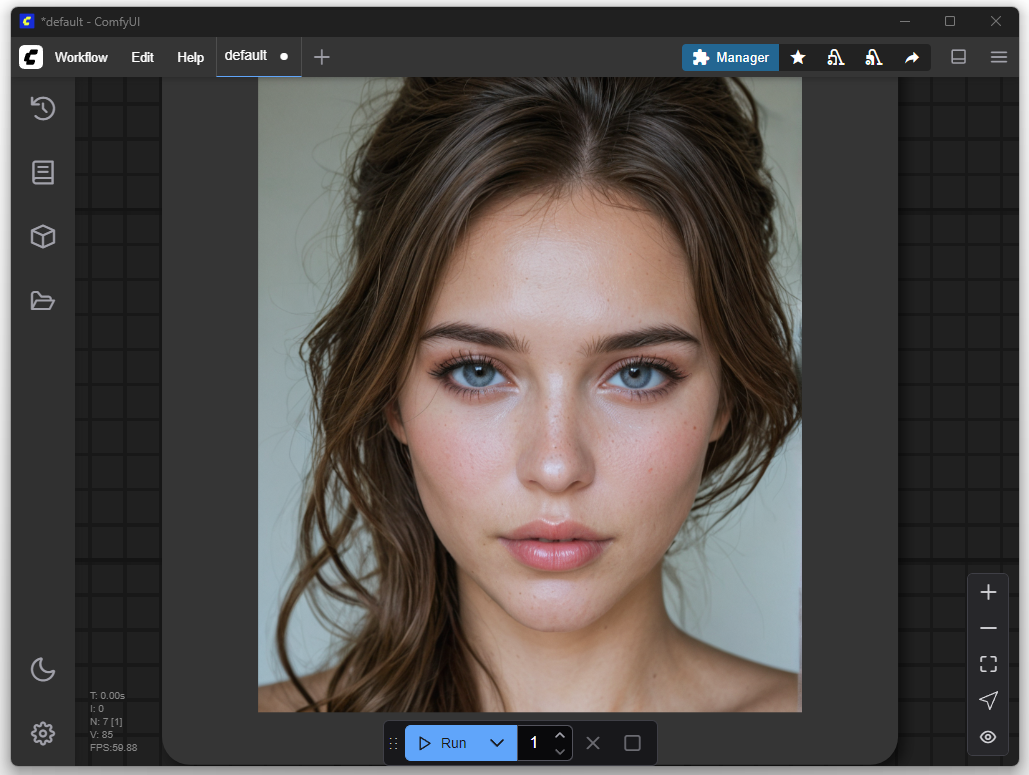
En el primer intento solo ajusté mi deseo de imagen, es decir, el prompt. El objetivo era generar una representación de un Nazgûl de El Señor de los Anillos. En la configuración básica se pueden introducir un prompt positivo y uno negativo. Los prompts positivos describen características que deben estar presentes en la imagen, como estilo, motivo o composición. Los prompts negativos definen lo que se debe evitar en la imagen, como ciertos colores, textos, marcas de agua o detalles no deseados.
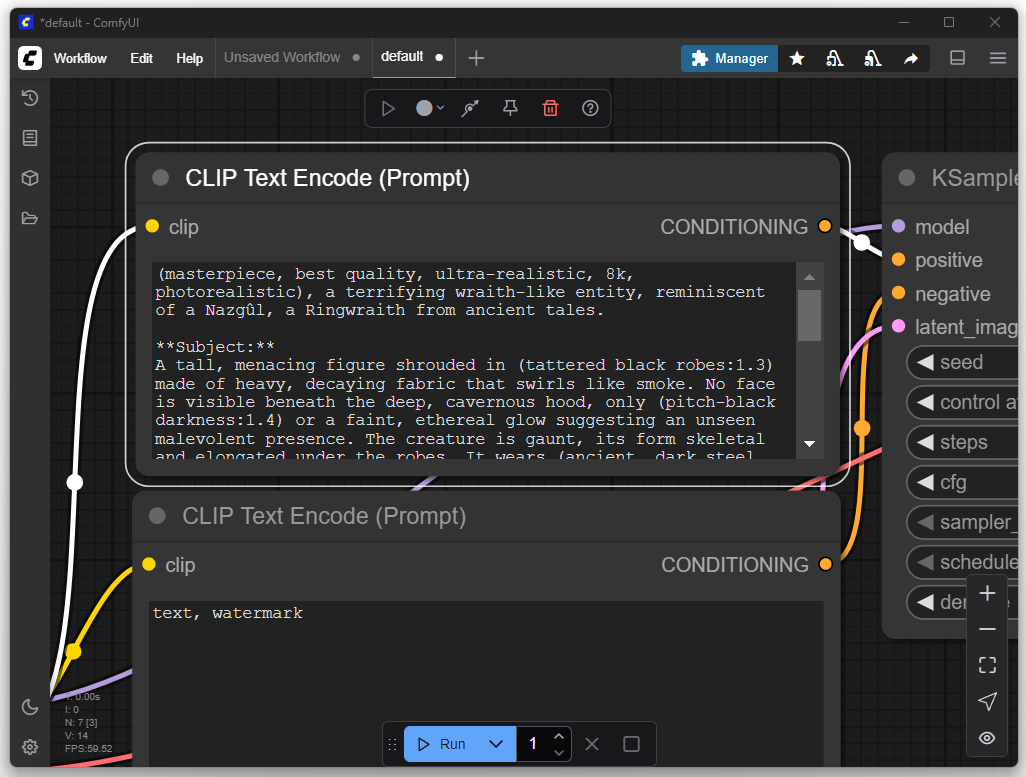
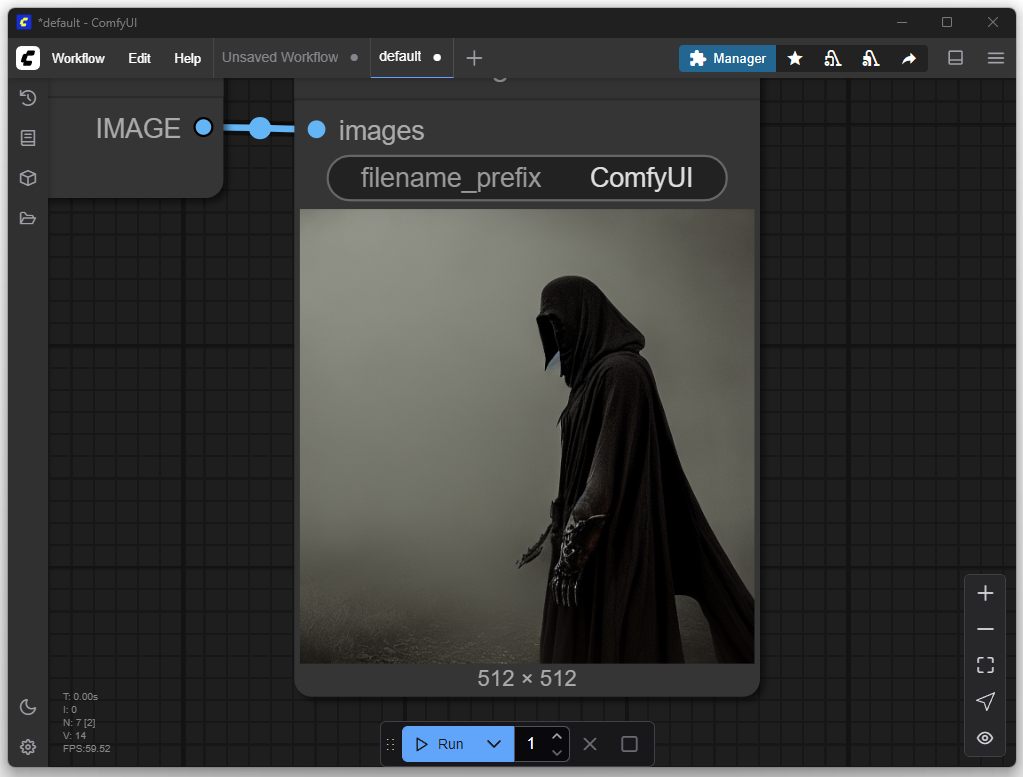
Agregar más modelos
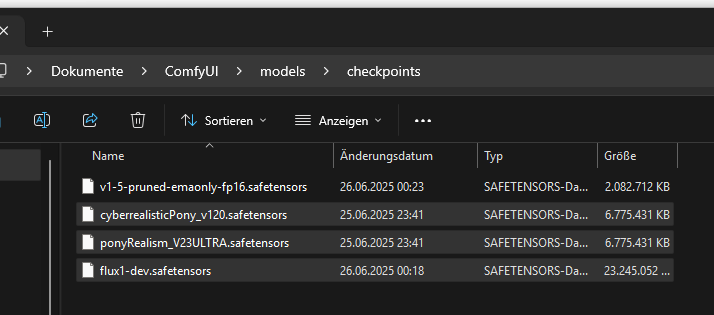
El modelo instalado anteriormente se encuentra dentro de la carpeta de modelos:
La fortaleza de ComfyUI radica en el manejo flexible de distintos modelos, lo que permite una alta adaptabilidad en la generación de imágenes. En plataformas como Civitai y Hugging Face hay numerosos modelos potentes disponibles, que se integran fácilmente en flujos de trabajo existentes.
Civitai y Hugging Face ofrecen una gran selección de modelos especializados de LoRA y de puntos de control (Checkpoint), mantenidos y valorados por la comunidad. Esto facilita la elección precisa de los modelos adecuados para estilos o motivos específicos.
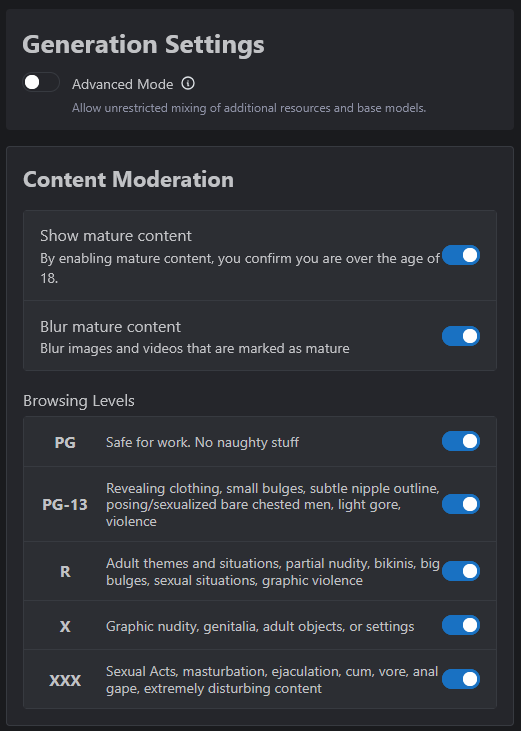
La visualización de contenido para adultos debe habilitarse primero en CIVITAI:
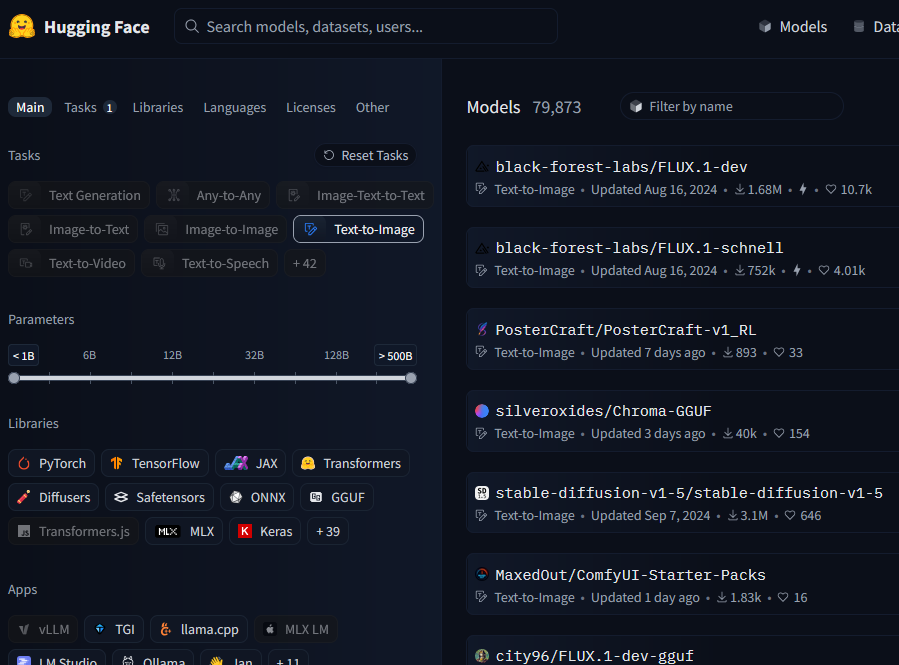
Descarga del modelo Flux en Hugging Face:
En este ejemplo copié los modelos “CyberRealistic Pony” y “Pony Realism” en la carpeta correspondiente. El modelo Flux de Hugging Face se usará en un paso posterior y debe moverse a otra carpeta.
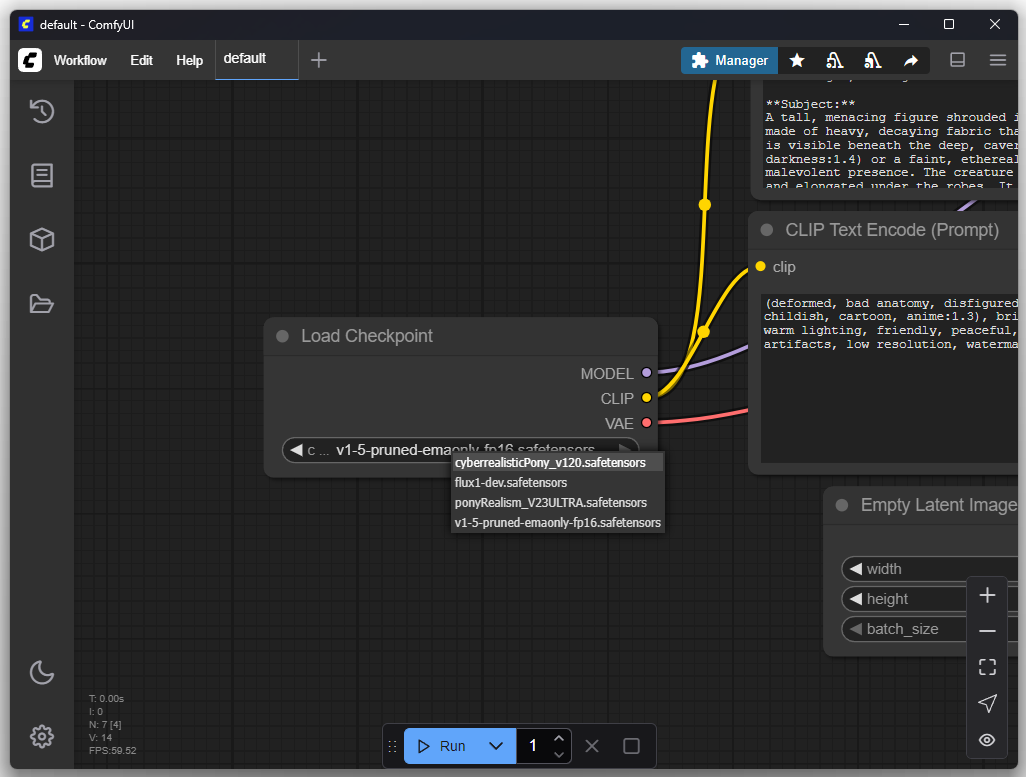
Dentro de “Load Checkpoint” se puede cambiar el modelo:
Estructura de carpetas
Dentro de la carpeta “Outputs” se encuentran las imágenes renderizadas:
Modelos monolíticos vs. modulares
Un sistema moderno de generación de imágenes controlado por texto, a menudo denominado simplemente “modelo”, es en la práctica un sistema compuesto por varios redes neuronales especializadas que trabajan secuencialmente. La arquitectura estándar, utilizada por la mayoría de sistemas como Stable Diffusion, consta de tres componentes principales.
Codificador de texto (Text Encoder / CLIP)
El codificador de texto es una red neuronal basada en Transformers cuya única función es traducir una entrada textual (prompt) a un espacio de representación numérico (un conjunto de vectores) que el U-Net pueda procesar.
U-Net (el modelo de difusión propiamente dicho)
El U-Net es el núcleo que realiza el trabajo “creativo”. El U-Net no empieza con un lienzo vacío y blanco, sino con una imagen compuesta únicamente por puntos de color aleatorios, como el “ruido” en un televisor antiguo. En esta imagen no hay absolutamente ninguna estructura.
El U-Net observa ahora dos cosas simultáneamente: la imagen actual con los puntos aleatorios y la instrucción del codificador de texto.
Basado en un prompt como por ejemplo “gato en una silla”, el U-Net modifica una y otra vez los puntos aleatorios. Este proceso se repite muchas veces (por ejemplo, 40). En cada paso, el U-Net observa la nueva imagen, ligeramente mejorada, y reordena los puntos un poco más. Se puede imaginar como si enfocaras lentamente una foto extremadamente borrosa, clic a clic. Con cada paso, el caos se organiza hasta que al final surge una estructura clara y reconocible. Este resultado aún no es una imagen terminada, sino más bien un plan detallado o un boceto para la imagen final.
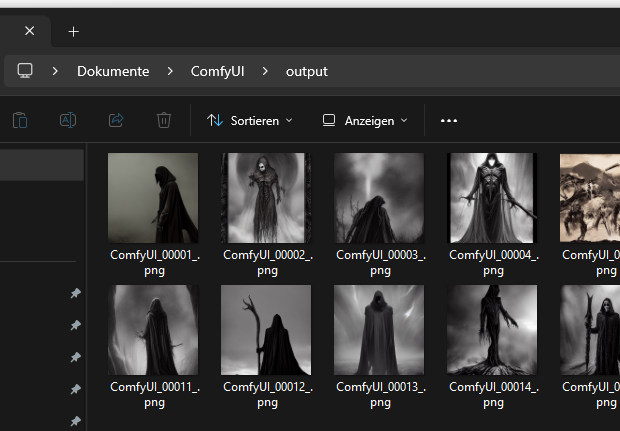
La siguiente imagen se genera después de una iteración:
Después de 4 iteraciones:
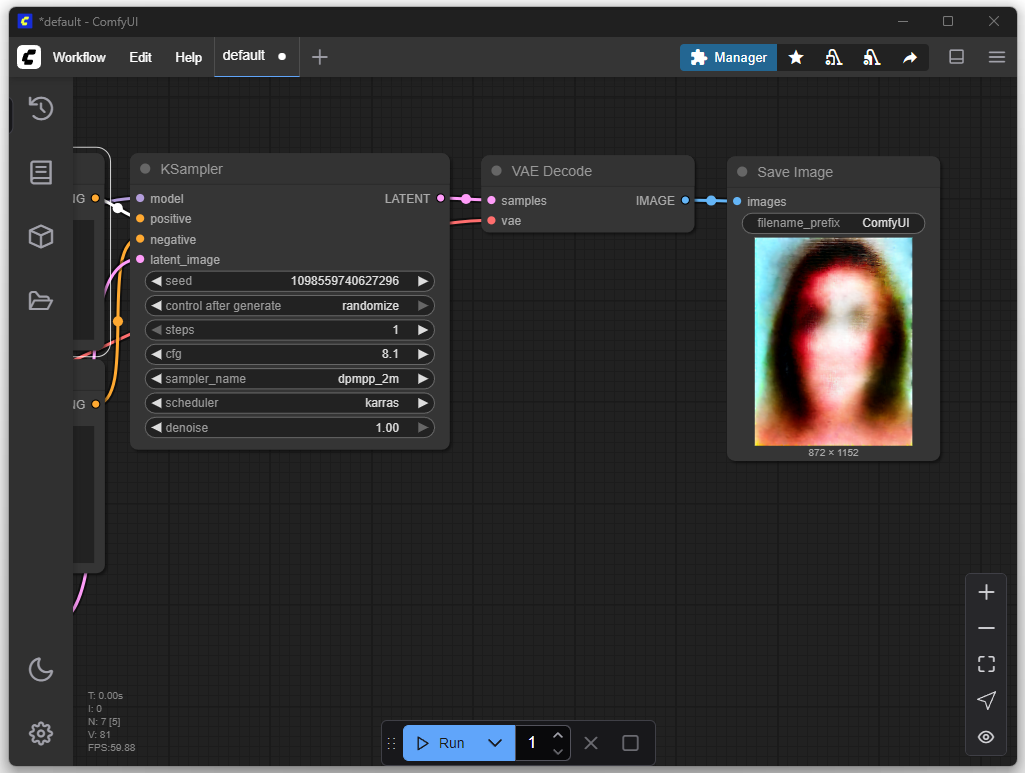
Después de 40 iteraciones:
Autoencoder variacional (VAE)
El VAE tiene una tarea muy específica y sencilla: convierte el “plan” creado por el U-Net en una imagen normal y visible.
Se puede imaginar el VAE como una impresora o un laboratorio fotográfico. Lee la información detallada del plan sobre dónde deben ir colores, bordes y superficies, y pinta los píxeles finales sobre esa base. Añade los últimos detalles finos y texturas para que la imagen quede nítida y realista.
Punto de control
Un punto de control es un archivo que guarda el estado completamente aprendido de una o varias redes neuronales en un momento determinado.
cyberrealisticPony_v120.safetensors es un punto de control monolítico. Esto significa que los pesos entrenados de las tres redes neuronales necesarias para la generación de imágenes (codificador de texto, U-Net, VAE) se agrupan y guardan en un único archivo *.safetensors. El nodo CheckpointLoader en ComfyUI está diseñado para cargar dicho archivo, separar internamente las tres componentes y enviarlas a tres salidas distintas: MODEL (para el U-Net), CLIP (para el codificador de texto) y VAE. El propósito principal de este formato es la facilidad de uso para el usuario final.
flux1-dev.safetensors utiliza una arquitectura modular. Los componentes del sistema se distribuyen como archivos independientes. El archivo flux1-dev.safetensors contiene únicamente los pesos para el U-Net. El codificador de texto y el VAE deben estar en archivos separados.
Las razones para esta estructura modular son:
Flexibilidad
Se pueden intercambiar componentes. Un U-Net puede combinarse con distintos VAEs o codificadores de texto para modificar el resultado sin tener que reentrenar el modelo principal.Desarrollo eficiente
Los desarrolladores pueden actualizar y publicar una sola componente, como el U-Net en FLUX, sin tener que empaquetar y distribuir de nuevo las partes inalteradas del sistema.Especialización
Permite desarrollar componentes individuales altamente optimizados. El U-Net de FLUX tiene una nueva arquitectura, pero es compatible con los codificadores de texto y VAEs estándar existentes.
La elección del punto de control “correcto”
Un aspecto crucial al trabajar con generadores de imágenes de IA es entender que no todos los puntos de control son adecuados para cualquier tipo de gráfico. Estos modelos, a menudo almacenados como archivos en formato .safetensors, se entrenan con conjuntos de datos muy especializados. Sus capacidades dependen directamente del tipo de imágenes utilizadas en su entrenamiento.
Un modelo como cyberrealisticPony_v120.safetensors, entrenado principalmente con imágenes fotorrealistas de mujeres, ofrecerá resultados sobresalientes en la representación de anatomía humana y estilos de retrato específicos. Sin embargo, si se intenta crear un Nazgûl de “El Señor de los Anillos” con ese mismo modelo, el resultado será insatisfactorio. Al modelo le faltan las referencias visuales aprendidas sobre la estética oscura de fantasía, las túnicas rasgadas y la apariencia sin rostro de estas criaturas. Por tanto, elegir el punto de control adecuado y temáticamente apropiado es el primer paso fundamental para obtener la imagen deseada.
Flux
En el panorama de los generadores de imágenes de IA, que evoluciona rápidamente, Flux ha despertado un gran interés. En esencia, Flux se diferencia de modelos consolidados como Stable Diffusion por su arquitectura subyacente. En lugar de un proceso de difusión gradual, utiliza una tecnología llamada Flow Matching, que permite generar imágenes de forma significativamente más rápida y con menos pasos de cómputo. La relevancia del modelo también se ve reforzada por el equipo de desarrollo, formado por personas clave que ya participaron en la creación de Stable Diffusion.
Como Flux tiene una estructura modular, no se puede usar directamente el flujo de trabajo existente. Sin embargo, ComfyUI ofrece plantillas predefinidas que facilitan el inicio. Para utilizar Flux, solo es necesario descargar los componentes de modelo que faltan (es decir, Text-Encoder, U-Net y VAE) y copiarlos en las carpetas correspondientes dentro de ComfyUI.
Me decidí por la plantilla “Flux Dev full text to image” y luego copié los modelos faltantes en las ubicaciones correspondientes.
Codificador de texto
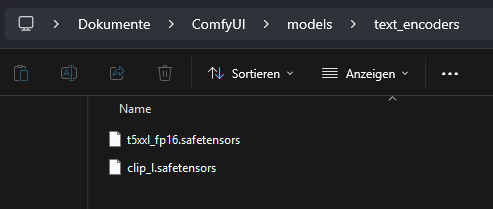
U-Net
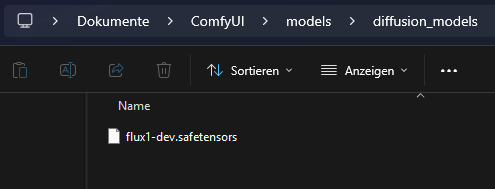
VAE
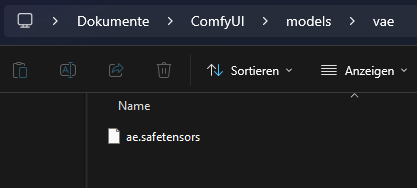
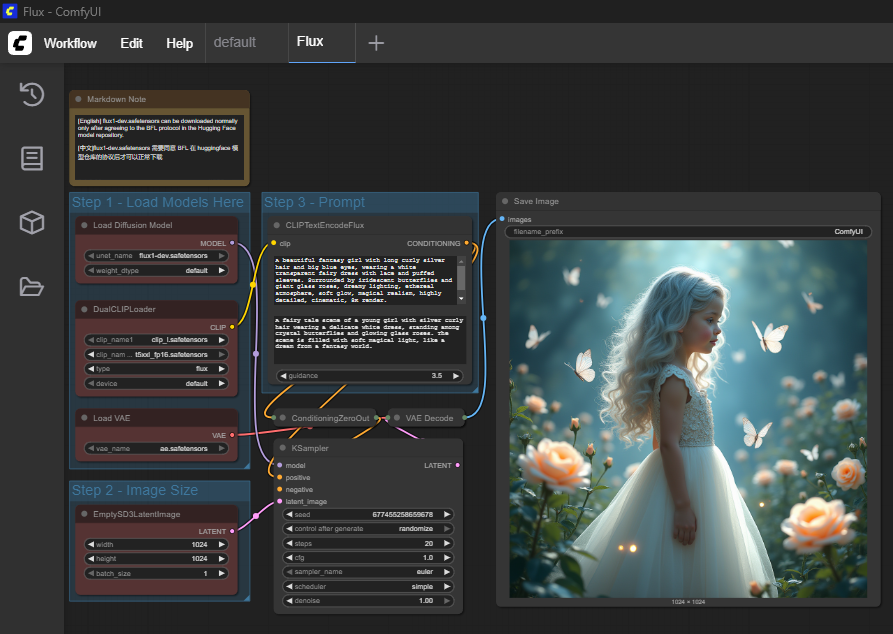
El primer resultado de Flux con la configuración básica y el prompt predeterminado de la plantilla importada de Flux:
LoRA
LoRA significa “Low-Rank Adaptation” y es un método para la fine-tuning eficiente en memoria de grandes modelos de IA preentrenados, como Stable Diffusion o Flux. Un modelo base de este tipo, también llamado checkpoint, consta de varios gigabytes de datos e incluye matrices de pesos, vectores y valores de sesgo (bias). Estos definen la estructura interna y el comportamiento del modelo. La arquitectura de un modelo es fija y única. Un LoRA debe adaptarse exactamente a esta arquitectura, ya que funciona como un complemento a medida. No es de uso universal. Un LoRA creado para Stable Diffusion v1.5 no es compatible con SDXL, ya que este último posee una arquitectura diferente. Las denominaciones, tamaños y funciones de las matrices de pesos difieren.
Si se quisiera ampliar un modelo con un nuevo estilo o concepto, normalmente habría que reentrenarlo por completo. Este proceso es laborioso, requiere mucha potencia de cálculo y genera de nuevo un archivo de gran tamaño. LoRA evita este esfuerzo con un enfoque distinto. En lugar de modificar directamente las matrices de pesos existentes, se entrenan pares de matrices pequeñas adicionales. Estas son mucho más pequeñas y contienen únicamente la desviación respecto al modelo original. Al usarlo, el LoRA se carga junto con el modelo original. Interviene en el proceso de cálculo añadiendo sus valores en un punto determinado del flujo de la red. Esto ocurre dentro de una capa del modelo, antes de pasar el resultado a la siguiente capa. Así, se puede ajustar el comportamiento del modelo de forma precisa sin alterar permanentemente sus parámetros originales.
Ejemplo:
Para generar una imagen de Rapunzel se puede usar el modelo Illustrij, optimizado para personajes estilizados (Link).
Al añadir un modelo LoRA adecuado, entrenado específicamente con material de Rapunzel (Link), se puede ampliar temporalmente el modelo base para que genere imágenes de Rapunzel sin modificar permanentemente el modelo original.
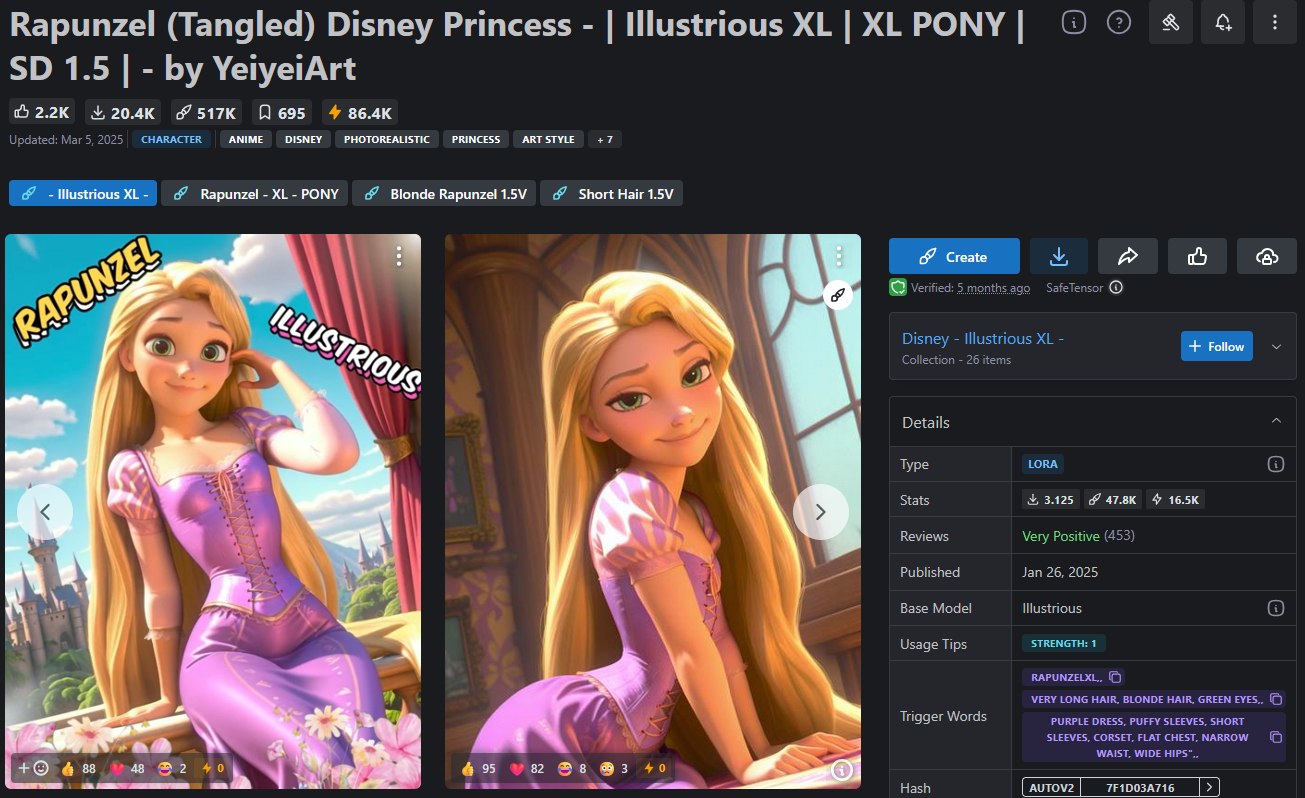
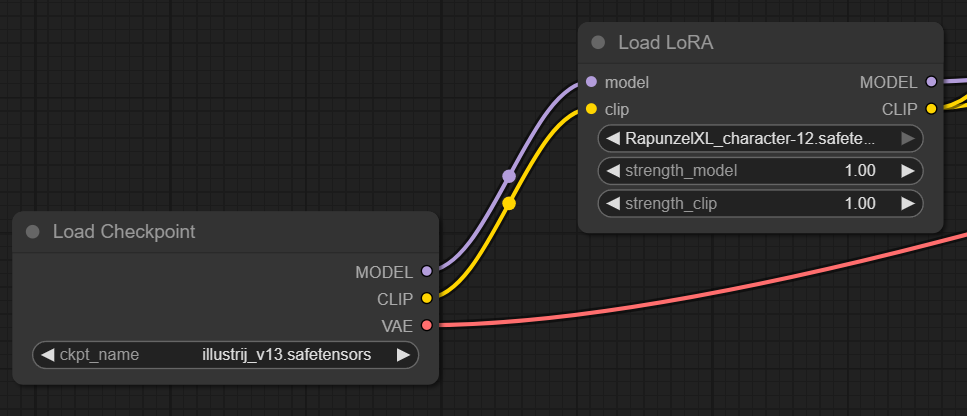
La imagen muestra la ejecución en serie de un flujo de trabajo en ComfyUI con un modelo base y un módulo LoRA. Primero se carga el modelo principal illustrij_v13.safetensors. Este proporciona los componentes básicos del modelo (MODEL, CLIP, VAE). Después se carga el modelo LoRA RapunzelXL_character-12.safetensors, al que se envían las salidas MODEL y CLIP del modelo base. El modelo LoRA modifica estos componentes en tiempo de ejecución según sus propios pesos. De este modo, el modelo base se amplía dinámicamente con el concepto de Rapunzel, sin alterar el checkpoint original. También es posible encadenar varios modelos LoRA (en serie) para dotar al personaje de nuevas “habilidades” en cada paso.
El resultado tras usar el modelo LoRA RapunzelXL:

El resultado con la misma configuración pero SIN el modelo LoRA RapunzelXL:
