La cuestión era si los modelos de lenguaje de gran tamaño (LLMs) actuales como GPT-4 o DeepSeek eran capaces de clasificar automáticamente y de forma fiable piezas musicales – específicamente canciones de salsa – en “Salsa Cubana” o “Salsa Línea” basándose en el título, el artista, la letra y los metadatos. Se sabía que la información disponible (metadatos, etiquetas de género, letras) era incompleta y en parte inconsistente. La prueba tenía como objetivo explícito determinar los límites prácticos de los LLM actuales en este contexto.

Procedimiento
Para cada canción de una lista de reproducción de Spotify se recopilaron todos los metadatos disponibles: título, artista, álbum, géneros, fecha de lanzamiento, letras (vía Genius), etiquetas y biografías adicionales (vía Last.fm). Estos datos fueron entregados al LLM en un formato estructurado. El prompt estaba detalladamente diseñado: además de la definición de rol y los criterios de clasificación, incluía ejemplos e instrucciones claras para que el modelo eligiera exclusivamente “Cubana” o “Línea”.
Observaciones y hallazgos
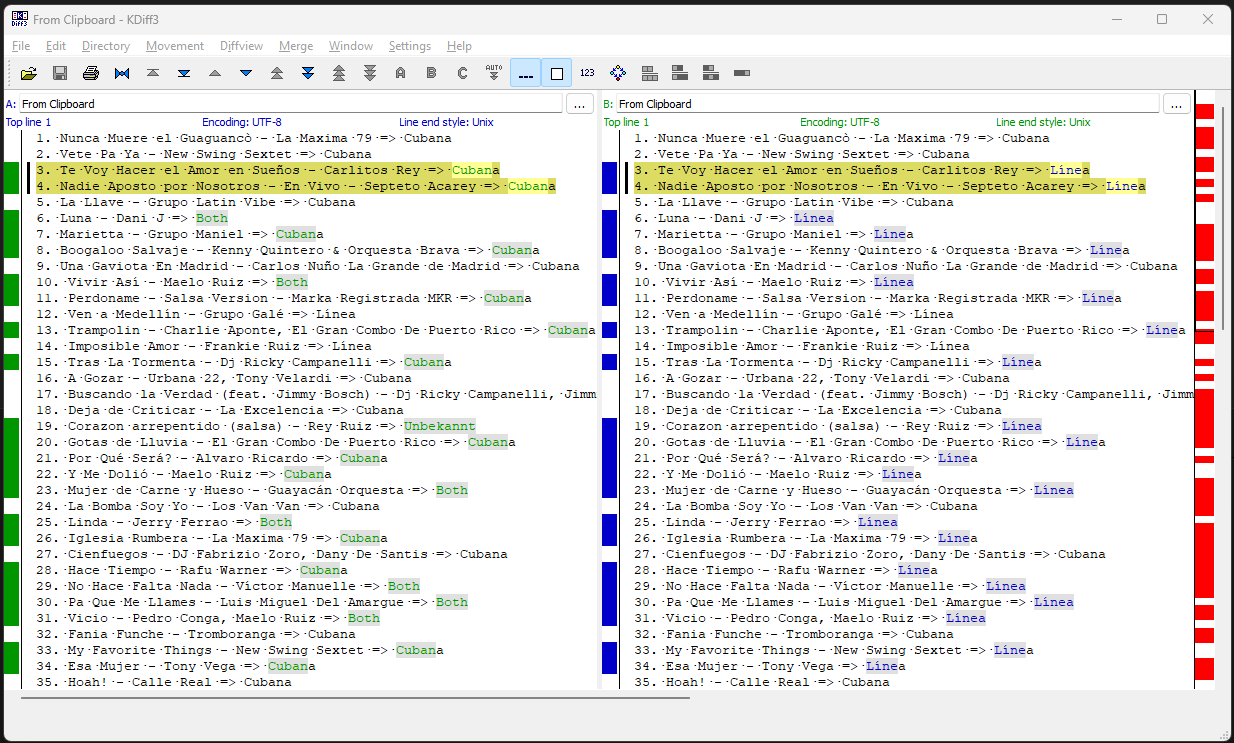
- La clasificación por parte del LLM se realizó puramente basándose en texto. Con ello se excluye por completo una comprensión real de la música.
- Los metadatos disponibles no eran suficientes para diferenciar estilos: las etiquetas de género eran generales y rara vez aparecían etiquetas como “Salsa Cubana” o “Línea”.
- Las letras rara vez ofrecían indicios claros, ya que la variedad temática en la salsa es muy amplia.
- Los LLMs mostraron resultados inconsistentes en ocasiones con prompts y datos idénticos. Diferentes modelos (p. ej., DeepSeek, GPT-4o) obtuvieron a veces resultados distintos con la misma entrada.
- Incluso al agregar más metadatos y fuentes externas como Last.fm no se logró mejorar la calidad de la asignación. Los resultados siguieron siendo poco fiables, a menudo se asignaba de forma general “Cubana”, independientemente de las características reales del estilo.
Conclusión
Una clasificación fiable del estilo musical basándose únicamente en metadatos y letras no es posible con los LLM actuales. Los resultados son inconsistentes, la tasa de error elevada y las asignaciones, en su mayoría, poco transparentes. Los metadatos adicionales y las plantillas de prompts detalladas con ejemplos e instrucciones no pudieron superar las limitaciones de los modelos. Para una clasificación estilística musical precisa, sigue siendo necesario el conocimiento experto humano o un análisis musical específico.