Este código muestra cómo se entrena una red neuronal artificial con el conjunto de datos MNIST para clasificar dígitos escritos a mano (0-9). El objetivo es que el modelo pueda predecir, a partir de los datos de imagen, qué dígito está representado.
Esto se logra mediante:
1. Carga y preprocesamiento de los datos de imagen de MNIST.
2. Creación de una red neuronal con varias capas (capas).
3. Entrenamiento de la red con datos de entrenamiento.
4. Evaluación del rendimiento del modelo con datos de prueba.
5. Prueba del modelo con nuevos datos de ejemplo.
La clasificación de dígitos es un problema clásico de aprendizaje automático que ayuda a los principiantes a entender los fundamentos de las redes neuronales. El conjunto de datos MNIST es ideal porque es lo suficientemente pequeño para entrenarse rápidamente, pero lo bastante complejo para crear modelos significativos.
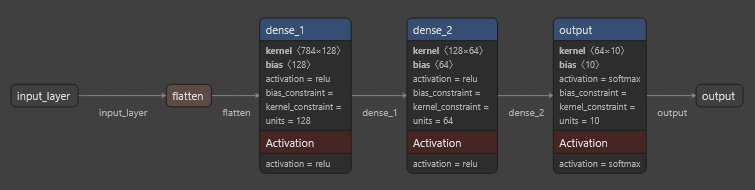
Visualización del modelo

Salida de Bash
Explicación de la salida de Bash
Estos son los dígitos reales (etiquetas) de las primeras diez imágenes del conjunto de entrenamiento de MNIST.Esto sirve para verificar las etiquetas y asegurarse de que los datos se cargaron correctamente.
Este mensaje significa que TensorFlow detecta y utiliza las funciones de aceleración de CPU AVX y AVX2.
TensorFlow detecta y utiliza la NVIDIA GeForce RTX 4070 Ti como GPU para el entrenamiento. Compute Capability 8.9 significa que la GPU es compatible con Tensor Cores y otros cálculos optimizados con CUDA.
Epoch 1/5 significa que comienza la primera de cinco épocas de entrenamiento.
1875/1875 muestra que el modelo procesó todas las 60.000 imágenes de entrenamiento en 1875 lotes de 32 imágenes cada uno.
Duración: 3 segundos
Pérdida (tasa de error en datos de entrenamiento): 0.2411
Precisión (precisión en datos de entrenamiento): 93.05%
val_loss (tasa de error en datos de validación): 0.1258
val_accuracy (precisión en datos de validación): 96.02%
Incluso después de la primera época, el modelo alcanza una precisión muy alta del 93% en los datos de entrenamiento y del 96% en los datos de prueba. El modelo mejora con cada época. Epoch 5: La precisión final es 98.62% en los datos de entrenamiento y 97.93% en los datos de prueba.
El modelo se evalúa con los datos de prueba (10.000 imágenes). Precisión: 97.93% en los datos de prueba. Esto significa que el modelo predice el dígito correcto en el 97.93% de los casos.
Se presentó una única imagen de prueba al modelo. El modelo predice: 7