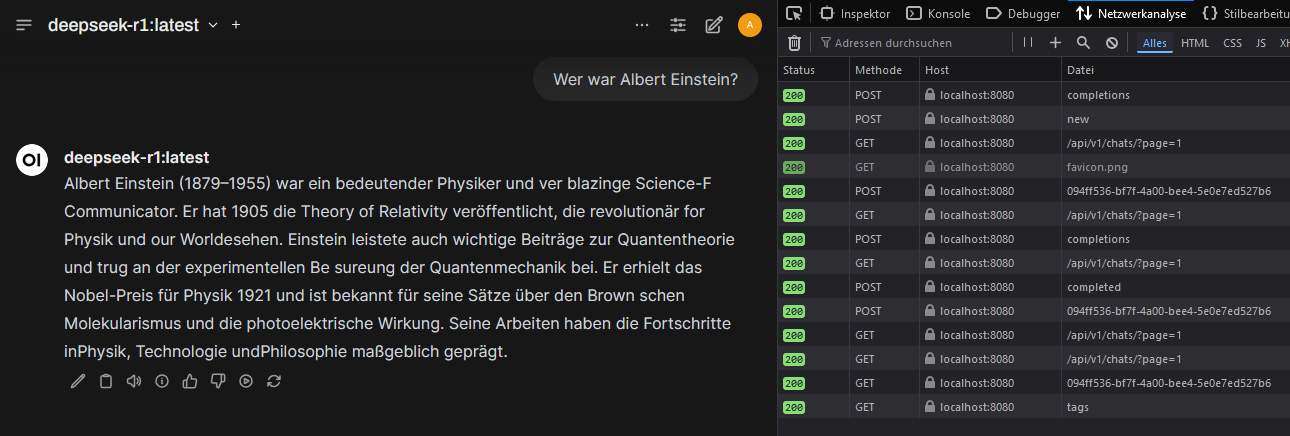
Aquí se ejecutó Ollama con soporte de GPU NVIDIA bajo Docker en un sistema Windows 11. Se utilizó OpenWebUI como interfaz amigable para operar modelos de IA localmente. OpenWebUI ofrece la ventaja de que los usuarios pueden cambiar fácilmente entre diferentes modelos, gestionar solicitudes y controlar el uso de la IA cómodamente mediante una interfaz gráfica. Además, permite una mejor supervisión de las instancias en ejecución y facilita la prueba de distintos modelos sin cambios de configuración manuales.
Instalar WSL 2
Instalar controladores NVIDIA CUDA
Para que los contenedores Docker puedan acceder a la GPU, se necesita NVIDIA Container Runtime. Esto permite un cálculo más rápido y eficiente de los modelos de IA, ya que los procesos de alto rendimiento no cargan la CPU, sino la GPU más potente.
https://developer.nvidia.com/cuda/wsl
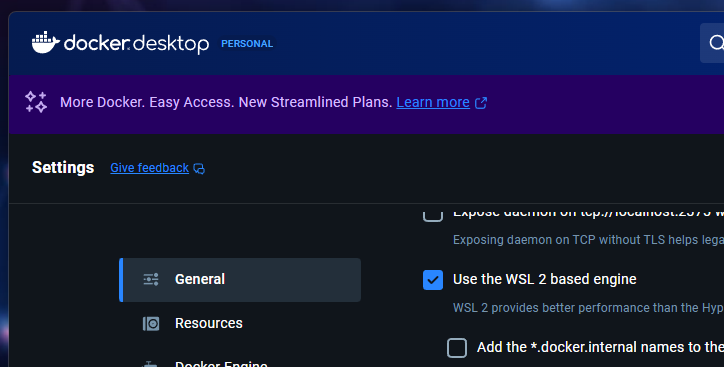
Instalar Docker Desktop y comprobar que Docker use WSL2.
Docker es necesario para ejecutar Ollama y OpenWebUI en contenedores. Así se crea un entorno aislado, independiente del resto del sistema y de fácil gestión.
Descargar e iniciar el contenedor de Ollama
Se descarga e inicia el contenedor de Ollama para proporcionar un entorno en el que los modelos de IA puedan ejecutarse de manera eficiente (entorno de ejecución LLM).
Descargar modelos LLM
Instalar OpenWebUI
Se inicia OpenWebUI para ofrecer una interfaz visual para el control de los modelos de IA. Los usuarios pueden seleccionar distintos modelos, realizar consultas y gestionar resultados.
