- Descargar e instalar el entorno de ejecución LLM de Ollama (descargar). Tras la instalación, se puede acceder al servidor en http://127.0.0.1:11434/.
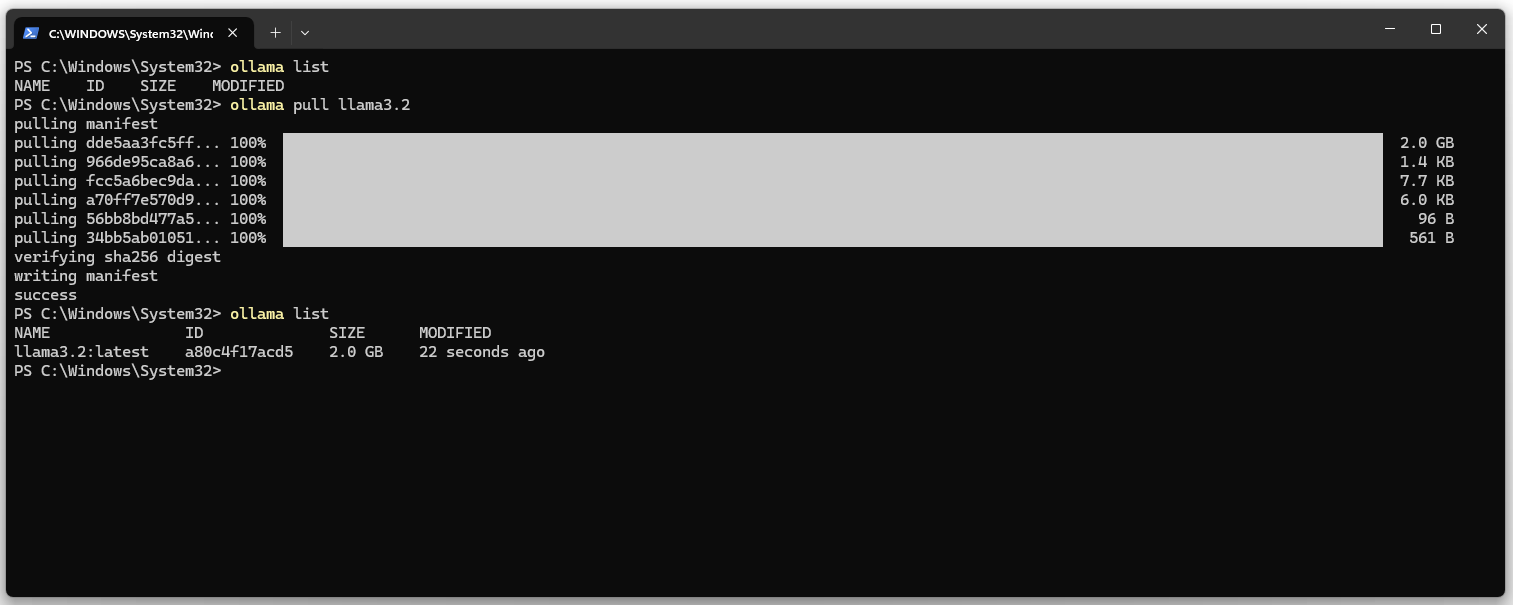
3. Mostrar la lista de modelos instalados. La lista debería estar vacía.
ollama list
4. Descargar llama3.2 LLM y DeepSeekv3 (404 GB en disco duro y 413 GB de RAM).
ollama pull llama3.2 ollama pull deepseek-v3
En la página web de Meta se pueden encontrar las versiones actuales del LLM.
5. Iniciar llama3.
ollama run llama3.2
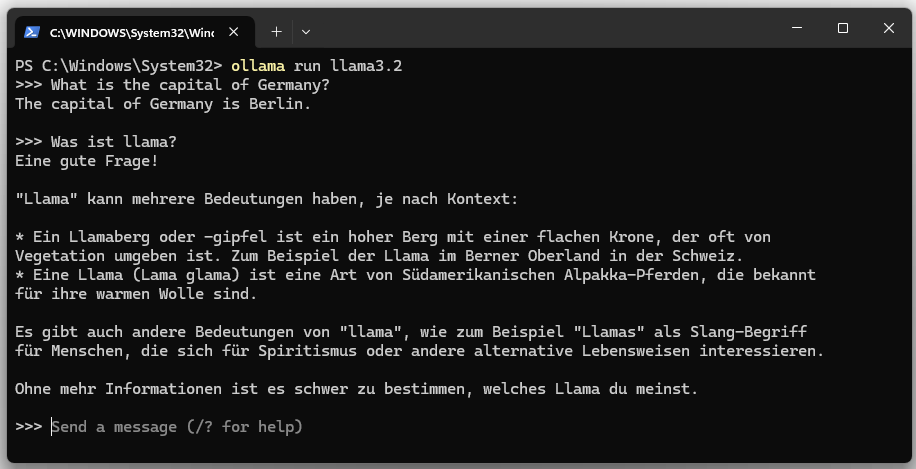
Se puede detener el modelo de lenguaje con “Ctrl + d” o con el comando “/bye”.
6. Mostrar los detalles del modelo llama3.2.
ollama show llama3.2
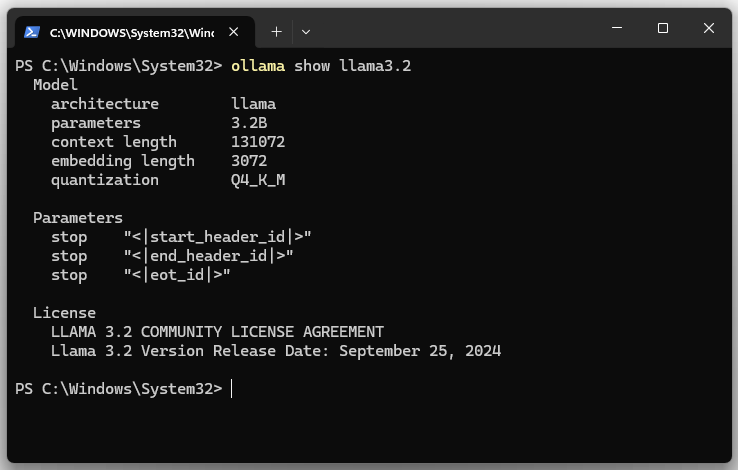
| Parameter | |
|---|---|
| architecture | Indica la arquitectura del modelo. La arquitectura define la estructura de la red neuronal. LLaMA es una familia de modelos Transformer. |
| parameters | Muestra la cantidad de parámetros del modelo. El modelo tiene 3.2B (3,2 mil millones) de parámetros. Los parámetros son los pesos y sesgos del modelo. |
| context length | Indica la longitud máxima del contexto (en tokens) que el modelo puede considerar durante el procesamiento. El valor es 131072 (131.072 tokens). Una mayor longitud de contexto permite al modelo analizar textos, documentos o conversaciones más extensos sin perder información relevante. |
| embedding length | Indica el método de cuantización utilizado. Aquí es Q4_K_M. La cuantización es una técnica para reducir el tamaño del modelo disminuyendo la precisión de los parámetros (por ejemplo, de 32 bits a 4 bits). |
| size | Este es el tamaño real en disco necesario para almacenar el modelo. |
| download name | El nombre del modelo. |
7. Mostrar las instancias en ejecución del LLM o de llama3.x.
ollama ps
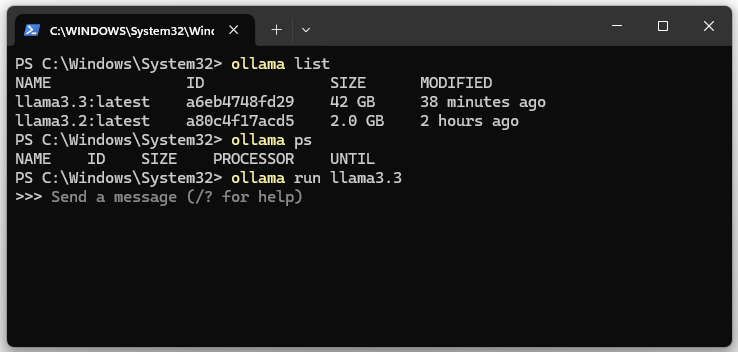
8. Detener el servidor de Ollama
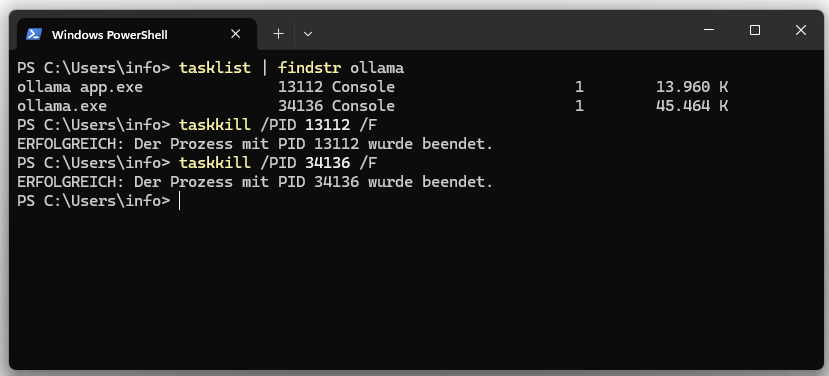
Ambos procesos se pueden finalizar desde el administrador de tareas o con Bash.
tasklist | findstr ollama taskkill /PID /F
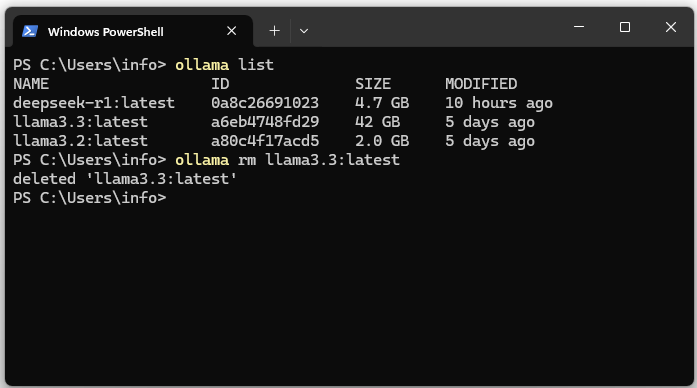
09. Desinstalar el modelo de Ollama

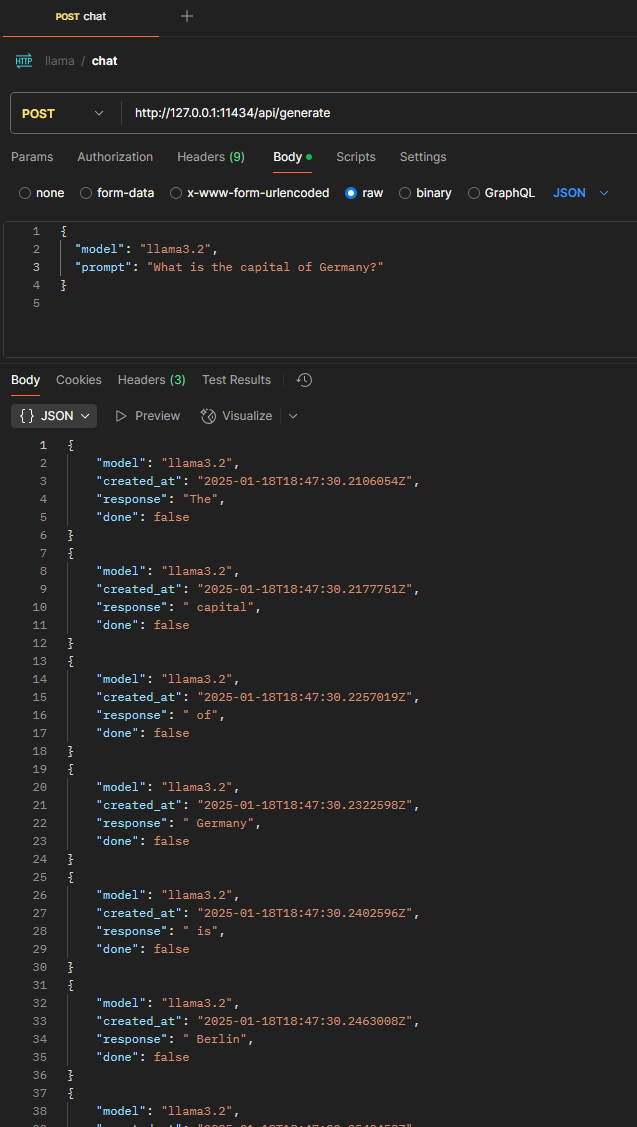
10. Llamada REST vía Postman
| Tipo de solicitud | POST |
|---|---|
| Content-Type | application/json |
| Cuerpo de la solicitud | { “model”: “llama3.2”, “prompt”: “What is the capital of Germany?” } |