Audio2Face es una herramienta impulsada por IA dentro de NVIDIA Omniverse, diseñada específicamente para generar animaciones faciales realistas basadas únicamente en audio. Forma parte de la plataforma Omniverse, que ofrece un entorno de colaboración y simulación en tiempo real para flujos de trabajo en 3D. Audio2Face utiliza una red neuronal para convertir automáticamente el habla en expresiones faciales y movimientos vívidos. Normalmente se emplea Audio2Face para hacer hablar a personajes en juegos, películas o avatares digitales sin necesidad de animaciones de fotogramas clave complejas. Los movimientos generados pueden usarse directamente o transferirse a tus propios personajes 3D, lo que resulta especialmente interesante para producciones virtuales, gemelos digitales o aplicaciones interactivas.
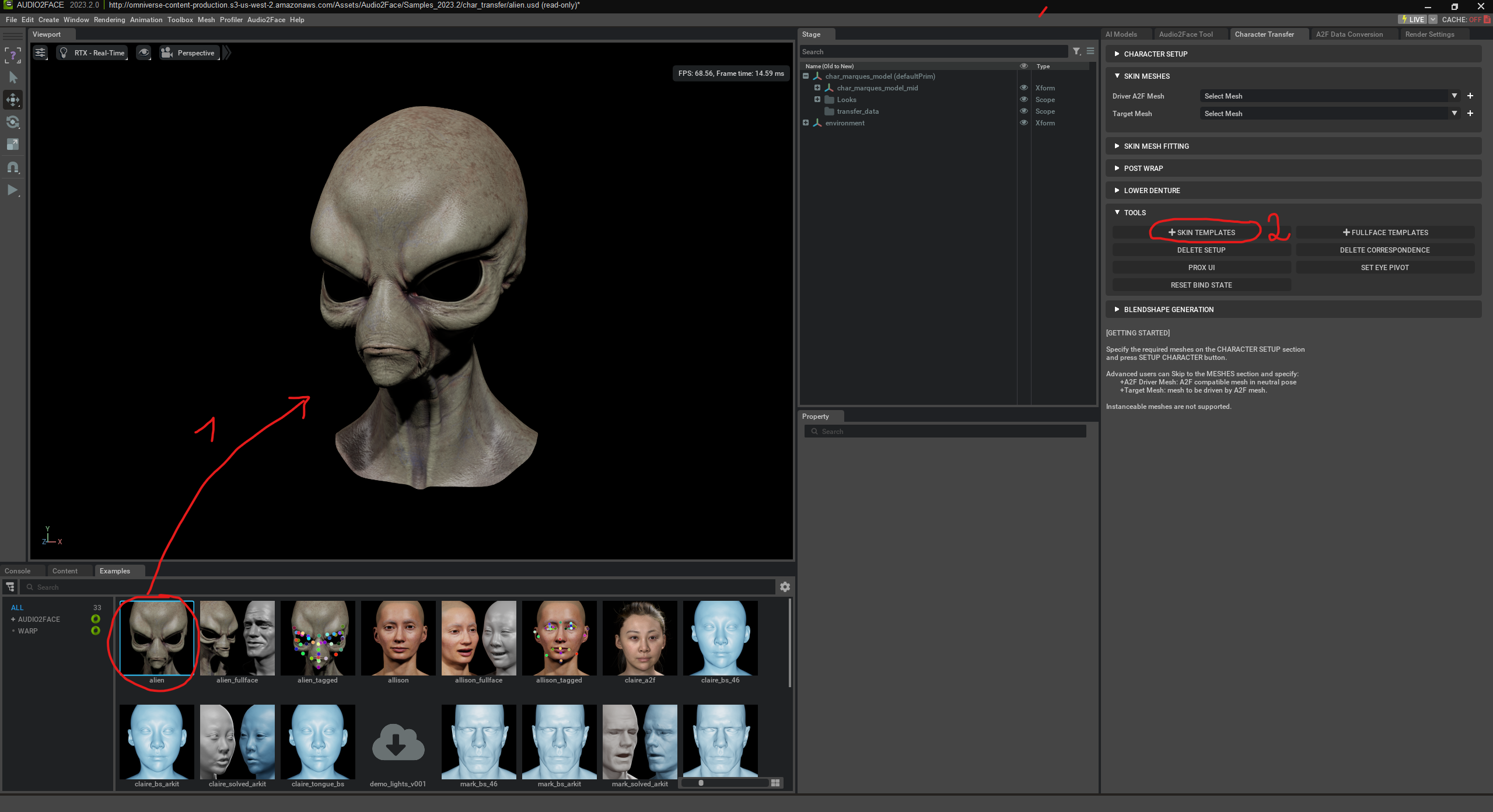
Primero podemos seleccionar una de las caras existentes. A continuación, elegimos “Skin Templates” aus.

Skin Templates en NVIDIA Audio2Face son plantillas predefinidas que dividen el rostro en diferentes zonas – como la boca, la mandíbula, los ojos, la nariz o la frente. Estas zonas ayudan a la IA a entender cómo se deben mover ciertas áreas del rostro con el habla y las emociones. Una Skin Template describe qué vértices (puntos en la malla 3D) pertenecen a qué regiones faciales y con qué intensidad se deforman con ciertos sonidos o expresiones. Cuando se quiere usar un personaje propio en Audio2Face, la Skin Template define cómo se transfieren los movimientos de la malla “Driver Mesh” controlada por IA al modelo objetivo.
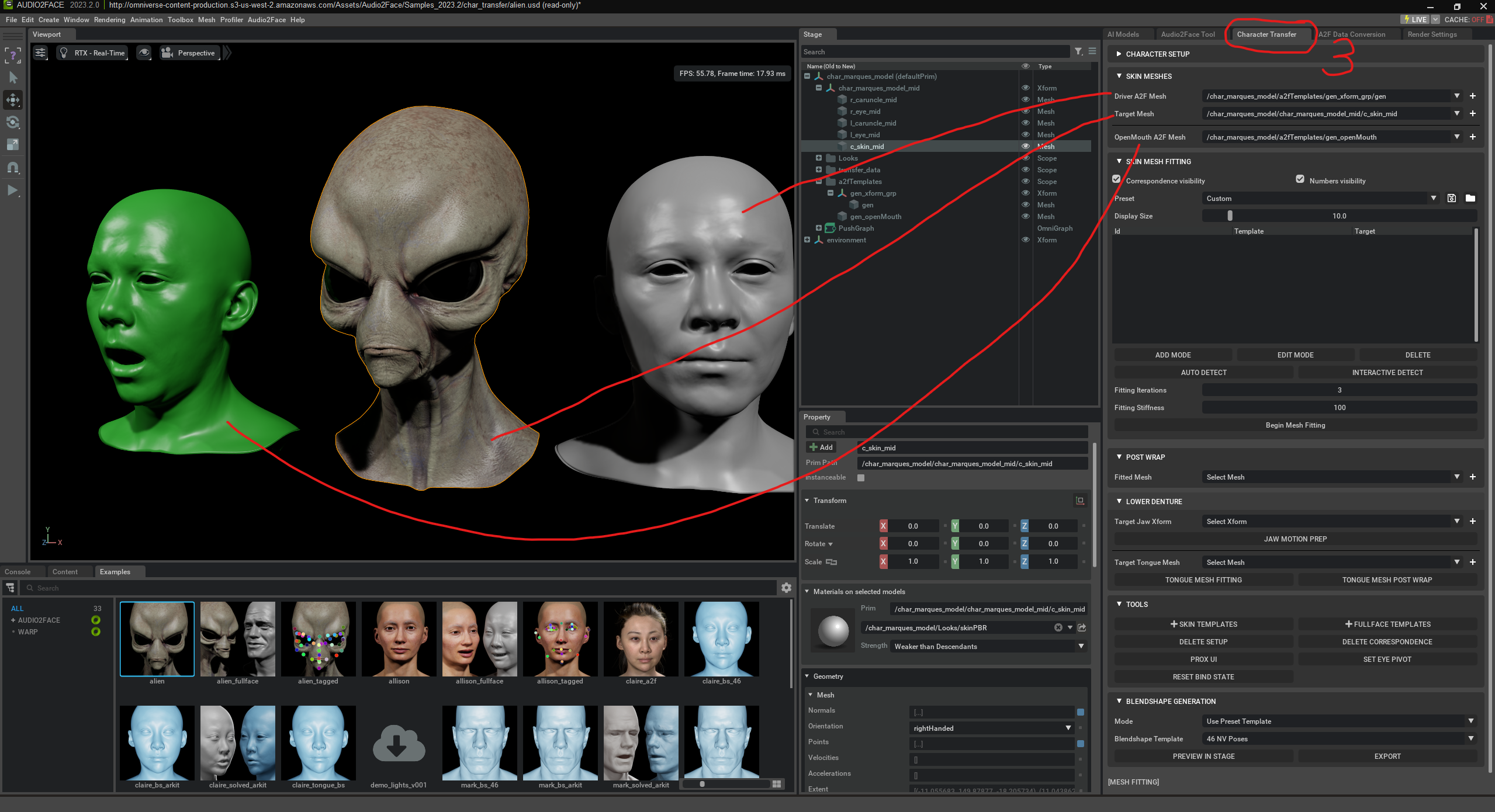
Skin Mesh Fitting se utiliza para vincular automáticamente tu propio personaje (Target Mesh) al „Driver Mesh“ impulsado por la IA (fitting).
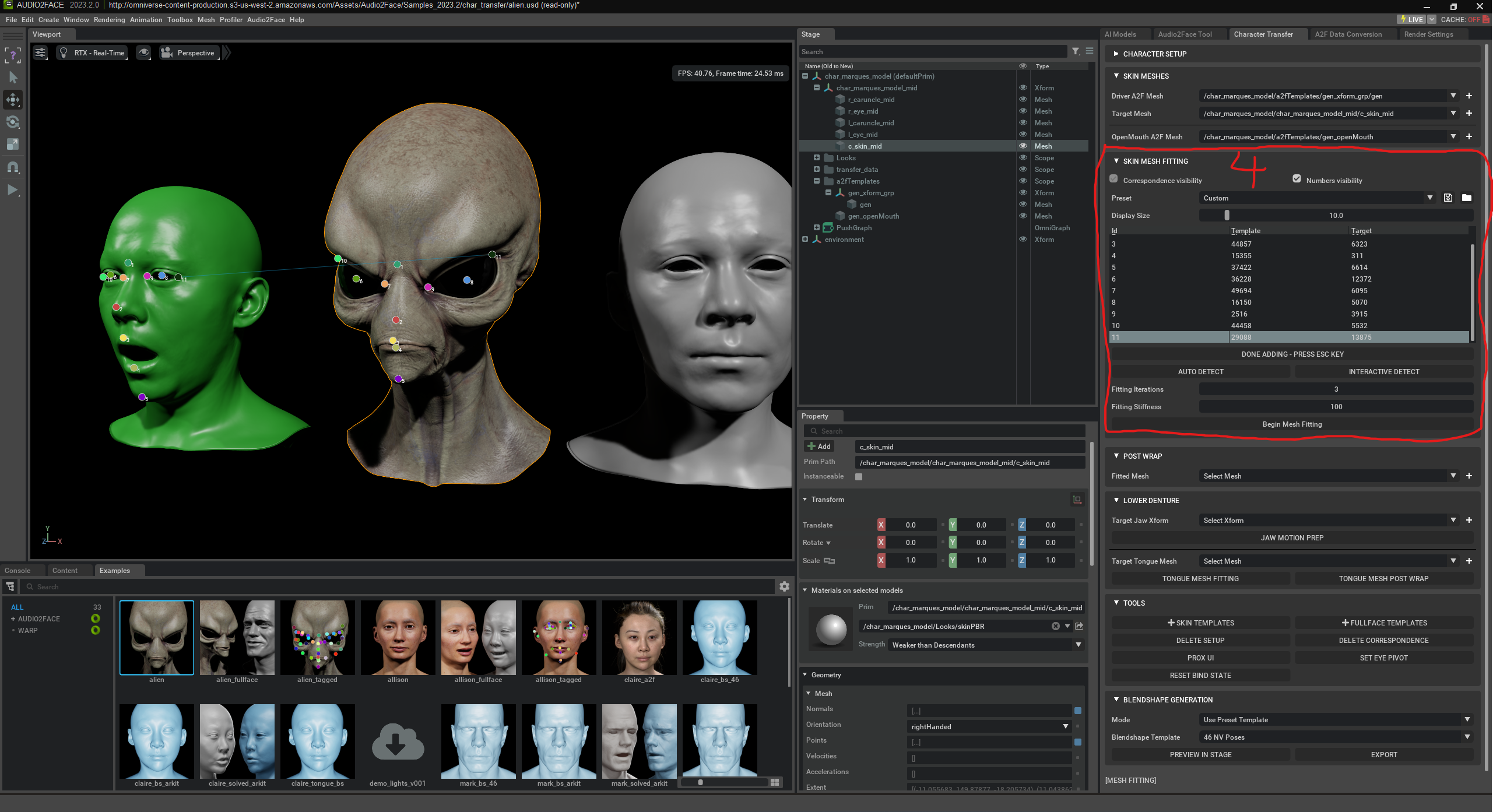
„Begin Mesh Fitting“ inicia el proceso automático de adaptación de la malla de tu personaje al sistema Audio2Face. Durante este proceso se analiza tu malla, se compara con el „Driver Mesh“ impulsado por la IA y se ajusta de forma adecuada mediante una Skin Template. El objetivo es que tu personaje adopte automáticamente la expresión facial y el habla – sin rigging manual (es decir, sin configurar huesos/esqueletos) ni blendshapes. Los blendshapes son formas faciales predefinidas como „boca abierta“, „sonrisa“ o „cejas levantadas“. La IA puede mezclarlos para generar expresiones – por ejemplo 0 % sonrisa = neutral, 100 % = sonrisa completa.
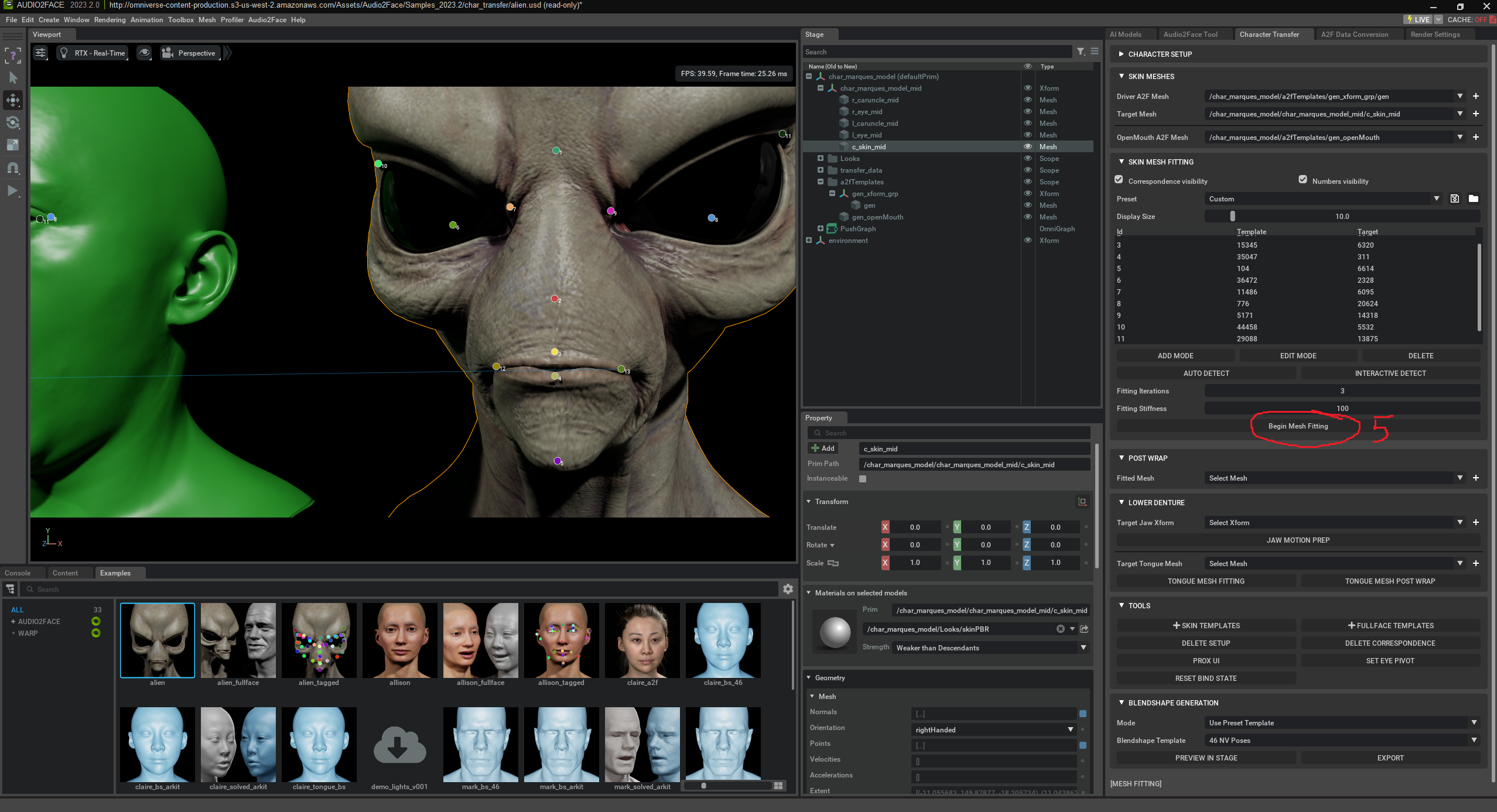
„Begin Post Wrap“ es el paso final tras el Mesh Fitting en Audio2Face. Asegura que la malla de tu personaje quede correctamente „fijada“ a la malla animada del „Driver Mesh“. En este paso, tu malla se coloca como una envoltura („Wrap“) sobre el Driver Mesh, de modo que todas las partes faciales se muevan de forma realista con el habla y la expresión. Este paso perfecciona la transferencia de movimientos y mejora la precisión y calidad de la animación. El objetivo es que tu personaje hable de forma natural y se mueva como el original – sin intervención manual.
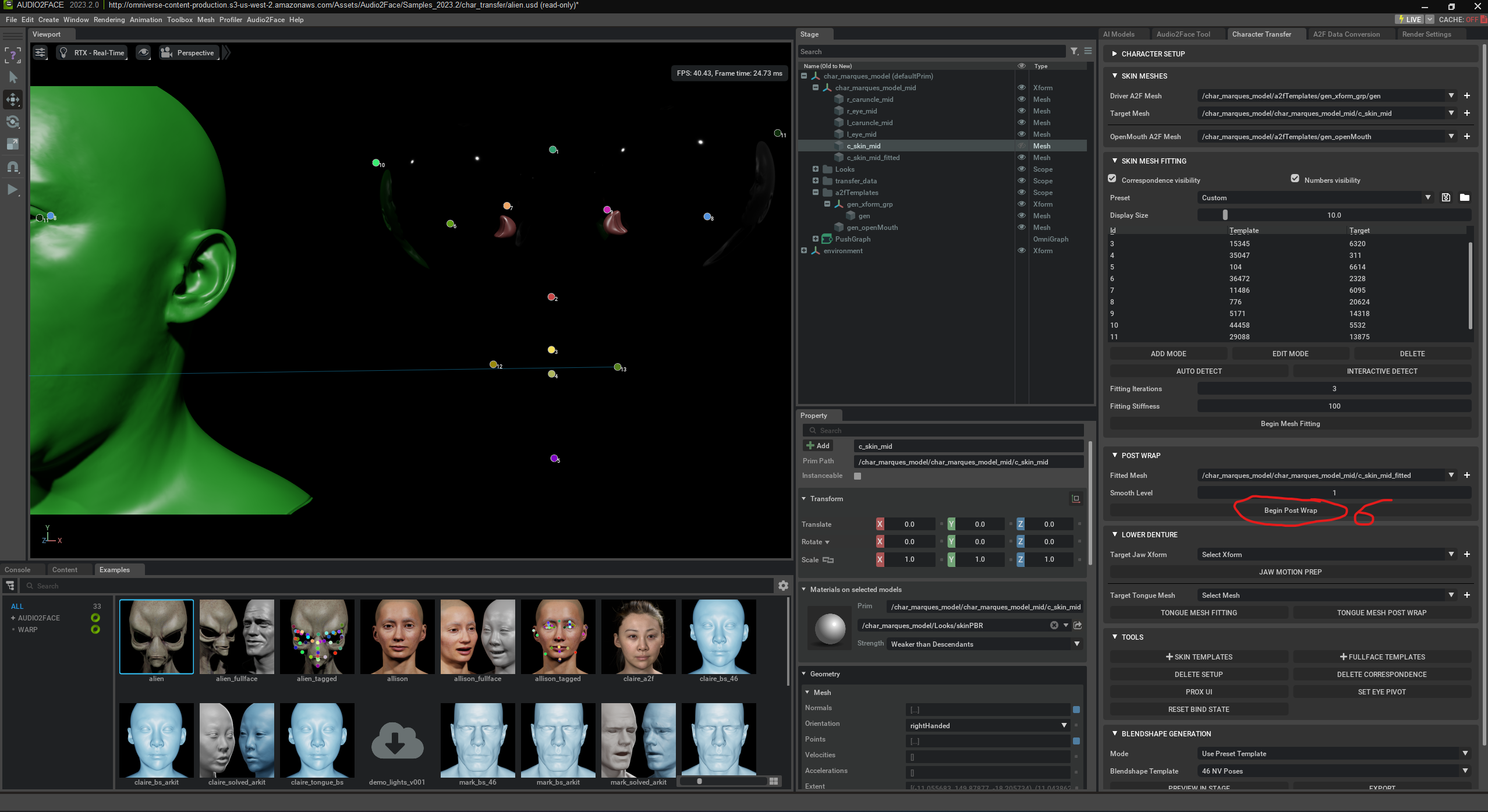
Aquí se crea la llamada „A2F Pipeline“. Esta pipeline es necesaria para conectar un rostro 3D con la animación KI controlada por audio. En la ventana mostrada, el usuario selecciona el tipo de reproductor de audio y un modelo de IA preentrenado („Mark“) que se usa para el análisis facial. Además, se activa la opción para detectar y vincular automáticamente todos los componentes faciales (como ojos, lengua, mandíbula inferior). La A2F Pipeline es por tanto el marco técnico que controla la interacción entre audio, IA y malla 3D.
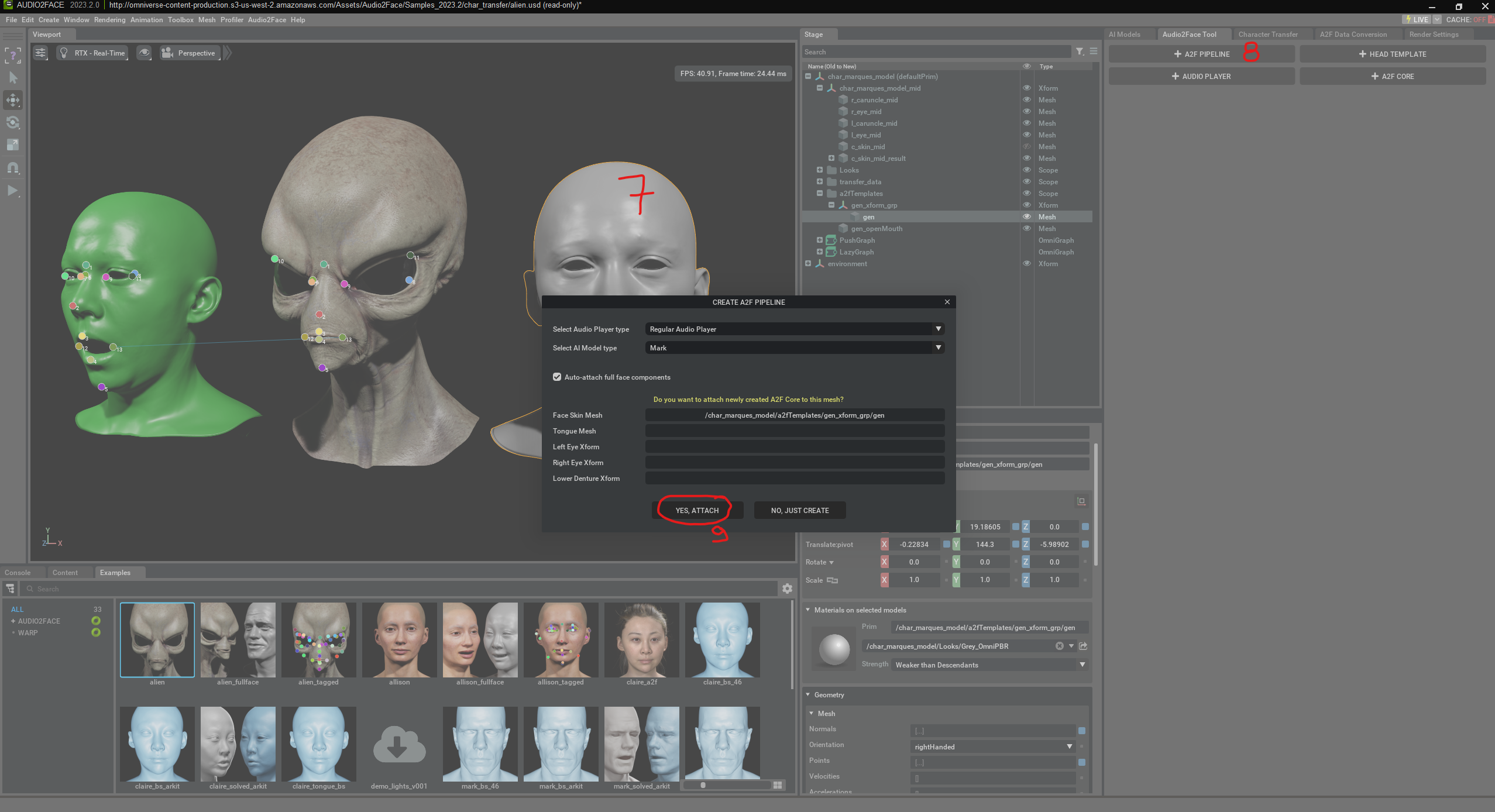
Por último, solo tenemos que pulsar “play” para ver la animación.
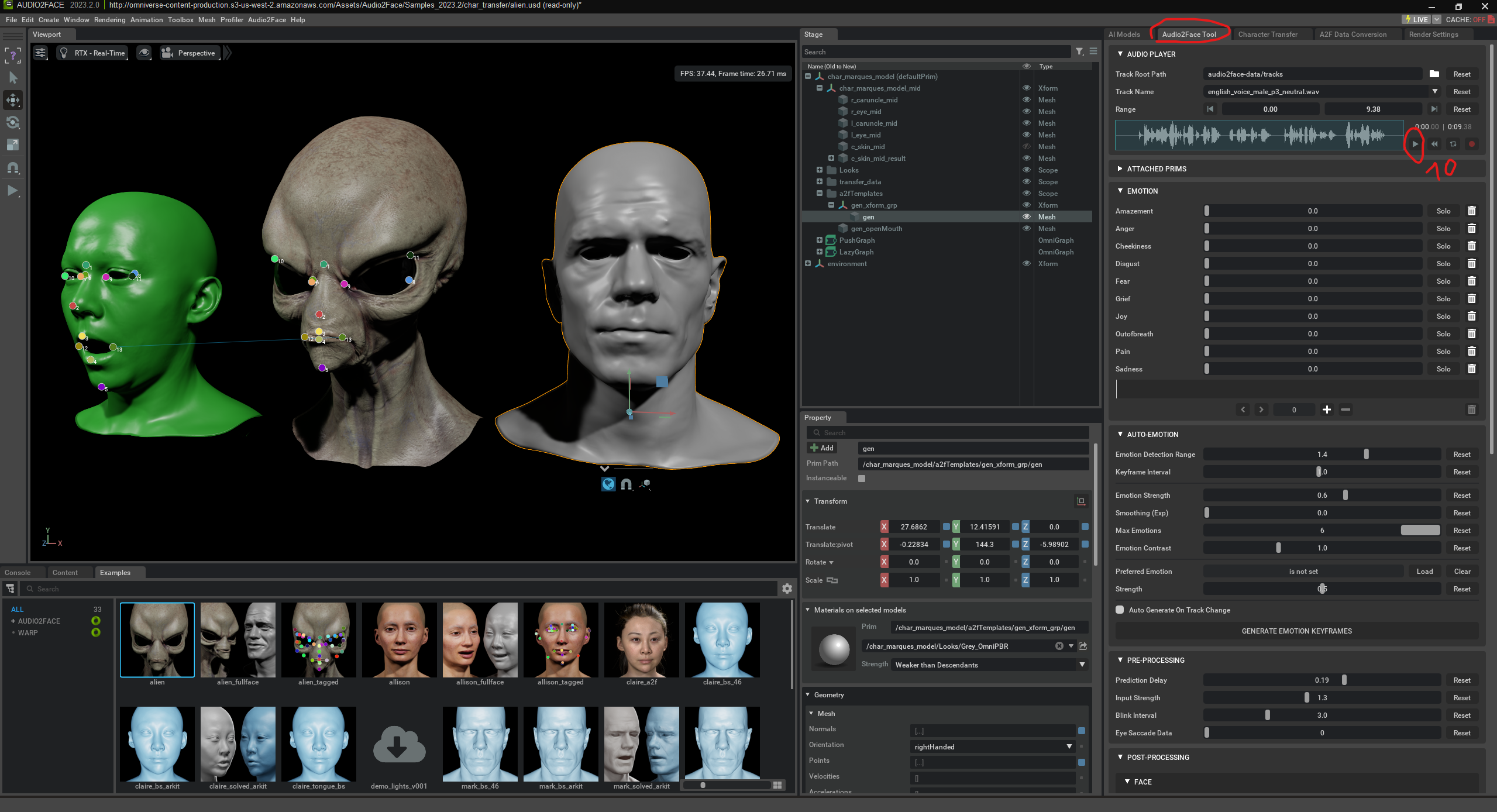
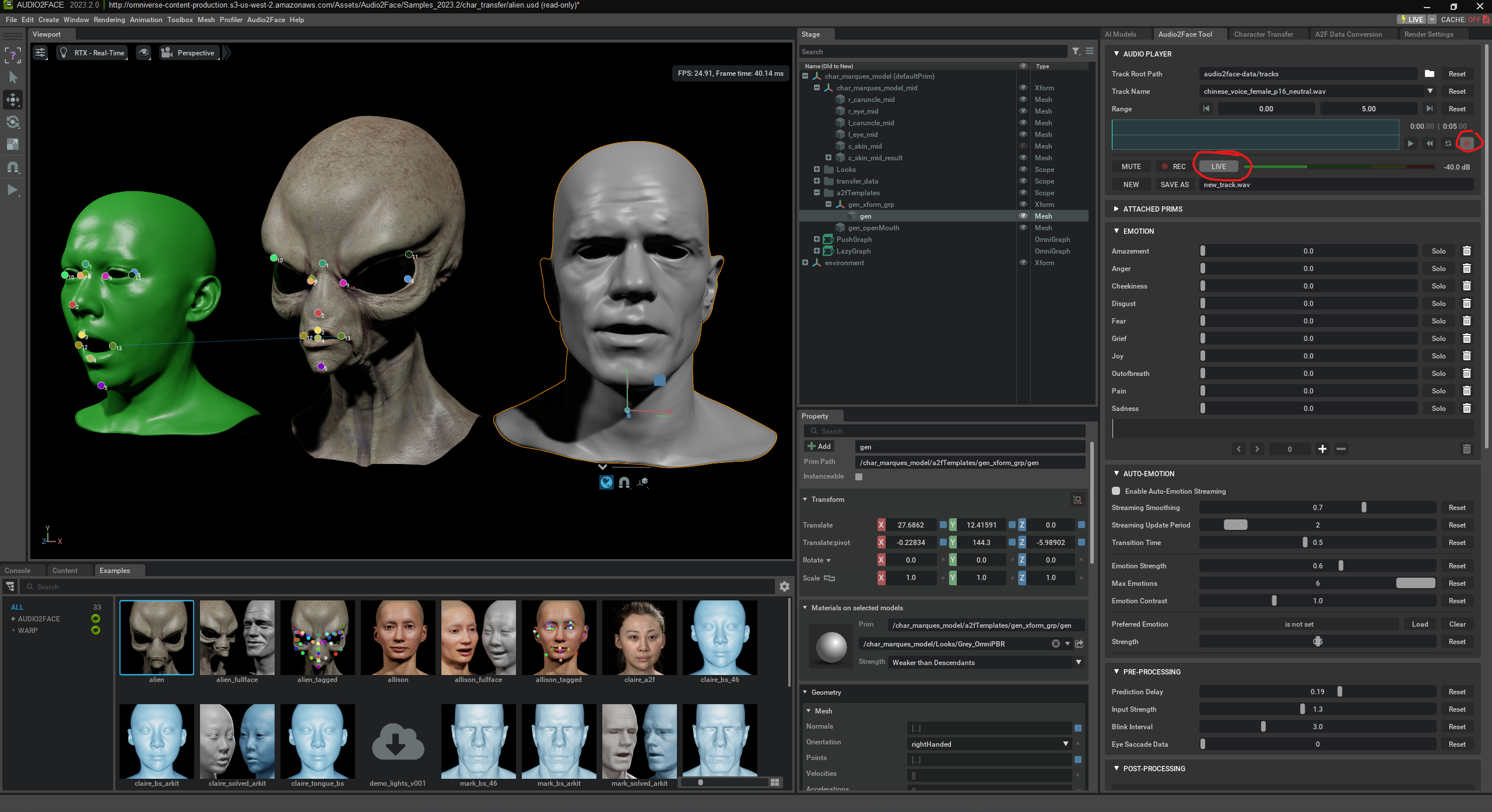
El extraterrestre también puede animarse en tiempo real mediante el habla.