Introducción
En un artículo anterior se describió el proceso de Transfer Learning utilizando el NVIDIA TAO Toolkit. Este enfoque está diseñado principalmente para entrenar modelos de IA en conjuntos de datos específicos no estandarizados (p. ej., detección de defectos industriales).
Para tareas que involucran objetos cotidianos como personas o animales, dicho proceso de entrenamiento a menudo no es necesario. Una alternativa más eficiente es la aplicación directa (inferencia) de modelos preentrenados. En esta entrada se presenta el framework Ultralytics junto con la arquitectura de modelo YOLO11.
¿Qué es Ultralytics?
Ultralytics es una empresa y al mismo tiempo el nombre de un framework de código abierto basado en la biblioteca de deep learning PyTorch. Funciona como una API de alto nivel (interfaz) que abstrae los procesos complejos de visión por computadora.
Si bien frameworks como TensorFlow o PyTorch nativo requieren una definición detallada de la arquitectura de la red neuronal y de los bucles de entrenamiento, Ultralytics proporciona métodos estandarizados para el entrenamiento, la validación y la inferencia. El foco está en la aplicabilidad de los algoritmos YOLO (You Only Look Once). El framework permite la integración en diferentes arquitecturas de hardware (CPU, NVIDIA GPU, Apple Silicon) con un esfuerzo mínimo de configuración, ya que las dependencias y las interfaces de los controladores se gestionan de forma mayormente automatizada.
La arquitectura: YOLO11
YOLO (You Only Look Once) se refiere a una familia de “Single-Stage-Detectors”. A diferencia de los métodos de dos etapas, que primero proponen regiones y luego las clasifican, YOLO analiza toda la imagen en una sola pasada de la red neuronal.
YOLO11 es la iteración vigente de esta arquitectura al momento de redactar este artículo. Las características principales son:
Predicción basada en cuadrícula
La imagen se divide en una cuadrícula. Cada celda de la cuadrícula es responsable de detectar objetos.Detección de objetos
Cajas delimitadoras (rectángulos) alrededor de los objetos.Segmentación de instancias
Enmascaramiento de contornos de objetos a nivel de píxel.Estimación de pose
Detección de puntos clave del esqueleto en personas.
Por qué no es necesario entrenar
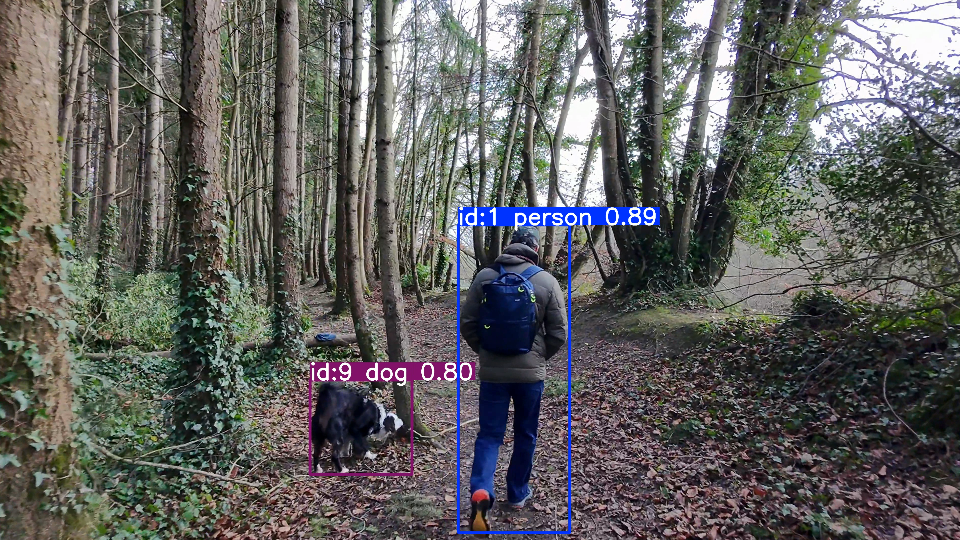
La diferencia clave con respecto al método descrito en el artículo de NVIDIA TAO radica en el conjunto de datos utilizado. El modelo empleado aquí (yolo11l-seg.pt) ya ha sido entrenado exhaustivamente con el conjunto de datos COCO (Common Objects in Context). El conjunto COCO es un estándar en la investigación de visión por computadora y abarca más de 330.000 imágenes, 1.5 millones de instancias de objetos anotados y 80 categorías de objetos (Class ID 0: Persona, Class ID 9: Perro).
Ejemplo
import cv2
from ultralytics import YOLO
# 1. Lade das Modell
# Das Modell wird beim ersten Start automatisch heruntergeladen.
model = YOLO('yolo11l.pt') # 'l' steht für Large = sehr präzise
# 2. Pfad zu deinem Video
video_path = "./videos/walk1.mp4"
cap = cv2.VideoCapture(video_path)
# Video-Eigenschaften für das Speichern
w, h, fps = (int(cap.get(x)) for x in (cv2.CAP_PROP_FRAME_WIDTH, cv2.CAP_PROP_FRAME_HEIGHT, cv2.CAP_PROP_FPS))
out = cv2.VideoWriter('tracked_walk1.mp4', cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
while cap.isOpened():
success, frame = cap.read()
if not success:
break
# 3. Tracking ausführen
# persist=True ist wichtig, damit das Tracking über Frames hinweg funktioniert
# classes=[0, 16] filtert nur nach Person (ID 0) und Hund (ID 16) im COCO-Datensatz
results = model.track(frame, persist=True, classes=[0, 16], conf=0.5)
# 4. Ergebnisse auf das Bild zeichnen
annotated_frame = results[0].plot()
# Anzeigen (Optional - Fenster mit 'q' schließen)
cv2.imshow("Tracking", annotated_frame)
# Speichern
out.write(annotated_frame)
if cv2.waitKey(1) & 0xFF == ord("q"):
break
cap.release()
out.release()
cv2.destroyAllWindows()
print("Fertig! Video wurde als output_tracking.mp4 gespeichert.")