
Introducción
Retrieval Augmented Generation (RAG) es un método de procesamiento de lenguaje natural (PLN), en el que un modelo de lenguaje se combina con conocimiento externo para generar respuestas mejores y más precisas.
Un modelo de lenguaje como GPT no solo se consulta sobre su conocimiento interno (entrenamiento), sino que también recibe información contextual de una fuente de conocimiento externa, por ejemplo, una colección de documentos o una base de datos.
Este artículo explica la configuración y el desarrollo de una canalización RAG en el marco de un proyecto de aprendizaje. El objetivo era crear un sistema que procese el contenido de un documento PDF y permita formular preguntas sobre este documento en un chat interactivo. La aplicación nació del deseo de comprender de forma práctica el funcionamiento y la interacción de los distintos componentes de una aplicación RAG.
Source Code: https://github.com/netperformance/rag/
El documento siguiente sirvió como base para la demostración:
pm-partnerschaft-stackitDescargar
En la terminal se muestra la ejecución de una canalización RAG: se recibe una pregunta del usuario sobre el documento, se procesa y se responde de forma automatizada.
Visualización de los vectores del documento PDF
La gráfica muestra una proyección bidimensional de los vectores calculados a partir de los fragmentos de texto (chunks) de un documento PDF. Cada punto representa un fragmento del documento cuyo embedding se visualiza en un espacio vectorial. Las posiciones de los puntos en el diagrama reflejan las similitudes entre los distintos fragmentos de texto. Los puntos más cercanos representan secciones del documento con contenido más similar entre sí. Mayores distancias indican que las secciones correspondientes están menos relacionadas temática o semánticamente.
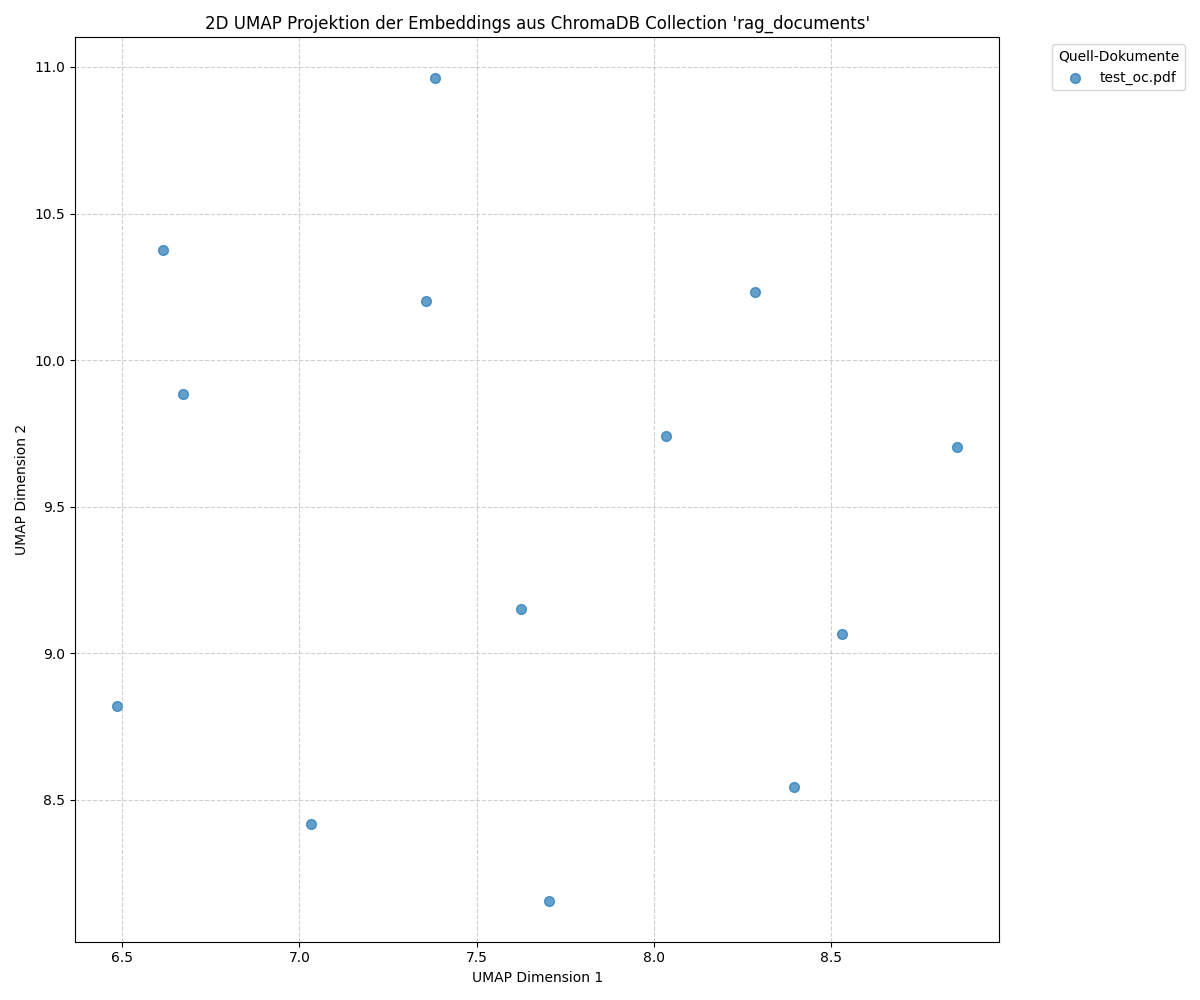
El vector con la coordenada 7.4, 11.0 corresponde al Chunk 1 (■■■ Digitale Service Manufaktur… OPITZ CONSULTING UND STACKIT WERDEN CLOUD-PARTNER… Gummersbach, 1. März 2024)
Pipeline de procesamiento RAG (high level)
Paso 1: Estructuración del PDF
El archivo se analiza con unstructured.io, de modo que se extraen el texto y los elementos de maquetación.Paso 2: Análisis NLP
El texto estructurado se examina para detectar entidades y obtener lemas (NER con BERT, lematización con spaCy).Paso 3: Segmentación (Chunking)
El texto se divide en fragmentos lógicamente coherentes. Se emplea un procedimiento híbrido que combina segmentación basada en reglas y enriquecimiento de contexto asistido por LLM.Paso 4: Vectorización
Cada fragmento se convierte en un vector (intfloat/multilingual-e5-large). Los vectores se almacenan junto con metadatos en ChromaDB.Paso 5: Uso interactivo
Una pregunta del usuario se vectoriza de igual manera. Se recuperan los fragmentos más similares y se utilizan como contexto para que el modelo de lenguaje genere una respuesta.
El siguiente archivo de registro documenta los distintos pasos de procesamiento y sus salidas:
https://github.com/netperformance/rag/blob/main/logging.txt
Arquitectura de la aplicación
La aplicación se basa en una arquitectura de microservicios. Servicios especializados están accesibles a través de sus propias API y se ejecutan en procesos separados. Un orquestador central gestiona la interacción entre los servicios. La siguiente visión general resume los archivos principales del proyecto o servicios y sus funciones:
chatbot.py: Proporciona la interfaz de usuario, recibe solicitudes y coordina la lógica RAG.
start_embedding.py: Orquestador que controla toda la canalización de datos.
language_detection_service.py: Detecta el idioma de un documento.
structuring_service.py: Descompone PDFs en elementos estructurados mediante unstructured.io.
custom_components.py: Conjunto de funciones auxiliares reutilizables.
nlp_processor.py: Encapsula la lógica de NLP (por ejemplo, spaCy).
nlp_service.py: Realiza tareas de NLP como reconocimiento de entidades nombradas y lematización.
deepseek_enrichment_service.py: Interfaz con la plataforma Ollama para respuestas LLM.
embedding_service.py: Crea embeddings vectoriales a partir de texto y los guarda en la base de datos.
visualize_embeddings.py: Visualiza los vectores para analizar la calidad de los embeddings.
clear_chromadb.py: Borra el contenido de la base de datos de vectores para nuevas pruebas.
config.json: Repositorio central de todos los parámetros de configuración, como nombres de modelos y URLs de API.
Stack tecnológico
La aplicación se apoya en numerosas bibliotecas de código abierto especializadas que cubren distintas áreas de responsabilidad.
Infraestructura de API y servicios
FastAPI y Uvicorn conforman la base para las API web asíncronas de los microservicios.
requests gestiona la comunicación interna entre servicios.
python-multipart permite la carga de archivos, por ejemplo, documentos PDF.
Procesamiento de documentos y análisis lingüístico
La canalización comienza con structuring_service.py. Con unstructured[local-inference] y la estrategia hi_res se descomponen documentos PDF en elementos estructurados como títulos, listas y párrafos. PyMuPDF se utiliza internamente para la extracción eficiente de texto.
Para el reconocimiento de texto en imágenes incrustadas se emplea pytesseract.
La identificación de idioma la realiza langdetect.
En el siguiente paso la canalización entrega los datos estructurados a nlp_service.py, que con la ayuda de spaCy (para lematización) y modelos como domischwimmbeck/bert-base-german-cased-fine-tuned-ner (para Named Entity Recognition) extrae metadatos para la búsqueda posterior.
Segmentación y preparación del texto
- Un enfoque híbrido con langchain-text-splitters (RecursiveCharacterTextSplitter) se usa para la segmentación basada en reglas, complementado por un enriquecimiento opcional basado en LLM. Un tamaño de fragmento de 450 caracteres ha resultado ser el compromiso ideal para equilibrar contexto y detalle.
Vectorización y almacenamiento
embedding_service.py convierte los fragmentos de texto en vectores utilizando el modelo intfloat/multilingual-e5-large y las bibliotecas transformers, torch y sentence-transformers.
Estos vectores y metadatos asociados se almacenan en la base de datos de vectores ChromaDB, que permite una búsqueda semántica rápida.
Visualización y herramientas auxiliares
Para el análisis y visualización de los embeddings se dispone de matplotlib y umap-learn para reducir los vectores a dos dimensiones y representarlos.
numpy se utiliza para operaciones numéricas.
Con json_repair se pueden corregir salidas JSON erróneas de los modelos de lenguaje, aumentando la robustez de la canalización.
Consideraciones para el entorno productivo
Para el uso en un entorno productivo se requieren las siguientes adaptaciones:
Comunicación asíncrona
En lugar de llamadas REST directas que pueden bloquear el orquestador, se debería implementar una comunicación asíncrona mediante un bus de mensajes como RabbitMQ o Kafka. La canalización de ingestión incluiría entonces pasos de procesamiento secuenciales y desacoplados: tras la finalización, structuring_service publica un mensaje en la cola, nlp_service lo procesa y luego pasa el resultado a embedding_service. Este desacoplamiento aumenta la resiliencia y permite una escalabilidad flexible.
Manejo de errores y mecanismos de reintento
Para gestionar fallos temporales de servicios individuales se necesita manejo de errores con reintentos automáticos, por ejemplo mediante backoff exponencial. Así se pueden mitigar problemas de red o interrupciones de servicios sin detener toda la canalización.
Model Control Plane (MCP)
En el proyecto de prueba se prescindió deliberadamente de una MCP. Sin embargo, en un entorno productivo es necesaria una capa de control centralizada.
Escalabilidad y balanceo de carga
Los servicios deberían ejecutarse en contenedores y orquestarse con una plataforma como Kubernetes. Esto permite escalar independientemente componentes especialmente cargados, como el servicio de embeddings o el LLM. Los equilibradores de carga distribuyen equitativamente las solicitudes entre varias instancias.
Monitoreo y alertas
Es necesario un monitoreo continuo de todos los servicios en cuanto a carga, tasas de error y latencia. Soluciones de monitoreo como Prometheus y Grafana ayudan a detectar problemas de forma temprana e iniciar las acciones correctivas correspondientes.
Aspectos de seguridad
La protección de los endpoints de API es imprescindible. Esto incluye métodos de autenticación como API-Keys, JWT u OAuth2, para restringir el acceso a clientes autorizados. Una capa de autorización define qué acciones puede realizar un cliente autenticado. Toda la comunicación entre servicios debe cifrarse para garantizar la confidencialidad e integridad de los datos transmitidos.