RAG
Retrieval-Augmented Generation (RAG) es hoy un método ampliamente utilizado para conectar modelos de lenguaje grandes con conocimiento externo. Antes de hablar de desarrollos posteriores como REFRAG, es conveniente comprender de forma clara el proceso de un sistema RAG clásico.
El diagrama siguiente muestra el proceso estándar. Los pasos están agrupados por colores, numerados y se pueden dividir bien en cuatro áreas:
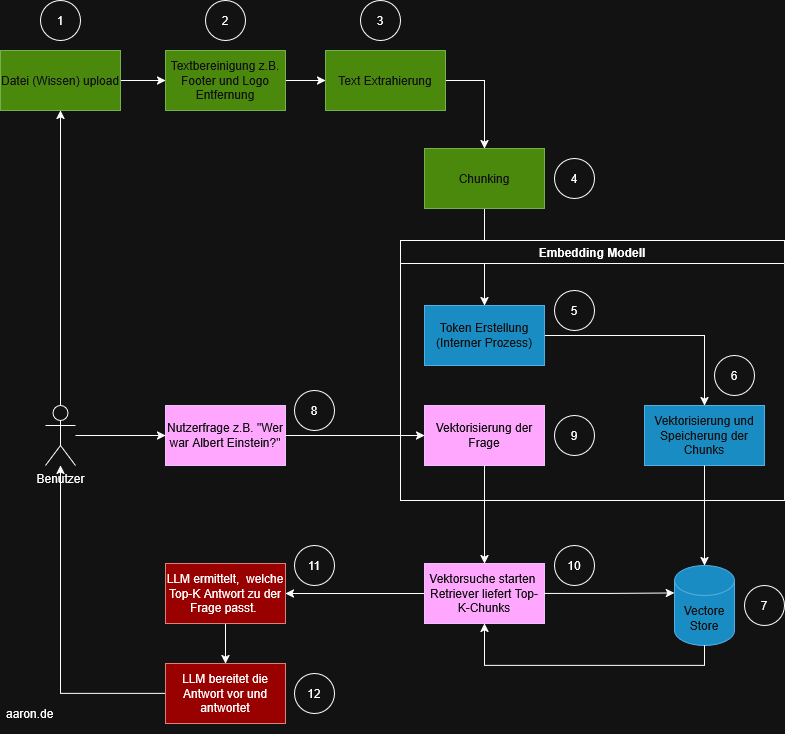
Descripción del proceso RAG
- Pasos 1 - 4: Preprocesamiento (preparación de datos)
- Pasos 5 - 7: Embedding
- Pasos 8 - 10: Recuperación
- Pasos 11 - 12: Generación
Preprocesamiento (verde)
Esta área prepara la base de conocimientos para la posterior recuperación.
(1) Carga de archivos: Un usuario carga un documento como p. ej. un PDF, Word, una exportación de sitio web u otras fuentes de conocimiento. Este es el punto de entrada para todos los pasos de procesamiento posteriores.
(2) Limpieza de texto: Preprocesamiento como eliminación de pies de página, logotipos o elementos irrelevantes. Este paso garantiza que luego solo se vectoricen los contenidos realmente relevantes.
(3) Extracción de texto: El contenido depurado se extrae como texto puro. Este texto fluye luego en el proceso de Chunking.
(4) Chunking: El texto se divide en secciones más pequeñas y manejables (Chunks). Razón: los modelos de embedding tienen límites de tokens, y los Chunks más pequeños mejoran la precisión de recuperación.
Embedding (azul)
Este bloque constituye el núcleo del sistema RAG e incluye tanto la vectorización como el almacenamiento y la búsqueda.
(5) Creación de tokens (proceso interno): El modelo de embedding divide internamente el texto en tokens. Este paso no es visible para el usuario, pero es necesario para generar vectores posteriormente.
(6) Vectorización de los Chunks: Cada Chunk se convierte en un vector numérico. Estos vectores representan significado semántico, lo que permite encontrar posteriormente contenidos similares.
(7) Almacenamiento en el Vector Store: Todos los vectores se guardan de forma persistente. El Vector Store es una base de datos de vectores separada.
Recuperación (rosa)
(8) Pregunta del usuario: El usuario formula una pregunta, p. ej., „¿Quién fue Albert Einstein?“.
(9) Vectorización de la pregunta: La pregunta del usuario se traduce al mismo espacio semántico que los Chunks. Solo así el sistema puede identificar contenidos similares.
(10) Búsqueda vectorial: El recuperador busca en el Vector Store los Chunks semánticamente más adecuados. El resultado es una lista Top-k, normalmente los 3–10 fragmentos de texto más relevantes.
Generación (rojo)
(11) El LLM selecciona la base de respuesta adecuada: El LLM recibe tanto la pregunta original como los Chunks encontrados. Analiza qué información de los Chunks responde mejor a la pregunta.
(12) Formulación de la respuesta: El modelo elabora una respuesta, basándose en el contexto encontrado. Así se reduce el riesgo de alucinaciones, ya que el modelo solo recurre a las fuentes proporcionadas.
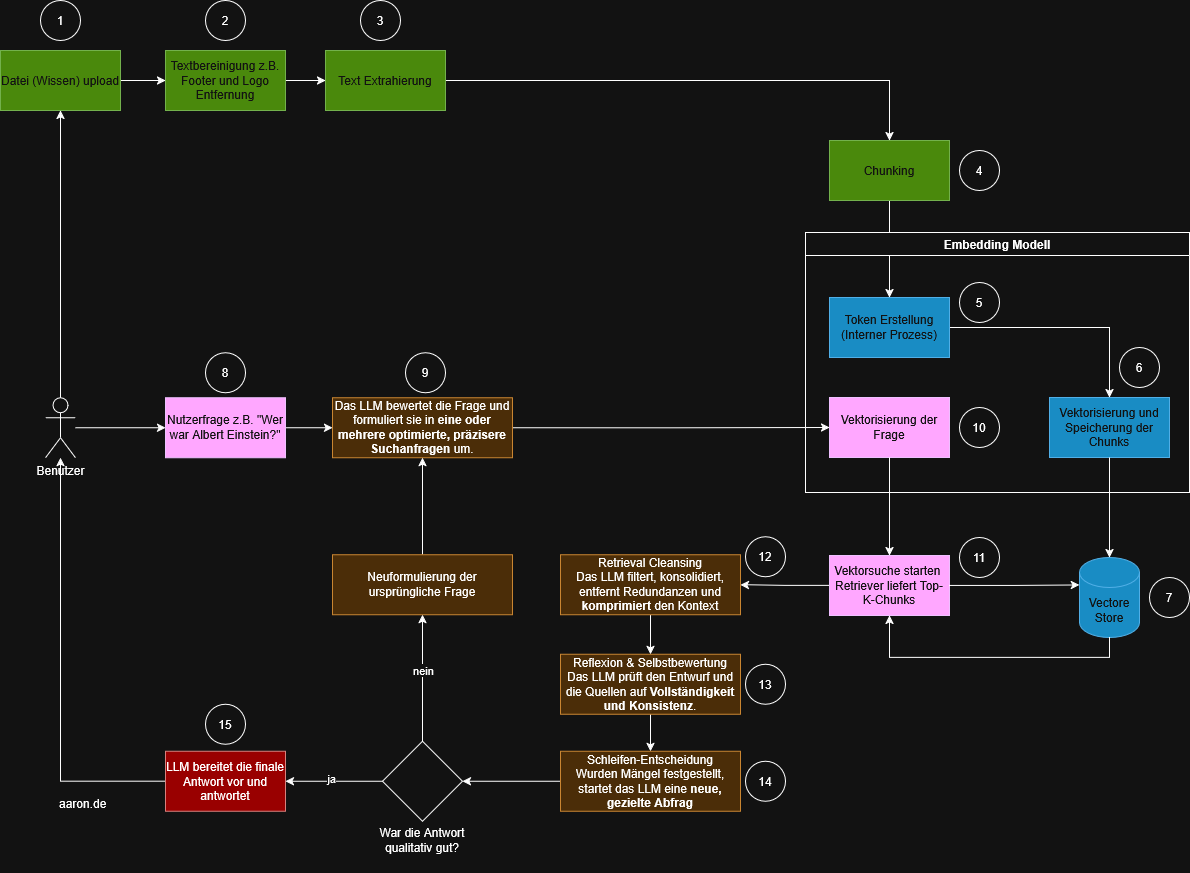
REFRAG: La extensión de las estrategias de recuperación y generación
REFRAG (Retrieval-Augmented Re-generation) no es una arquitectura independiente, sino un desarrollo posterior de la canalización RAG que tiene como objetivo mejorar la calidad de los Chunks Top-K y la fiabilidad de la respuesta.

Una vez que el proceso RAG clásico está claro, se puede ver con nitidez en qué puntos actúa REFRAG. Ambos métodos utilizan la misma base. Incluye la preparación de datos, el Chunking, los embeddings y la recuperación. El cambio real surge en la forma en que se procesa la pregunta del usuario y en cómo el modelo maneja el contexto devuelto.
REFRAG complementa el proceso lineal RAG con una capa intermedia multinivel controlada por el modelo. Esta capa garantiza que las consultas se optimicen, el contexto sea más coherente y se controle la calidad del resultado. De este modo no surge un nuevo núcleo técnico. En su lugar, se añade un nivel lógico adicional que funciona por encima de la recuperación y de la respuesta final.
Cómo REFRAG amplía el proceso RAG
En los pasos de uno a siete todo permanece sin cambios. Las diferencias comienzan en el momento en que el usuario formula su pregunta. Mientras que RAG vectoriza la pregunta directamente y la convierte en una búsqueda vectorial, REFRAG introduce en este punto una capa de evaluación.
Paso 9: Evaluación y optimización de la pregunta original
En vez de vectorizarse de inmediato, el modelo analiza la pregunta y formula a partir de ella una consulta de búsqueda más precisa. Según el tipo de pregunta, pueden surgir varias variantes. Entre ellas se incluyen preguntas más acotadas, variantes con información complementaria esclarecedora o formulaciones técnicamente más precisas. El propósito de esta reformulación está claro. La calidad de los resultados debe mejorarse ya antes de crear los embeddings.
Paso 10: Vectorización de la consulta optimizada
Ahora ya no se vectoriza la pregunta original. En su lugar, se utiliza la versión optimizada. Esta distinción es fundamental porque influye en la calidad de los resultados de la búsqueda de similitud posterior.
Paso 12: Limpieza de recuperación
Los Chunks recuperados se filtran, depuran y resumen. El modelo elimina repeticiones, destaca contenidos relevantes y reduce el material a lo esencial. Así, el LLM obtiene un espacio de trabajo más consistente y menos redundante.
Paso 13: Reflexión y autoevaluación
El modelo comprueba si el contexto generado es completo y lógico. Se verifica si faltan informaciones importantes, si los contenidos son contradictorios o si serían necesarias formulaciones alternativas.
Paso 14: Decisión de bucle
En este punto ambos procesos difieren claramente. Si el modelo detecta que faltan informaciones o que son poco claras, genera una nueva consulta. La pregunta revisada conduce de nuevo al paso 9 y el proceso se inicia otra vez.
Paso 15: Finalización de la respuesta
Solo cuando la evaluación interna determina que la respuesta es completa y coherente, se formula y se devuelve al usuario. Mientras que RAG recupera el contexto solo una vez y responde de inmediato, REFRAG asegura que se detecten y corrijan las deficiencias de calidad.
Conclusión
REFRAG no reemplaza a RAG. En cambio, amplía el proceso con una capa impulsada por el modelo de control de calidad y optimización de información. El núcleo técnico sigue siendo el mismo. Los archivos se procesan, dividen en Chunks, vectorizan y almacenan en el Vector Store. La diferencia radica en la forma en que el sistema maneja de manera inteligente el contexto recuperado.
REFRAG evalúa la pregunta, la optimiza y comprueba el contexto recuperado antes de que se genere la respuesta. Por ello, RAG es adecuado para aplicaciones simples y rápidas. REFRAG tiene sentido cuando se requieren precisión, consistencia y un contexto verificado