RAGFlow es un framework para la implementación estructurada de aplicaciones de Retrieval Augmented Generation (RAG). Ofrece una arquitectura modular en la que pasos de procesamiento individuales como la importación de documentos, el preprocesamiento de texto, la vectorización, la indexación y la generación de respuestas se pueden configurar y ejecutar por separado.
Models
La plataforma admite diferentes soluciones de almacenamiento para datos vectoriales y permite la conexión de varios LLM. La lista de LLM compatibles se puede encontrar aquí.
| Columna | Significado |
|---|---|
| Provider | Proveedor o fuente del modelo. Puede ser un servicio en la nube (p.ej. OpenAI) o un desarrollador de modelos (p.ej. Cohere, BAAI). |
| Chat | Admite modelos de lenguaje orientados al diálogo, que se utilizan para conversación o generación de respuestas. |
| Embedding | Proporciona modelos de embeddings para convertir textos en vectores para búsqueda semántica o clasificación. |
| Rerank | Modelos para reordenar resultados ya obtenidos, de modo que los más relevantes aparezcan primero. |
| Img2txt | Modelos de descripción de imágenes: convierten una imagen en un texto descriptivo. |
| Speech2txt | Modelos para convertir lenguaje hablado en texto escrito (ASR - Automatic Speech Recognition). |
| TTS | Texto a voz (TTS): convierte texto escrito en voz sintética. En la tabla, aún sin soporte. |
OpenAI no ofrece soporte para la función „Rerank“.

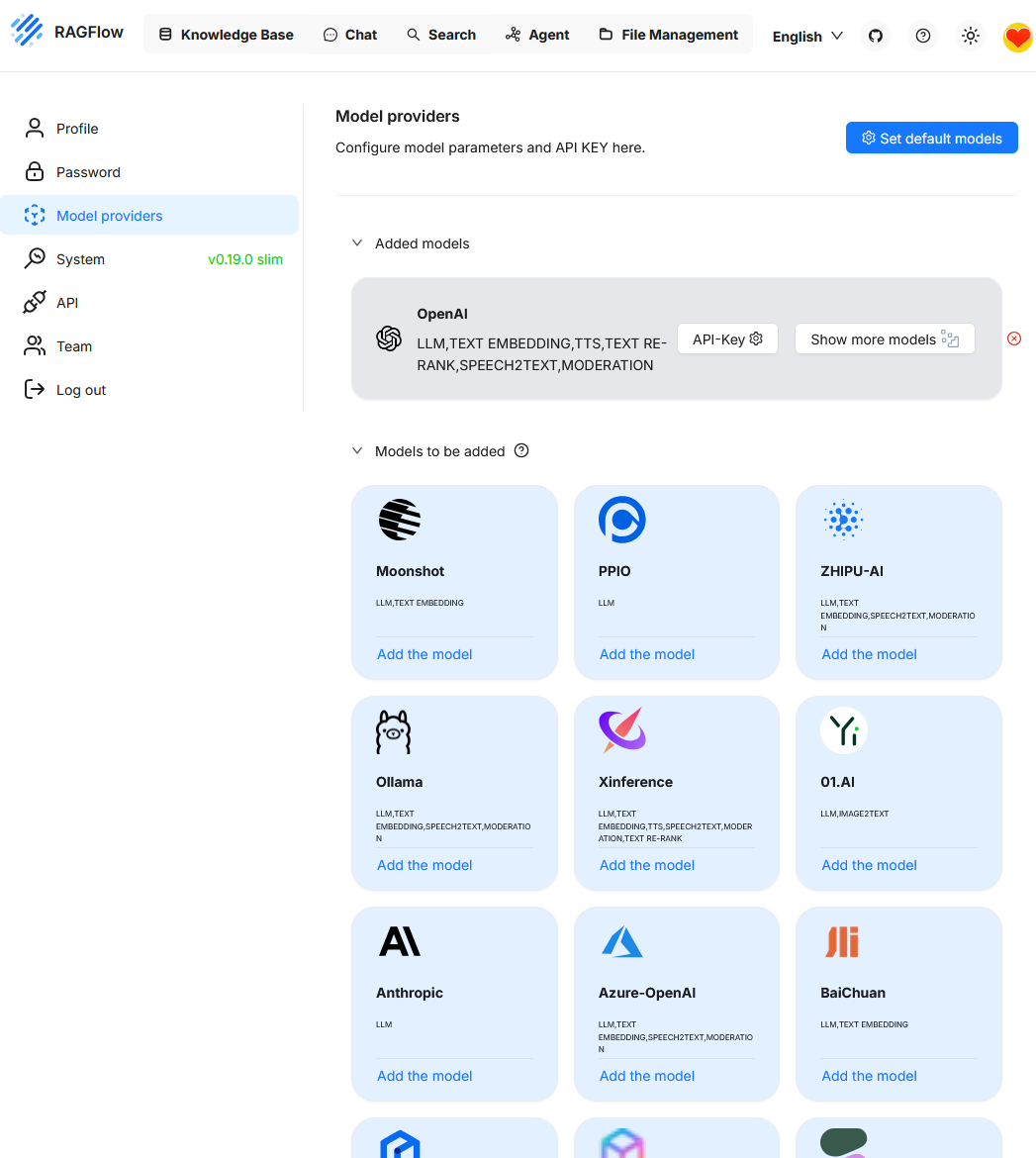
En este ejemplo solo se ha integrado hasta ahora el modelo de OpenAI. Otros modelos como p.ej. Ollama, pueden añadirse si es necesario.

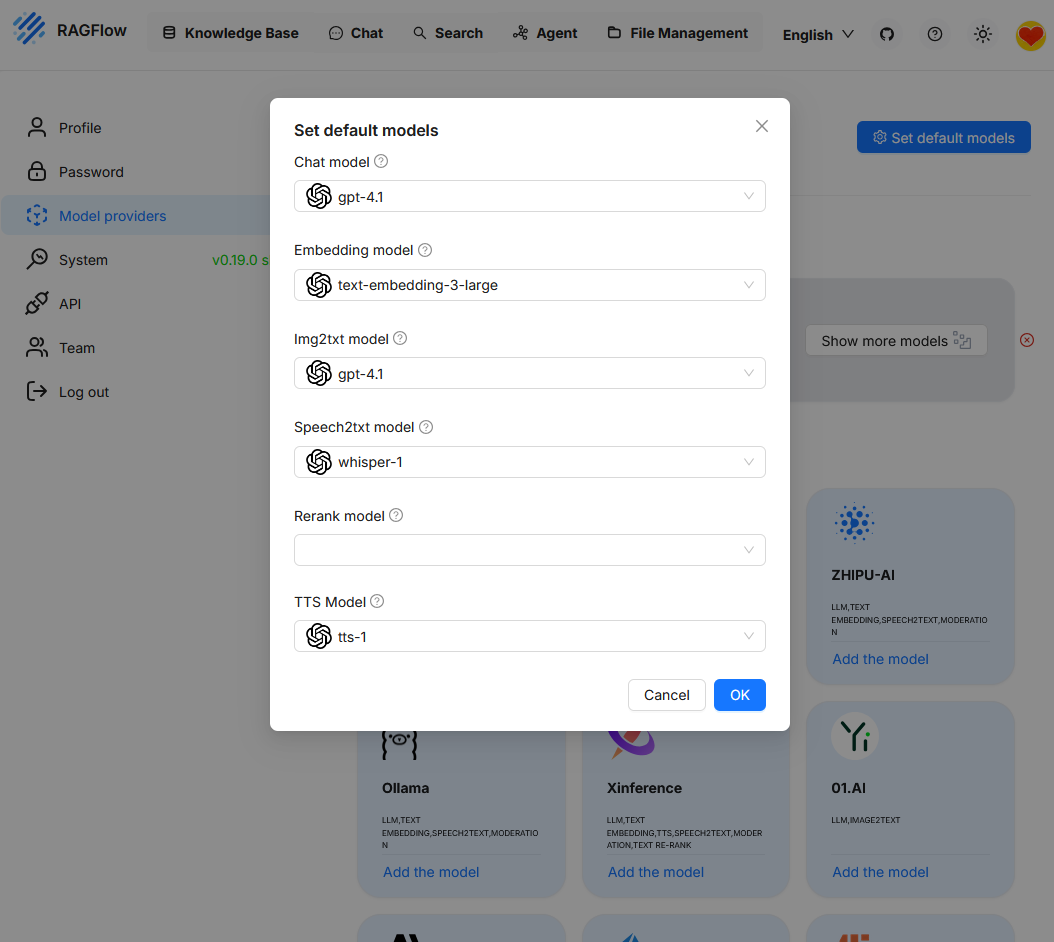
Al invocar „Set default models“ se muestra la configuración de modelo actualmente activa. Dado que hasta ahora solo se ha integrado „OpenAI“ como proveedor, actualmente sólo este modelo está disponible para seleccionar. Para poder utilizar funciones adicionales como el re-ranking, primero debe añadirse otro modelo.
Knowledge Base (NB)
En RAGFlow, la Knowledge Base es el repositorio central para los contenidos que se buscan en las consultas y se utilizan como base para las respuestas generadas. Está compuesta por fragmentos vectorizados extraídos de documentos importados y está directamente conectada a los componentes de recuperación y clasificación.
Al crear una Knowledge Base se puede seleccionar un modelo de embedding que se empleará para vectorizar los contenidos. Esta elección es vinculante. No está previsto cambiar el modelo después de la creación. Si se desea usar otro modelo, hay que crear una nueva Knowledge Base e importar de nuevo los datos.
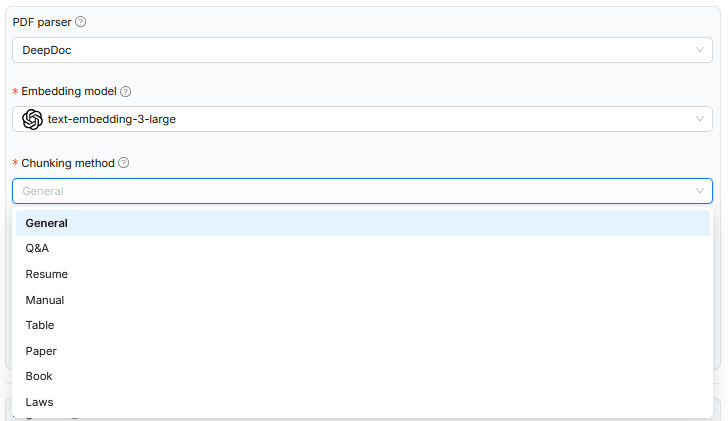
En el ejemplo mostrado, al subir un documento a RAGFlow se definió el método de chunking para dividir la estructura del texto en unidades más pequeñas de forma lógica. Según el tipo de documento elegido, como trabajos científicos, textos legales o tablas, se aplica una base de reglas adecuada para la segmentación. Este control afecta únicamente a la división lógica del documento y determina cómo se almacenan posteriormente los fragmentos en el espacio semántico. El modelo de embedding utilizado sigue siendo el mismo en todos los casos y no está especializado para un tipo de documento concreto. Tampoco se ajusta dinámicamente el system prompt, que define el contexto para el modelo de lenguaje. El procesamiento se adapta formalmente a la estructura del texto, pero no al dominio específico del contenido.
Una posible mejora sería considerar el tipo de documento seleccionado no solo para la lógica de chunking, sino también para la elección de modelos especializados. En documentos jurídicos, por ejemplo, se podrían emplear modelos de embedding entrenados en lenguaje y estructuras legales. Alternativamente, se podrían añadir system prompts formulados de manera sistemática para ayudar al modelo a contextualizar mejor los fragments, por ejemplo con referencias a leyes, líneas de argumentación o afirmaciones normativas. También la inclusión de ontologías específicas del dominio podría mejorar la inserción semántica y las consultas posteriores. Especialmente en textos formales como leyes o normas técnicas, así se podrían modelar explícitamente relaciones, definiciones de términos y estructuras globales. De este modo, el proceso de procesamiento tendría en cuenta no solo los aspectos formales, sino también la profundidad semántica y el conocimiento específico del dominio.
Dataset
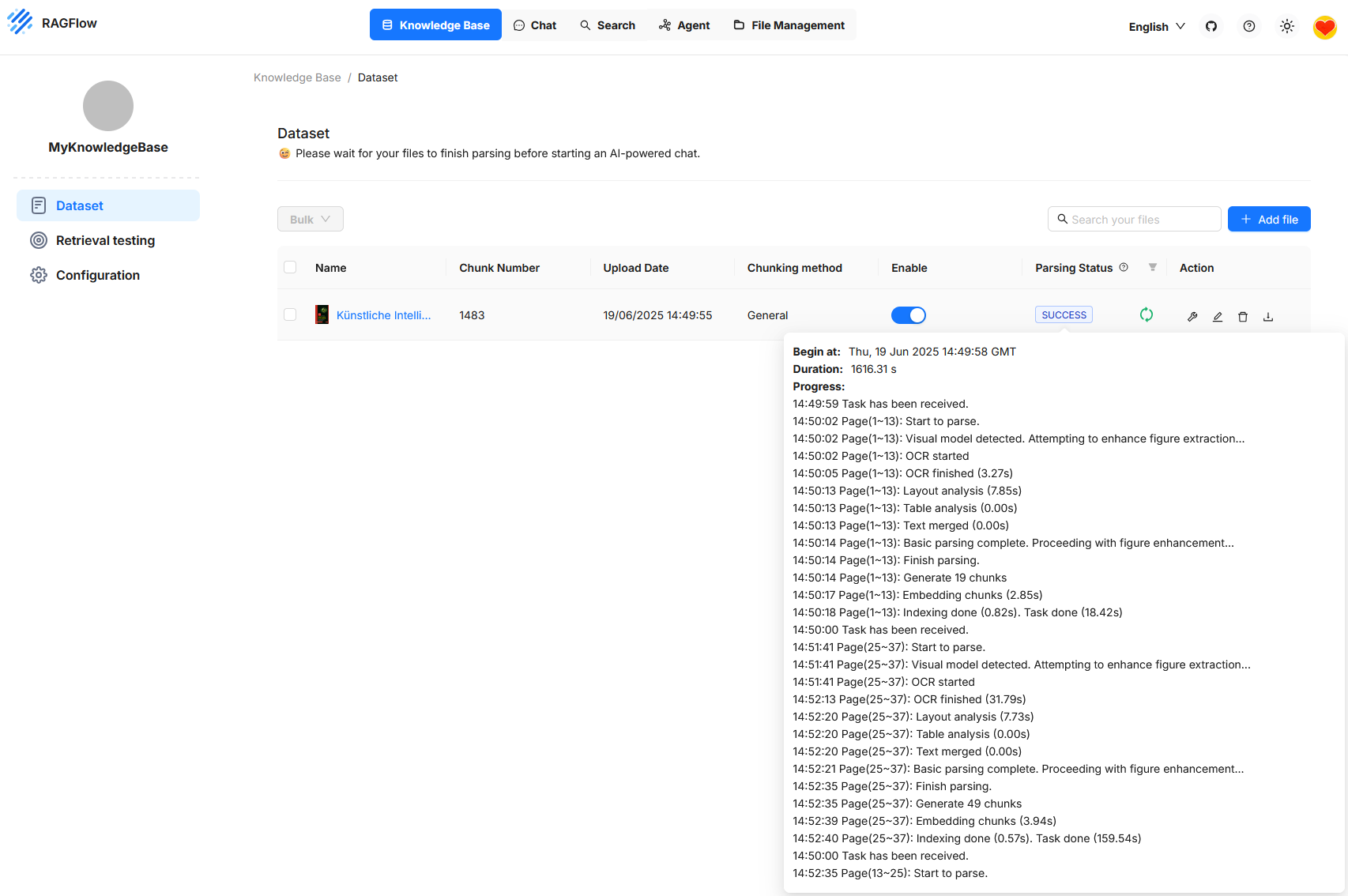
La ilustración muestra la interfaz de usuario de RAGFlow en la sección de Knowledge Base, concretamente en Dataset. Se muestra un documento que se ha subido y procesado correctamente. El estado indica que el procesamiento ha finalizado y que el documento ya está disponible para consultas. El procesamiento abarca varios pasos, como reconocimiento de texto, análisis de diseño, segmentación en fragments y la inserción de estos fragments en el espacio vectorial. Se muestra el número de fragments generados, así como un registro detallado de los pasos de procesamiento, que puede usarse para control y análisis de errores. Mientras el procesamiento está en curso, RAGFlow avisa de que un chat basado en IA solo es recomendable una vez finalizados todos los pasos.
Retrieval Testing
En „Retrieval Testing“ se puede comprobar si el sistema encuentra correctamente fragments relevantes de una Knowledge Base existente para una pregunta concreta del usuario. En el campo de prueba inferior izquierdo, por ejemplo, se introdujo la pregunta „¿Cómo se llama el libro?“. En el lado derecho se muestran las respuestas encontradas. Los valores de similitud para cada fragmento aparecen triplicados: Hybrid Similarity, Term Similarity y Vector Similarity.
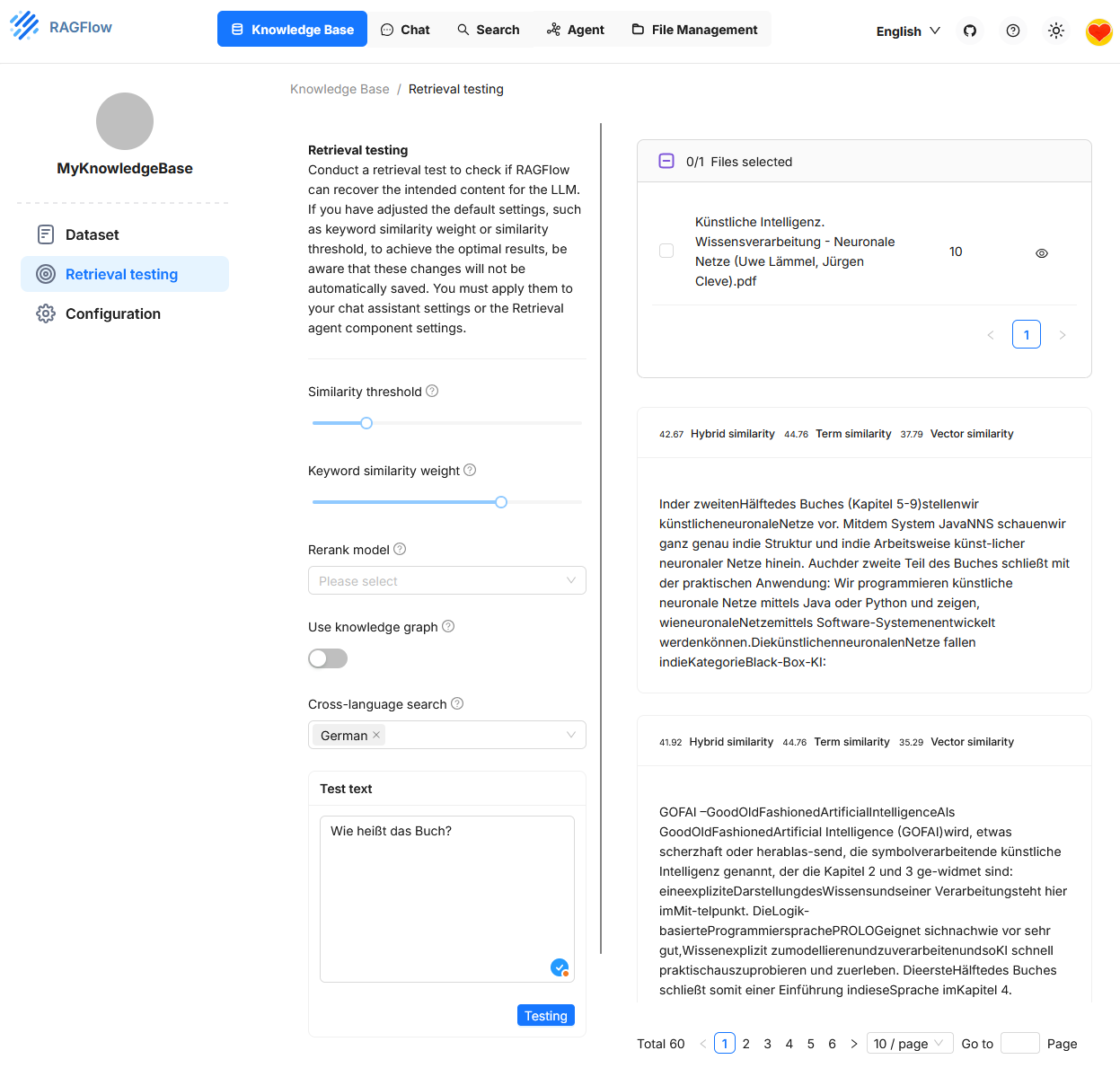
Este entorno de prueba sirve para ajustar con precisión la configuración de recuperación. Permite cambiar distintos parámetros de forma dirigida para mejorar la calidad de la selección de resultados. El efecto de los ajustes se muestra inmediatamente. Sin embargo, la configuración solo se aplica temporalmente a la prueba de recuperación. Para que también se utilice en el chat real o en un agente, debe adoptarse por separado.3,
KB-Parameter
Vector Similarity
Vector Similarity se basa en la representación semántica de los textos en un espacio vectorial de alta dimensión. Cada fragmento de texto y cada consulta de usuario se convierte en un vector numérico mediante un modelo de embedding (p.ej., OpenAI, Cohere). La similitud entre dos vectores se calcula típicamente mediante la similitud del coseno.
- Vorteil: Captura similitudes de significado incluso con distinta elección de palabras. Así el sistema reconoce que „¿Qué es inteligencia artificial?“ y „¿De qué trata la IA?“ son semánticamente similares, aunque no compartan palabras clave.
- Nachteil: La similitud vectorial pura puede ser imprecisa en textos breves o con términos muy específicos de un dominio, especialmente si el modelo de embedding no los representa correctamente.
Term Similarity
Term Similarity evalúa la coincidencia léxica entre la consulta y el fragmento de texto. El método suele basarse en la comparación de tokens, p.ej., con TF-IDF, BM25 o similitud de Jaccard.
- Vorteil: Ofrece resultados precisos cuando se buscan términos o nombres concretos, como en preguntas tipo „¿Qué dice Müller en el capítulo 3?“.
- Nachteil: Ignora sinónimos y relaciones semánticas. Una búsqueda puramente terminológica no reconoce similitud de significado entre „casa“ y „edificio“.
Hybrid Similarity
Hybrid Similarity combina varias métricas de similitud en un valor global. En RAGFlow suele ser una combinación ponderada de Vector Similarity y Term Similarity. Alternativamente, puede incluirse un modelo de re-ranking si está activado.
- Vorteil: Une similitud semántica y léxica. Esto da resultados más robustos en casos reales, p.ej., con documentos heterogéneos o preguntas ambiguas.
- Nachteil: En ciertas situaciones puede resultar menos transparente, ya que la ponderación influye fuertemente en el resultado.
Configuration
En esta sección se definen las propiedades centrales que determinan cómo se procesan, dividen y ponen a disposición de las consultas semánticas los documentos. La configuración incluye ajustes estructurales y funcionales. En el lado izquierdo se ofrecen campos de entrada y opciones de control para ajustar el procesamiento de textos y metadatos. A la derecha se muestra visualmente, mediante el ejemplo del método „General“, cómo se dividen primero los textos en segmentos y luego se agrupan en fragments. Esta sección permite un control preciso del comportamiento durante el parsing y la vectorización y resulta especialmente relevante cuando se deben tener en cuenta tipos de documento o casos de uso específicos.
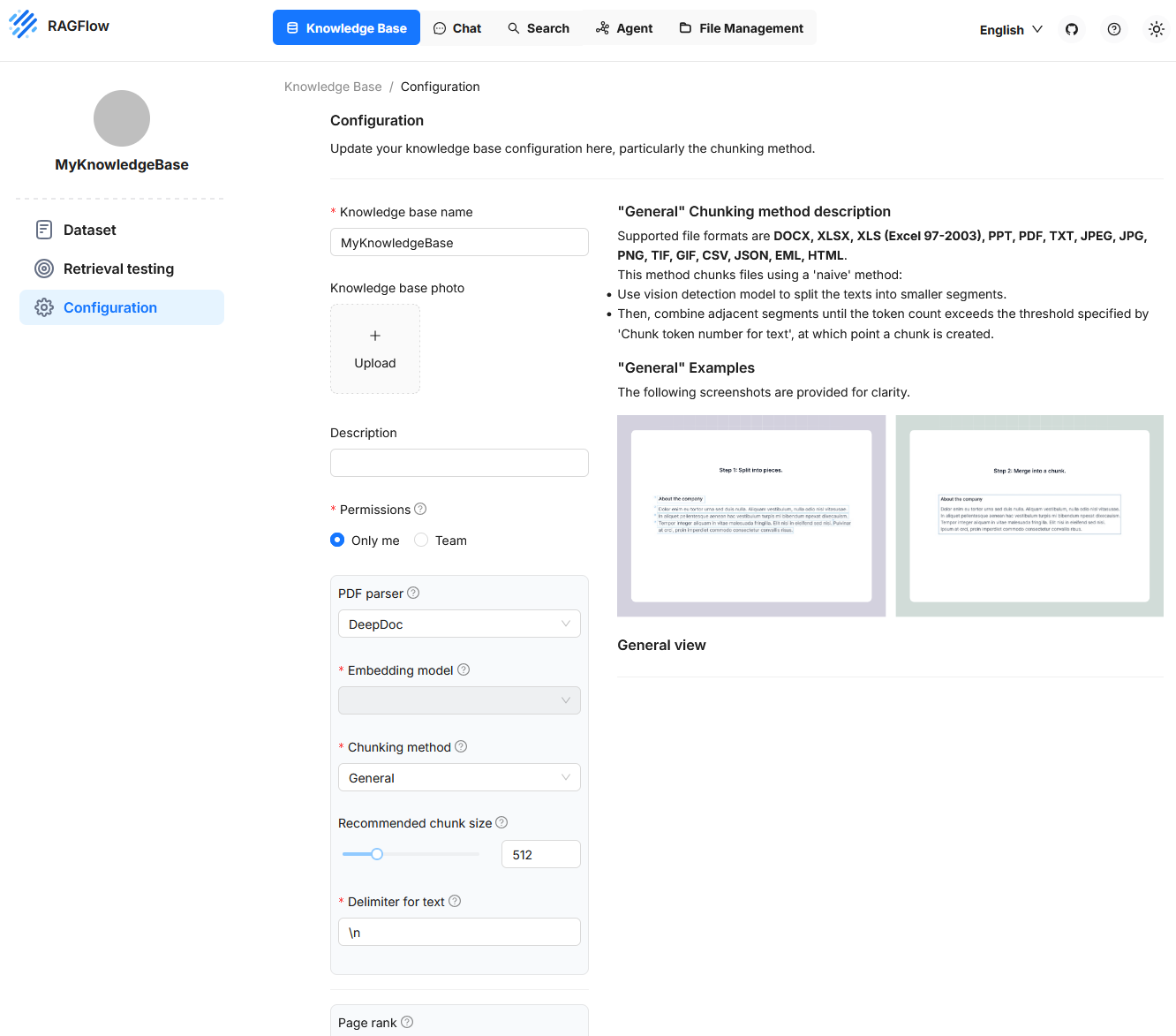
Recommended Chunk Size
Este valor define cuántos tokens debe contener aproximadamente un fragmento. Si un segmento del documento tiene menos tokens que este umbral, se fusiona con los segmentos siguientes hasta superar el límite definido. Solo entonces se crea un nuevo fragmento, y no se forma uno nuevo mientras no se detecte un separador explícito. Este ajuste influye en la compactación o resolución fina de los contenidos de la Knowledge Base en las consultas posteriores.
Delimiter for Text
Un delimitador es un carácter o cadena especial que sirve de señal de separación entre secciones de texto. Ejemplos son saltos de línea o marcadores personalizados como ## o ciertas secuencias de signos de puntuación.
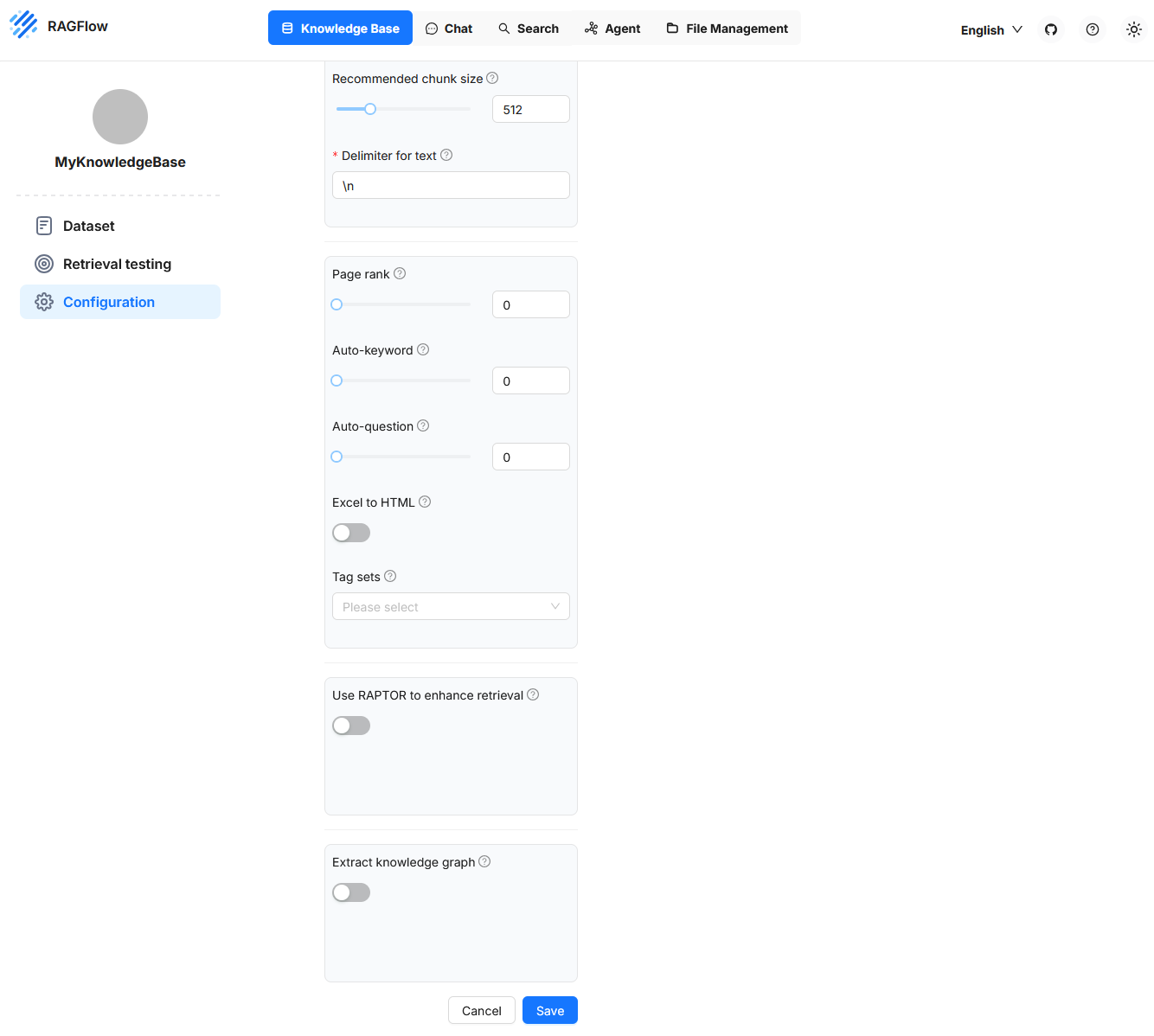
Page Rank
Con este ajuste se puede priorizar una Knowledge Base. Un valor de Page Rank más alto hace que los contenidos de esa fuente se prefieran entre resultados competidores. El valor se suma a la similitud calculada y afecta así el orden de los resultados. De este modo se pueden ponderar fuentes de datos concretas, por ejemplo si se consideran especialmente fiables.
Auto-Keyword
Esta función hace que se generen automáticamente palabras clave para cada fragmento. Estos términos pueden ayudar más adelante en la consulta al aumentar la probabilidad de acierto en preguntas con palabras coincidentes. La extracción la realiza un modelo de lenguaje y requiere recursos de cómputo adicionales. Las palabras obtenidas se pueden revisar y ajustar si es necesario. Un valor de p.ej. 2 significa que se generan dos palabras clave por fragmento.
Auto-Question
Con esta opción se generan automáticamente posibles preguntas a partir del contenido de un fragmento. Sirven para aumentar la relevancia del fragmento en consultas de usuario adecuadas. Esta función también emplea un modelo de lenguaje y tolera errores: si no se consigue generar una pregunta, el fragmento permanece. Las preguntas pueden revisarse y completarse o corregirse manualmente si se desea.
Excel to HTML
Este ajuste afecta al procesamiento de archivos Excel. Si la opción está desactivada, los contenidos se interpretan como pares clave-valor. Si está activada, las tablas se convierten en estructuras HTML. Las tablas con más de doce filas se dividen en varios bloques. Esta estructuración es útil cuando se desea conservar el formato de tabla en la presentación de resultados.
Tag Sets
Esta función permite etiquetar fragmentos de texto con palabras clave de un vocabulario predefinido. Dicho vocabulario puede incluir, por ejemplo, entradas como Datos personales, Derecho contractual, Derecho laboral, Obligaciones fiscales. Al procesar un documento con contenido jurídico, el sistema comprueba para cada fragmento si contiene alguno de estos términos o se corresponde semánticamente con ellos.
Los fragmentos se forman independientemente del Tag Set según la configuración de chunking. El etiquetado se realiza tras la creación de los fragments. Si un fragmento contiene un término del Tag Set o es semánticamente equivalente, se le asigna la etiqueta correspondiente. Este etiquetado añade metadatos estructurados al fragmento, que luego pueden tenerse en cuenta en las búsquedas. Así se puede filtrar, por ejemplo, por todos los fragments con la etiqueta Datos personales o ponderarlos más al evaluar relevancia. La asignación se basa en un vocabulario fijo y controlado, y difiere claramente del procedimiento Auto-Keyword, en el que un modelo de lenguaje extrae de manera autónoma términos relevantes del texto sin atarse a una lista predefinida.
Extract knowledge graph
La función Extract knowledge graph crea automáticamente un grafo de conocimiento a partir de los fragments de una Knowledge Base. Se extraen entidades, relaciones y sus conexiones y se almacenan de forma estructurada. El objetivo es hacer visibles y accesibles de forma automática las relaciones lógicas entre términos y afirmaciones.
Este grafo permite responder consultas complejas que requieran enlazar lógicamente información de varios fragments. Esto es especialmente relevante en preguntas de tipo multi-hop, donde la respuesta no está en un único fragmento, sino distribuida en varios y conectada lógicamente.
La extracción se realiza mediante un modelo durante o después del parsing. Si activas esta función, RAGFlow analiza automáticamente los fragments buscando patrones típicos como estructuras sujeto-predicado-objeto, dependencias causales o asignaciones jerárquicas. Los resultados se integran en una estructura de grafo que sirve de base para procesos de recuperación más precisos y estructurados.
Esta función sienta las bases para la activación posterior de RAPTOR, que usa este grafo para generar respuestas lógicas encadenadas.
Use RAPTOR to Enhance Retrieval
La función Use RAPTOR to enhance retrieval en RAGFlow activa un método avanzado de consulta que se basa en el uso de un grafo de conocimiento. Este grafo debe haberse generado previamente con Extract knowledge graph.
Un mecanismo de recuperación clásico busca en la consulta de usuario los fragments que mejor coinciden con la pregunta. Estos fragments se evalúan individualmente, se ordenan y se pasan al modelo de lenguaje para generar la respuesta. Cada fragmento se trata por separado.
RAPTOR amplía este mecanismo: en lugar de evaluar solo fragments individuales, el sistema analiza las relaciones entre varios fragments a través del grafo. Realiza así encadenamientos lógicos multi-etapa. Esto significa que puede encontrar una respuesta incluso si la información relevante está distribuida en varios fragments y debe conectarse lógicamente.
Chat
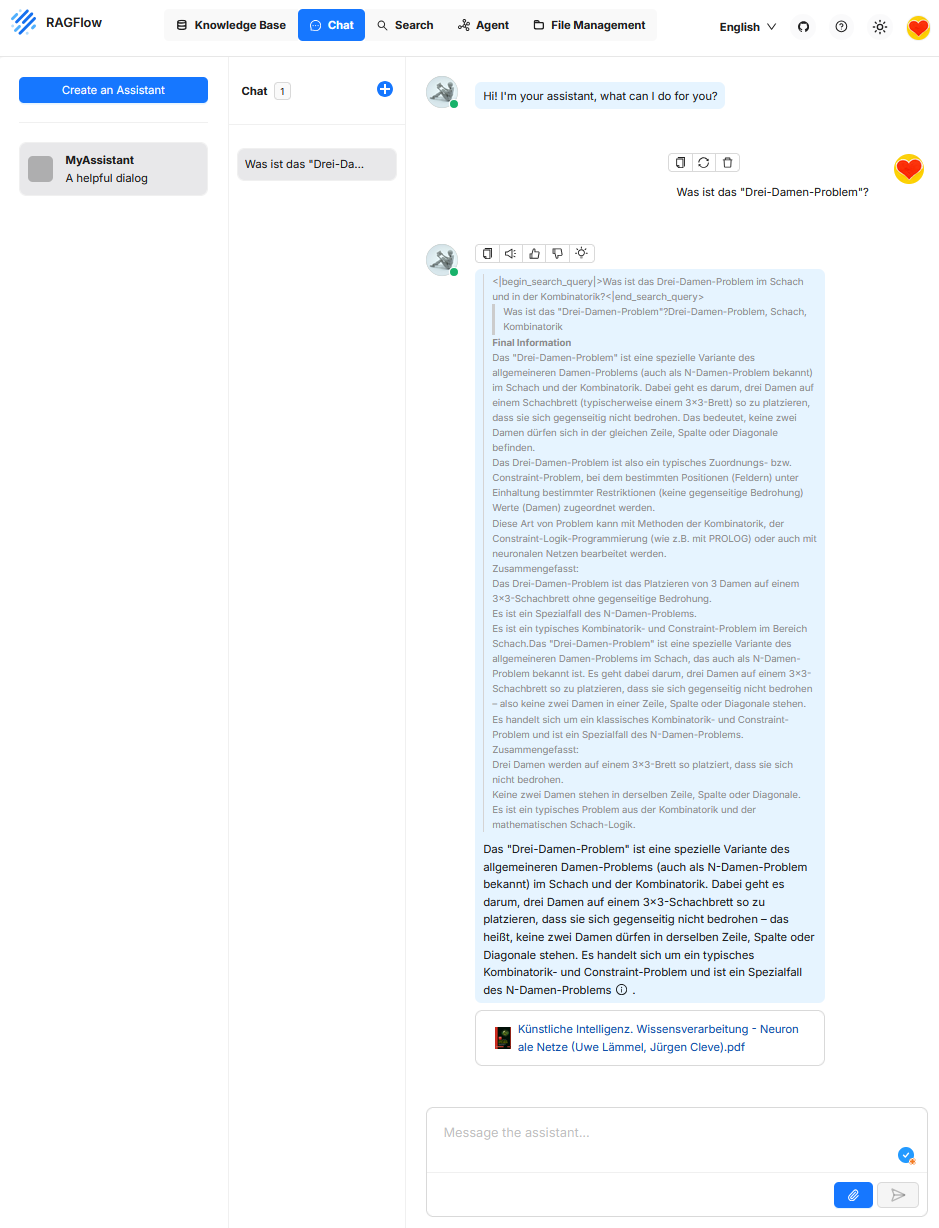
La función „Chat“ sirve de interfaz de usuario para consultas interactivas en un sistema apoyado por recuperación. Se recibe una entrada en lenguaje natural del usuario, que un Large Language Model interpreta y combina con el objetivo de extraer información relevante de una fuente de conocimiento conectada. El componente de chat es el panel central para acceder a la lógica de recuperación y generación de RAGFlow y permite explorar el contenido de documentos de manera exploratoria, basada en preguntas e interactiva. A diferencia de chatbots clásicos como ChatGPT, la respuesta no se basa en el conocimiento general del modelo, sino en los contenidos recuperados previamente de la base de conocimiento.
En RAGFlow, un „Assistant“ es una unidad configurable para llevar a cabo diálogos guiados por el usuario en los que se recupera información de bases de conocimiento definidas y se procesa con un modelo de lenguaje. La configuración de un asistente se realiza mediante un asistente de configuración dividido en tres pestañas temáticas: „Assistant settings“, „Prompt engine“ y „Model settings“.
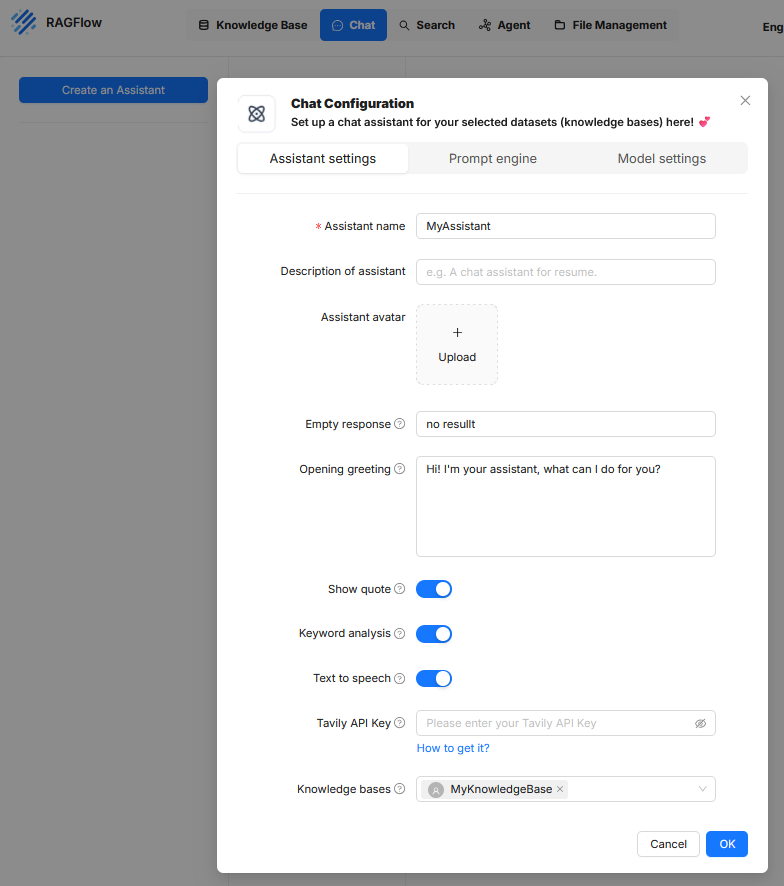
Assistant settings
Este área define los metadatos y el comportamiento externo del asistente en la interfaz de usuario. Incluye las siguientes opciones:
- Assistant name designa el nombre interno del asistente.
- Description of assistant es un campo de texto opcional para describir el propósito de uso.
- Assistant avatar permite subir una imagen para visualizar el asistente.
- Empty response especifica el texto que se muestra cuando no se puede generar una respuesta adecuada.
- Opening greeting contiene un mensaje de bienvenida que aparece al inicio de la interacción.
- Show quote activa la visualización de citas de fuentes si hay referencias de documentos.
- Keyword analysis controla el reconocimiento de palabras clave para mejorar la consulta.
- Text to speech habilita la salida de voz de los contenidos de la respuesta.
- Tavily API Key permite integrar servicios de búsqueda externos para enriquecer los datos de contexto.
- Knowledge bases establece la conexión a una o varias fuentes de conocimiento sobre las que se genera la respuesta.
Prompt engine
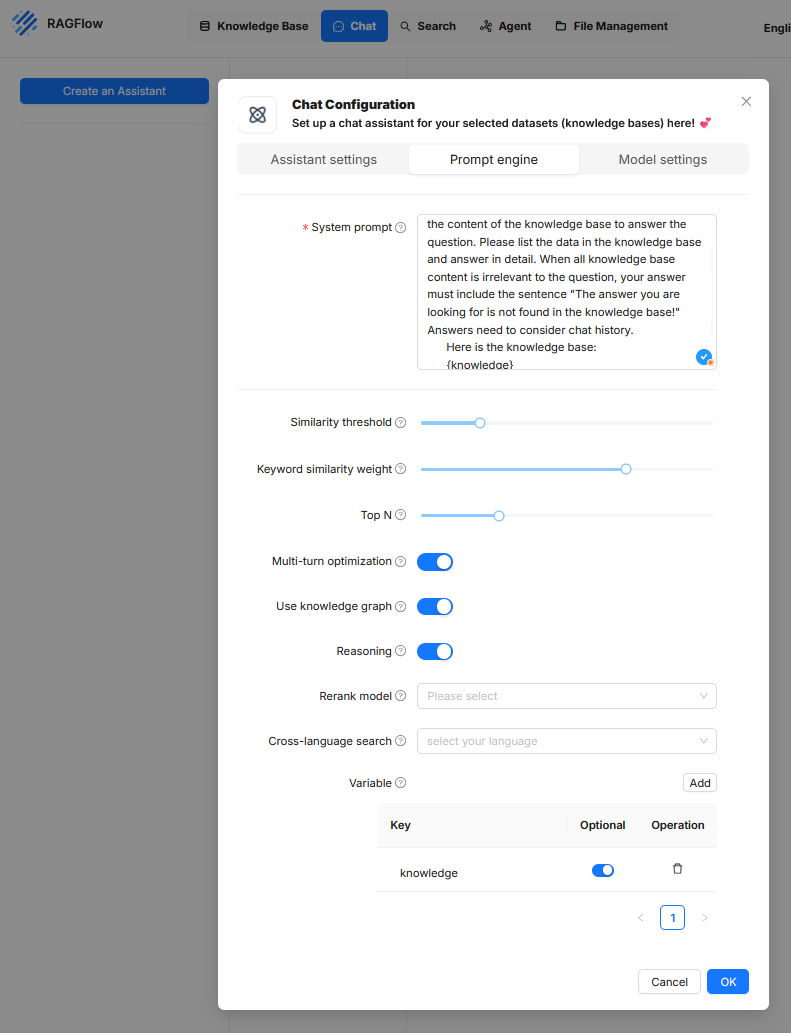
En esta pestaña se definen las instrucciones internas y estrategias de búsqueda con las que el modelo de lenguaje accede a la base de conocimiento y procesa los resultados.
- Systemprompt
Es un texto de control fijo que se envía al modelo de lenguaje con cada consulta. Contiene instrucciones claras sobre cómo debe reaccionar el modelo ante los contenidos proporcionados por el recuperador. Este texto de prompt también puede regular la estructura de la respuesta, la consideración del historial de chat o el formato de las citas de fuentes. - Similarity threshold
Este umbral determina a partir de qué grado de similitud semántica se considera relevante un fragmento y se envía al modelo de lenguaje. Un valor alto hace que solo se incluyan contenidos muy relacionados. Un valor bajo aumenta la tolerancia hacia contenidos distintos pero potencialmente informativos. El umbral afecta directamente al número y calidad de los pasajes de contexto recuperados. - Keyword similarity weight
Este parámetro establece en qué medida la coincidencia de palabras clave (tokens de alta ponderación) influye en la evaluación de la relevancia. Un valor alto significa que los términos exactos tienen más peso, mientras que un valor bajo prioriza la proximidad semántica a nivel de frase o significado. Esta ponderación determina si el foco está más en la coincidencia formal o en la similitud de contenido. - Top N
Define el número máximo de pasajes de contexto que se extraerán de la base de conocimiento y se proporcionarán al modelo de lenguaje. La selección se hace por relevancia. Un valor bajo como 3 o 5 produce un contexto más compacto, pero puede omitir información relevante. Valores altos pueden mejorar la calidad de la respuesta, pero alargar demasiado el prompt y superar el límite de tokens del modelo. - Multi-turn optimization
Con este ajuste se activa la gestión de contexto a lo largo de varias rondas de conversación. Esto significa que se considerará el historial de chat para interpretar correctamente preguntas de seguimiento o referencias a mensajes anteriores. Esta opción es esencial en diálogos complejos o con aclaraciones, pero aumenta la complejidad de la estructura del prompt y el volumen de tokens. - Use knowledge graph
Si está activado, además de los textos no estructurados se incluye un grafo de conocimiento en la generación de respuestas. Este grafo puede contener entidades y relaciones extraídas sistemáticamente de la base de conocimiento. De este modo, el modelo puede comprender mejor las relaciones lógicas entre conceptos y ofrecer respuestas más estructuradas. Es necesario que exista un grafo de conocimiento disponible en el sistema. - Reasoning
Esta función amplía el procesamiento generativo con inferencias lógicas. El modelo recibe la instrucción de no limitarse a reproducir contenidos, sino de derivar declaraciones de los datos de contexto, como reconocer conexiones o extraer significados implícitos. Esto puede aumentar la profundidad de las respuestas, pero conlleva cierto riesgo de alucinaciones si la base de datos no es inequívoca. - Rerank model
Si está activado, se utiliza un modelo adicional para reevaluar y reordenar los documentos proporcionados por el recuperador. Sirve para controlar la calidad de la lista de resultados, especialmente si el mecanismo de recuperación principal arroja muchos resultados irrelevantes o competitivos. Aquí se pueden emplear modelos especializados, por ejemplo, Transformers optimizados para ranking o comparación. - Cross-language search
Con esta opción se puede definir un idioma objetivo para consultas multilingües. Así, los usuarios pueden hacer preguntas en un idioma (p.ej., alemán) mientras que la base de conocimiento está en otro (p.ej., inglés). Es necesario que el modelo de recuperación y el de lenguaje sean multilingües. Los resultados se traducen automáticamente o se interpretan según corresponda. - Variable
Aquí se definen marcadores de posición que se pueden usar dentro del system prompt. Al usar el marcador {knowledge} en el system prompt, se reemplaza en tiempo de ejecución por el texto recuperado de la base de conocimiento. Por ejemplo, si en el chat se pregunta „¿Qué es un Lastenheft?“, el sistema busca pasajes semánticamente adecuados en la fuente conectada. Si encuentra, por ejemplo, la frase „Ein Lastenheft beschreibt die Anforderungen des Auftraggebers an die Leistungen des Auftragnehmers“, la selecciona como contexto. Si el system prompt contiene „Responde la pregunta únicamente con base en el siguiente contenido: {knowledge}“, el sistema sustituye el marcador por el fragmento encontrado. El modelo de lenguaje recibe entonces el prompt completo: „Responde la pregunta únicamente con base en el siguiente contenido: Ein Lastenheft beschreibt die Anforderungen des Auftraggebers an die Leistungen des Auftragnehmers.“ Este prompt se envía junto con la pregunta original al modelo, que genera la respuesta. El uso de marcadores como {knowledge} permite una estructura de prompt genérica que se completa automáticamente con los contenidos relevantes en tiempo de ejecución. Se pueden definir más marcadores, por ejemplo para la pregunta, sellos de tiempo o metadatos. Así, el prompt resulta reutilizable y modular.
Model settings
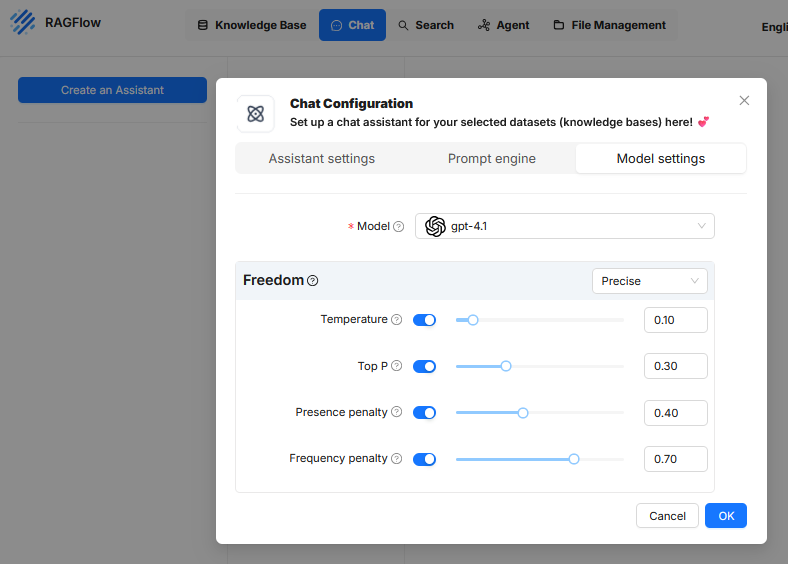
En la pestaña Model settings de la configuración de chat en RAGFlow se definen parámetros que controlan el comportamiento de respuesta del modelo de lenguaje subyacente. Estos ajustes no afectan la selección de contenidos de la base de conocimiento, sino la forma en que el modelo trabaja con ellos y genera texto. El objetivo es regular la calidad de la respuesta, la precisión, la expresividad y la redundancia. Están disponibles los siguientes parámetros:
Model
Aquí se selecciona el modelo de lenguaje que se usará para generar las respuestas. En la configuración actual está activado „gpt-4.1“. Esta elección determina en gran medida el rendimiento, el estilo de respuesta y los límites de tokens del asistente.Freedom (Profilvoreinstellung)
En la interfaz de usuario se puede elegir un perfil predefinido, por ejemplo „Precise“. Este perfil agrupa los parámetros mencionados en una combinación fija.- Precise (Präzise): Configura el modelo para máxima fidelidad a los hechos y salidas deterministas. Las respuestas son consistentes y muy ajustadas a la base de datos. Normalmente se establecen valores de Temperature y Top P muy bajos.
- Improvise (Improvisieren): Configura el modelo para máxima creatividad y variabilidad. Está pensado para generar ideas y textos diversos. Temperature y Top P se establecen en valores altos.
- Balance (Ausgewogen): Elige una configuración intermedia que equilibre información fiable y lenguaje natural conversacional.
Temperature
Este parámetro controla el grado de aleatoriedad en la generación de texto.- Un valor bajo (p.ej., cercano a 0) obliga al modelo a elegir casi siempre la palabra más probable y segura. Si la frase es “El cielo es…”, el modelo elegirá “azul” con muy alta probabilidad. Los textos son muy precisos, orientados a hechos y suelen ser idénticos con la misma consulta.
- Un valor alto (p.ej., cercano a 1) anima al modelo a elegir también palabras menos comunes y creativas que pudieran encajar. En “El cielo es…” podría entonces elegir “despejado”, “infinito” o “impresionante”. Los textos resultan más variados e impredecibles, pero pueden perder algo de precisión.
Top P
Para entender „Top P“, primero hay que ver cómo genera texto una IA: no escribe la frase entera de una vez, sino palabra por palabra. Para determinar la siguiente palabra, la IA analiza el texto ya escrito. Si el texto actual es “El tiempo hoy es”, “la siguiente palabra” se refiere a la que debe ir justo después. Tras este análisis, la IA crea internamente una enorme lista con todas las palabras que conoce (su vocabulario) y asigna a cada una una probabilidad de encajar como siguiente palabra. Aquí interviene „Top P“ como filtro de esta gran lista. Su función es crear un pequeño “pool” de selección para el paso actual. Para ello, selecciona las palabras más probables de la parte superior de la lista y suma sus probabilidades hasta alcanzar el valor de Top P configurado. Solo las palabras incluidas en esa suma entran en el pool final. La “siguiente palabra” se elige luego de ese pool más pequeño.Un ejemplo sencillo ilustra el proceso: supongamos que la frase es “El tiempo hoy es”. La IA calcula probabilidades para la siguiente palabra, por ejemplo: ‘soleado’ 50%, ‘agradable’ 25% y ’lluvioso’ 15%. Con un Top P bajo de 0.70 (70%), la IA crea el pool sumando las palabras más probables hasta superar el 70%. En este caso toma ‘soleado’ (50%) y ‘agradable’ (25%). El total es 75%, se supera el umbral, y el pool queda con ‘soleado’ y ‘agradable’, produciendo una respuesta muy predecible. Si el Top P fuera alto, por ejemplo 0.95 (95%), el pool sería mayor. A ‘soleado’ y ‘agradable’ (75%) se añadiría ’lluvioso’ (15%), ya que el total de 90% está por debajo del 95%. El pool contendría tres palabras, lo que permite respuestas más variadas.
Presence penalty
Este valor influye en si el modelo vuelve a tratar temas o términos ya mencionados en su respuesta. Una vez usado un tema o palabra clave, se aplica una penalización negativa, lo que hace menos atractivo para la IA volver a mencionarlo. Si, por ejemplo, en la descripción de un coche ya se habló del “motor”, la Presence Penalty hará que tienda a describir otros aspectos como los “frenos” o el “interior” en lugar de volver al motor. Esto genera respuestas más completas y variadas. Un valor alto (p.ej. 0.40) hace que el modelo prefiera tratar temas nuevos y así mitiga repeticiones de conceptos, útil para reducir pasajes redundantes.Frequency penalty
La Frequency Penalty reduce la repetición excesiva de las mismas palabras o frases exactas. A diferencia de la Presence Penalty, que penaliza un tema solo tras la primera mención, la Frequency Penalty aumenta la penalización negativa por cada repetición individual de una palabra. Cuanto más se use un término, menos probable será que se vuelva a usar. Si la IA escribe “El paisaje es hermoso”, la palabra “hermoso” tendrá menos probabilidad de volver a salir. En lugar de “y la vista también es hermosa”, la IA se ve forzada a usar un sinónimo como “impresionante”. Esto fomenta una elección de palabras más variada y hace el texto más natural. Un valor alto (p.ej. 0.70) impide repeticiones excesivas, especialmente en respuestas largas o textos estructurados.
Estos elementos de configuración afectan únicamente al propio modelo de lenguaje.
Search
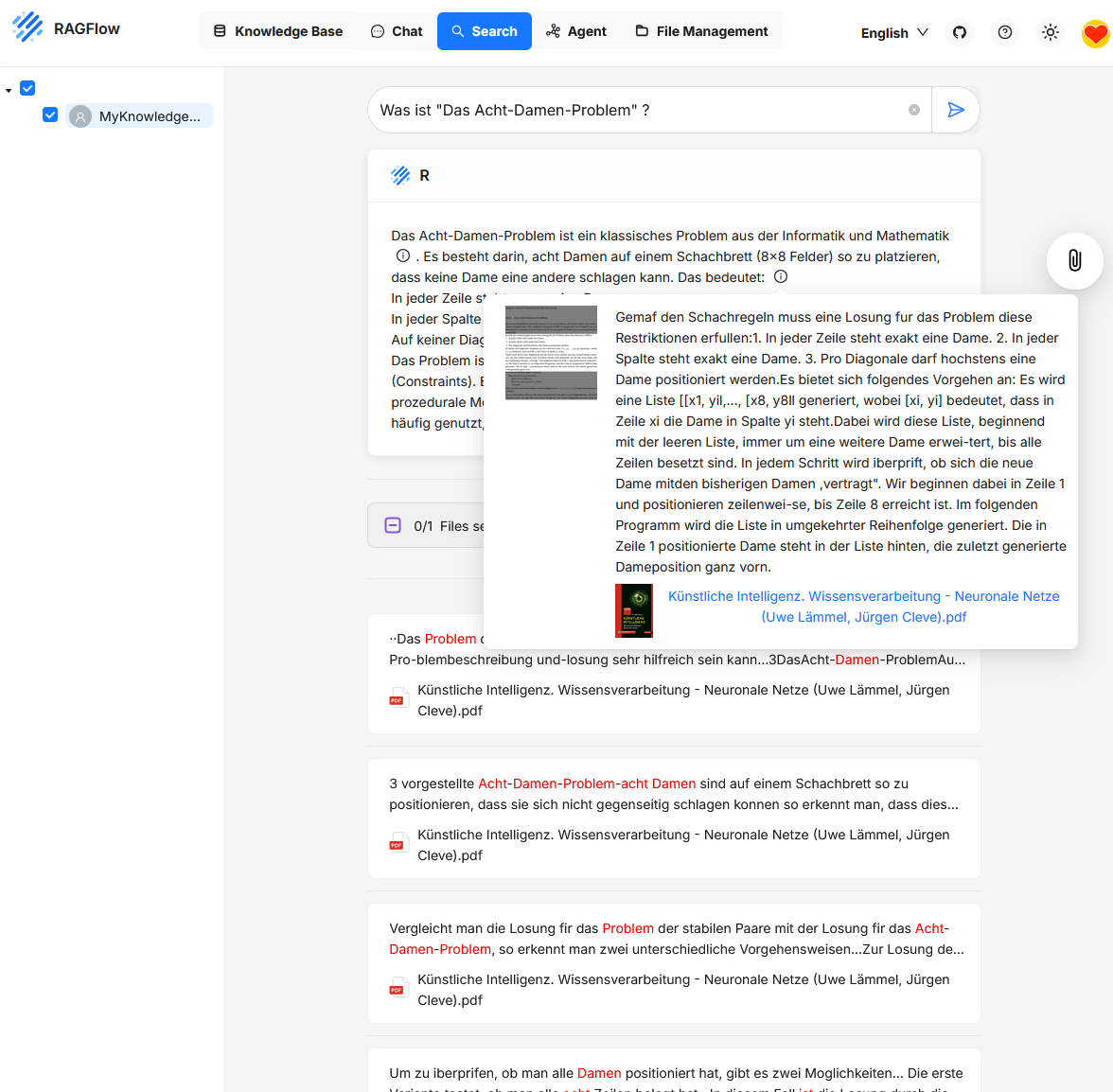
Search sirve para recuperar información de los contenidos de una o varias Knowledge Bases. No genera una respuesta, sino que muestra directamente los fragments que coinciden con la consulta.
Los usuarios ingresan una consulta de texto en el campo de búsqueda, por ejemplo una pregunta o una palabra clave. RAGFlow busca en las Knowledge Bases conectadas fragmentos con alta coincidencia de contenido. Los resultados incluyen un extracto del contenido encontrado, acompañado del nombre de archivo y la posición en el documento. Al hacer clic en un resultado, se abre una vista previa con el fragmento completo y su contexto.
A diferencia de la función de chat, Search se centra en el acceso directo al contenido y en la trazabilidad. Es especialmente útil para investigaciones, validación de contenido, lectura puntual o verificación de los resultados de indexación.
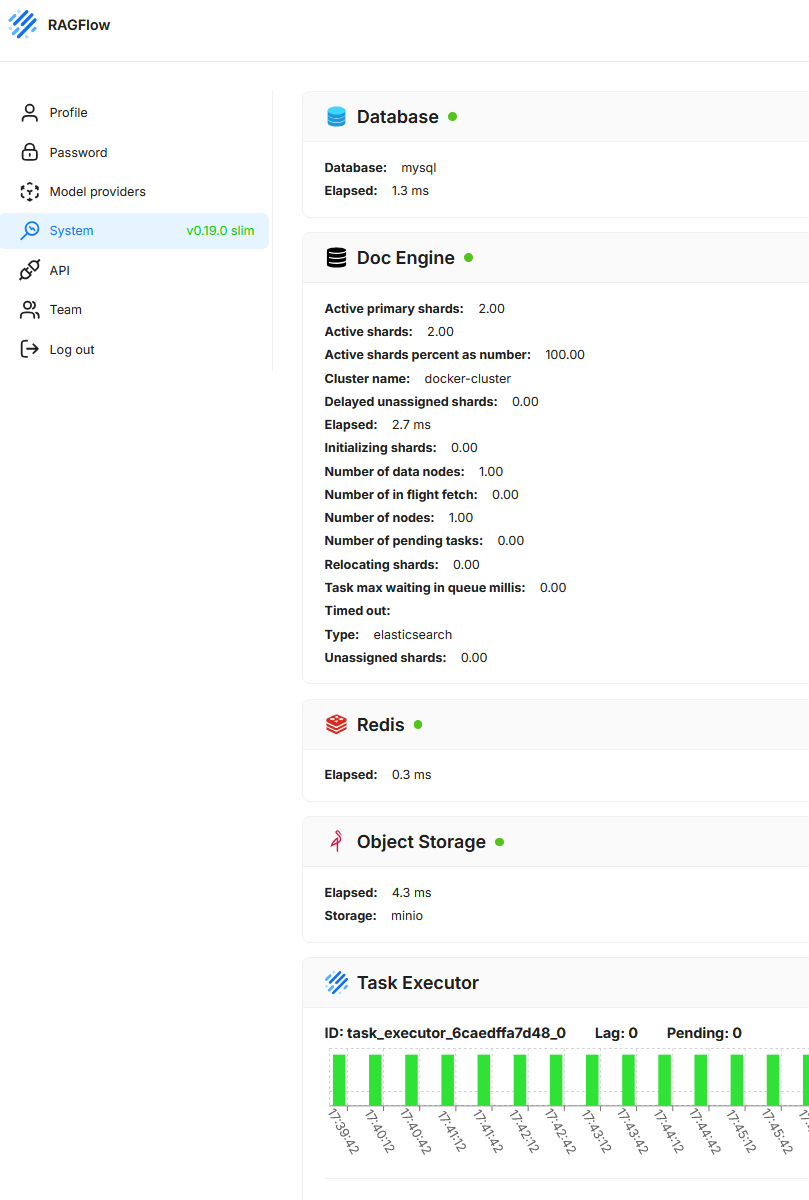
System
Esta sección muestra el estado técnico actual y la disponibilidad operativa de los componentes del sistema subyacente. El objetivo es ofrecer una visión rápida del funcionamiento y rendimiento de los servicios necesarios para la aplicación.
- Database
Muestra el estado y tiempo de respuesta de la base de datos relacional (aquí MySQL). - Doc Engine
Proporciona información sobre la base de datos vectorial o de búsqueda (aquí Elasticsearch), incluida la distribución de shards, el nombre del clúster, tareas en ejecución, latencias y posibles errores. - Redis
Indica la disponibilidad y tiempo de respuesta del sistema de caché. - Object Storage
Verifica la conectividad y el correcto funcionamiento del almacenamiento de objetos (aquí MinIO). En RAGFlow, Object Storage se usa para guardar de forma persistente los documentos y otros archivos subidos o procesados. - Task Executor
Muestra los procesos en segundo plano en ejecución y su distribución de carga. Se visualizan las tareas activas, el retraso (lag) y las tareas pendientes.
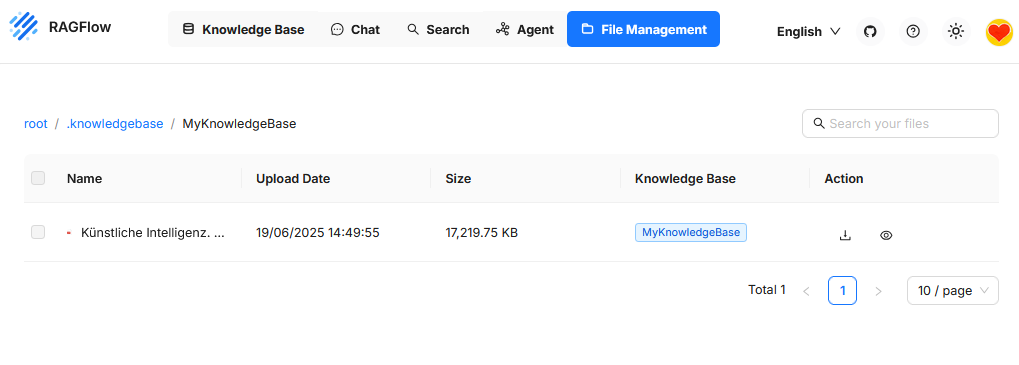
File Management
Este espacio sirve para gestionar todos los archivos subidos que se usan en una o varias Knowledge Bases. Aquí se almacenan, muestran, buscan y estructuran los documentos.