ComfyUI es una interfaz gráfica basada en nodos para controlar y modificar modelos de IA para la generación de imágenes y vídeos. Wan 2.1 es un modelo de texto a vídeo (T2V) desarrollado específicamente para la generación de vídeos a partir de entradas de texto.
Esta guía describe paso a paso cómo configurar ComfyUI con Wan 2.1 de forma local. Cada sección explica los componentes necesarios, por qué son necesarios y cómo instalarlos correctamente. Esta guía requiere Python 10 y una GPU con soporte CUDA.
Requisitos: Python y CUDA
Instalar Python 10
Wan 2.1 requiere Python 10. Si aún no está instalado, puede descargarse e instalarse desde la página oficial de Python.
CUDA para aceleración por GPU
CUDA es una tecnología de NVIDIA que ejecuta cálculos en la GPU y es necesaria para usar PyTorch con aceleración por GPU. La versión más reciente puede descargarse desde la página de NVIDIA. Asegúrate de que tu GPU sea compatible con CUDA.
Descargar y configurar ComfyUI
Clona el repositorio de ComfyUI: git clone https://github.com/comfyanonymous/ComfyUI.git
Luego entramos en el directorio e instalamos las dependencias: pip install -r requirements.txt
Dependencias instaladas:
- torch: La biblioteca PyTorch para redes neuronales.
- torchvision: Extensiones de PyTorch, especialmente para imágenes.
- torchaudio: Extensiones de PyTorch para procesamiento de audio.
- numpy: Cálculos científicos.
- pillow: Procesamiento de imágenes.
- Otros: Necesarios para funcionalidades de ComfyUI.
Instalar ComfyUI-Manager
ComfyUI-Manager es un complemento que simplifica la gestión de extensiones:
git clone https://github.com/ltdrdata/ComfyUI-Manager.git
Instalar Video-Wrapper
WanVideoWrapper integra Wan 2.1 en ComfyUI y permite el uso de la generación de vídeo:
git clone https://github.com/kijai/ComfyUI-WanVideoWrapper.git
Instalar dependencias faltantes del wrapper: pip install -r requirements.txt

Instalar ComfyUI-VideoHelperSuite
Un wrapper de vídeo alternativo que también se utiliza en ComfyUI para generación de vídeo: https://github.com/Kosinkadink/ComfyUI-VideoHelperSuite.git
Instalar dependencias faltantes: pip install -r requirements.txt
Instalar ComfyUI-HunyuanVideoWrapper
git clone https://github.com/kijai/ComfyUI-HunyuanVideoWrapper.git
Instalar dependencias faltantes: pip install -r requirements.txt
Crear entorno virtual para Wan 2.1
Se recomienda usar un entorno virtual separado para Wan 2.1:
python -m venv wan21
A continuación, activar el entorno:
wan21\Scripts\activate
Después instalar las dependencias faltantes: pip install -r requirements.txt
Instalar PyTorch con soporte CUDA
Primero comprobar si ya existe una versión de PyTorch con soporte CUDA:
python -c “import torch; print(torch.version); print(torch.version.cuda)”

Si hay una versión para CPU instalada, hay que desinstalar PyTorch primero:
pip uninstall torch torchvision torchaudio -y
Luego se puede instalar PyTorch con soporte CUDA:
pip install torch torchvision torchaudio –index-url https://download.pytorch.org/whl/cu126
Verificar si se está usando la GPU:
python -c “import torch; print(torch.cuda.is_available()); print(torch.cuda.get_device_name(0))”

Descargar modelos para generación de imágenes y vídeos
Modelos de imagen
Para usar ComfyUI también en la generación de imágenes, instalamos los siguientes modelos:
- DreamShaper: Especial para imágenes artísticas.
- Realistic Vision V6.0 B1: Imágenes realistas de alta calidad.
- Stable Diffusion XL (SDXL): Modelo de IA potente de uso general.
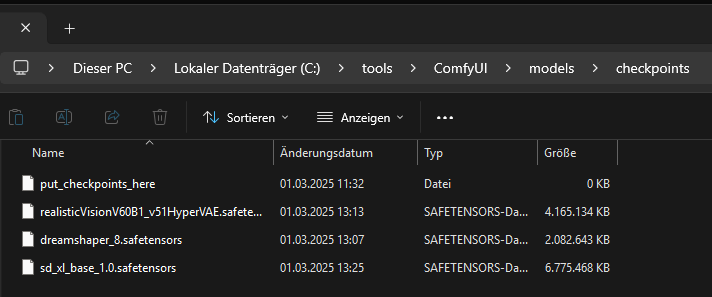
Estos modelos deben guardarse en C:\tools\ComfyUI\models\checkpoints.
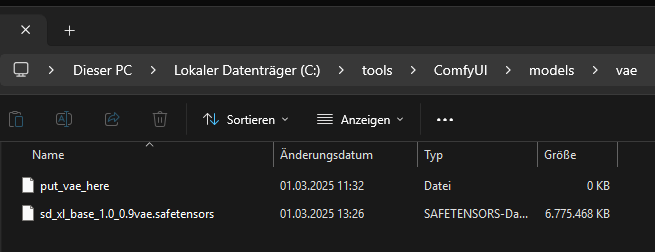
El archivo VAE para SDXL va en C:\tools\ComfyUI\models\vae\.
DreamShaper Modelo: https://civitai.com/models/4384/dreamshaper
Realistic Vision V6.0 B1 Modelo: https://civitai.com/models/4201/realistic-vision-v60
Stable Diffusion XL (SDXL) Modelo:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_base_1.0.safetensors
VAE:
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_base_1.0_0.9vae.safetensors
Todos los modelos deben moverse a la carpeta C:\tools\ComfyUI\models\checkpoints.
El archivo VAE de Stable Diffusion XL va a
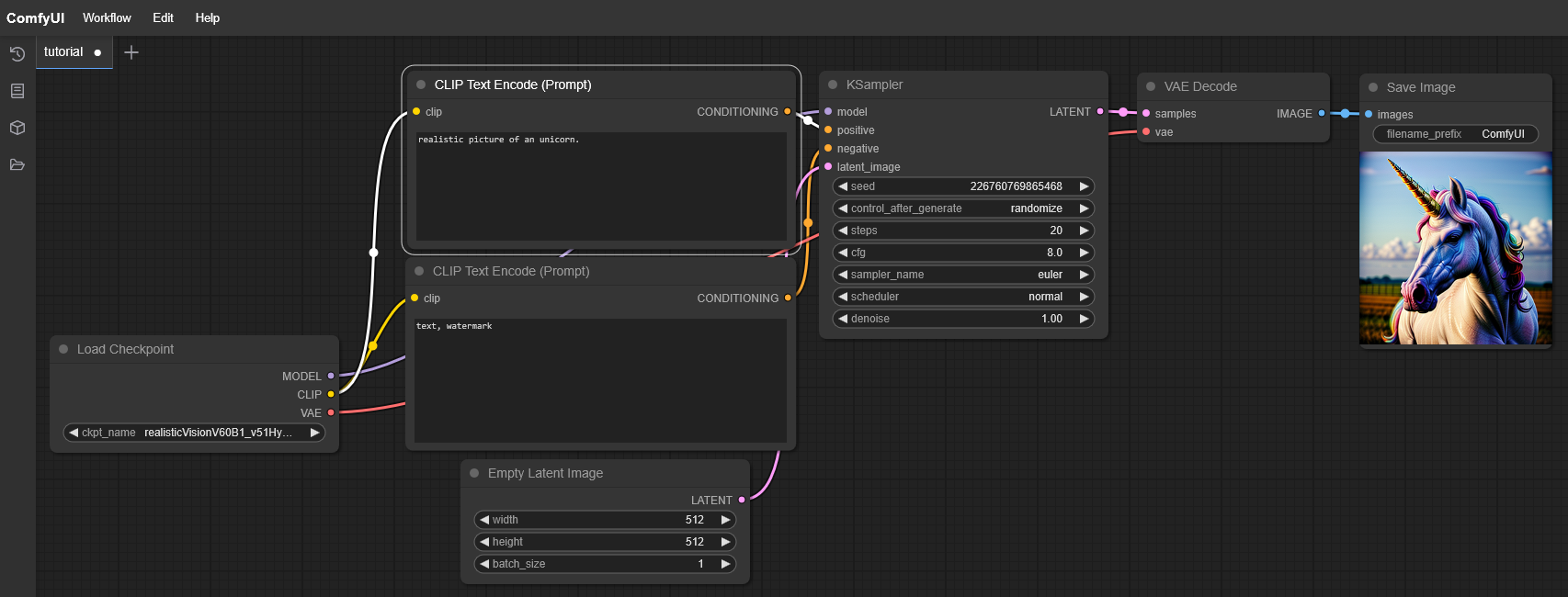
Iniciar ComfyUI y generar una primera imagen
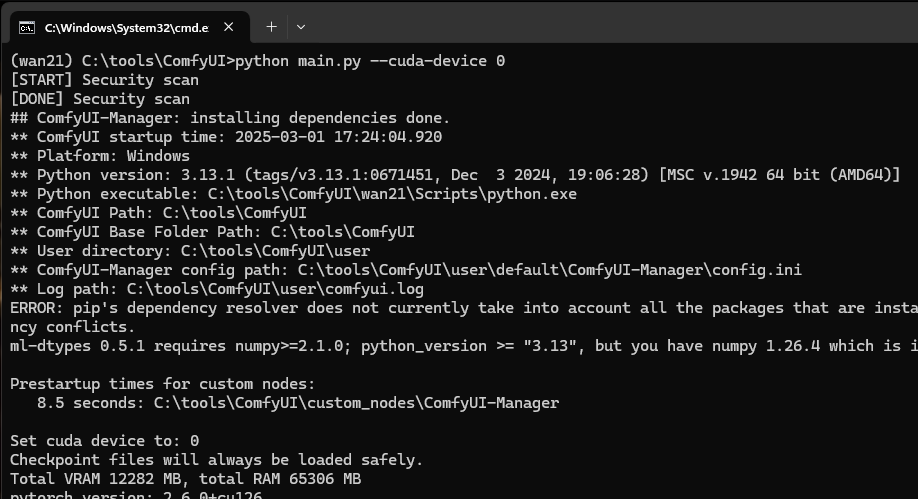
python main.py –cuda-device 0
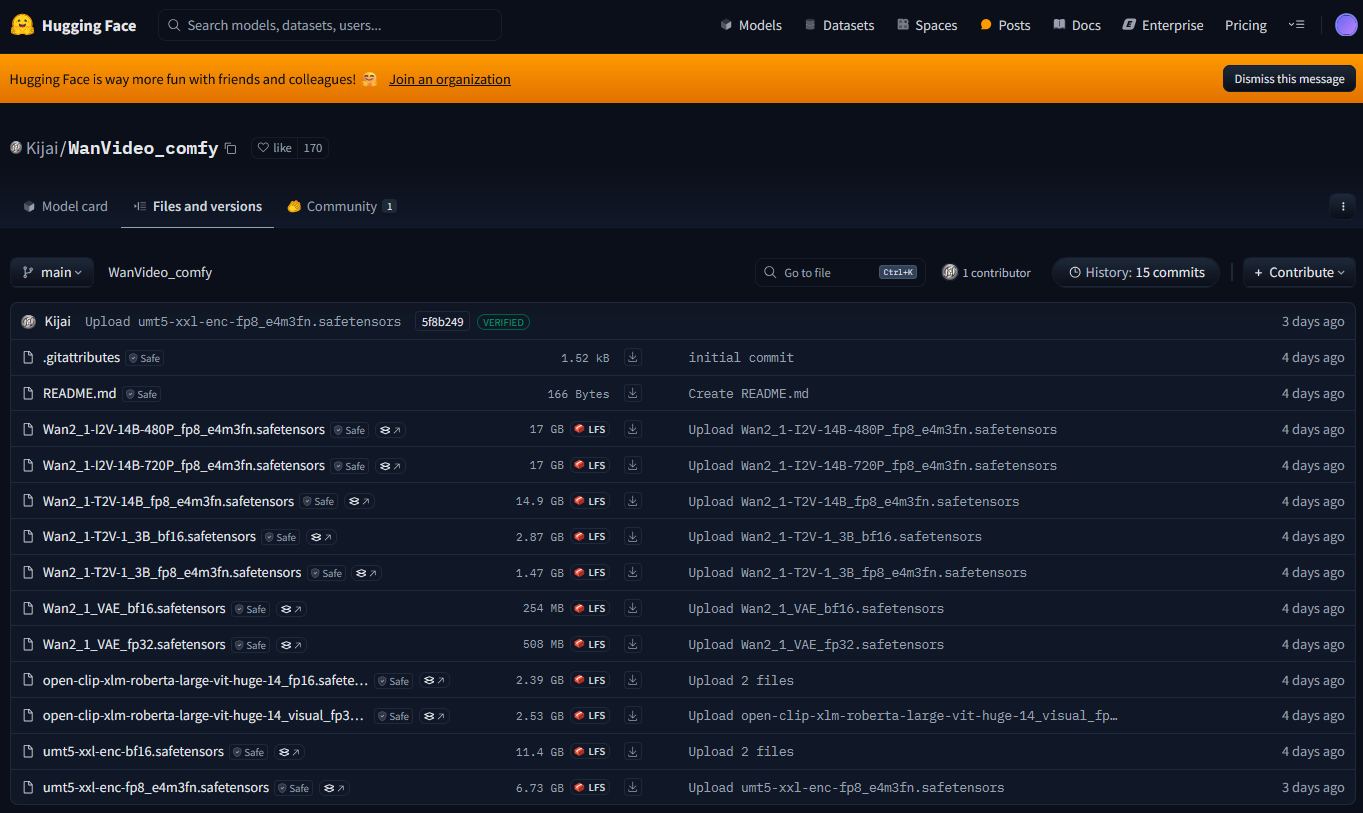
Modelos de vídeo para Wan 2.1
Como usamos ComfyUI-WanVideoWrapper, utilizamos para la creación de vídeos un modelo de vídeo entrenado para el wrapper: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
Dentro del wrapper necesitamos la carpeta “models”. Esa carpeta falta tras la instalación.
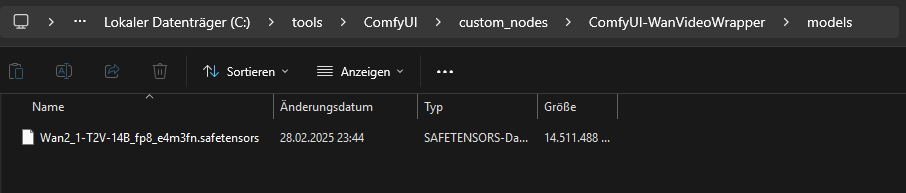
Dentro de la carpeta “models” copiamos luego el modelo de texto a vídeo (T2V):
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-T2V-14B_fp8_e4m3fn.safetensors
“T2V” significa texto a vídeo. 14B parámetros son un compromiso entre calidad y velocidad de cómputo. fp8 (8 bits) necesita menos VRAM que fp16 o fp32.
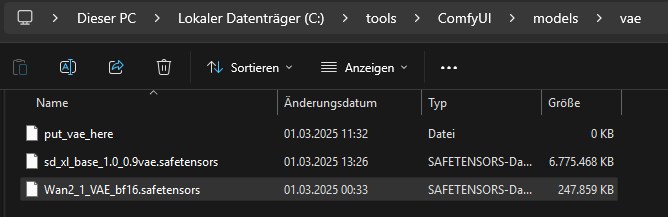
El archivo VAE lo copiamos a C:\tools\ComfyUI\models\vae\
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1_VAE_bf16.safetensors
El modelo de difusión se copia a C:\tools\ComfyUI\models\diffusion_models\
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-T2V-1_3B_bf16.safetensors
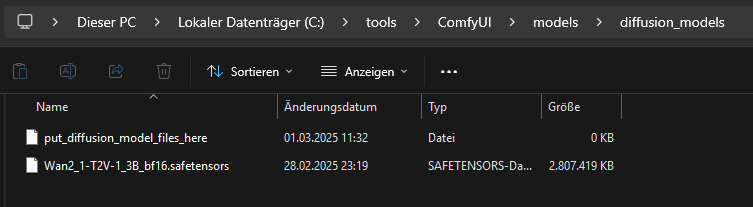
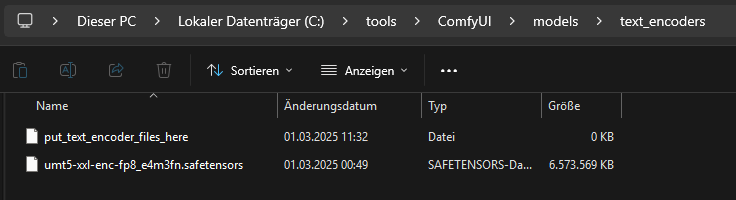
Como codificador de texto usamos: https://huggingface.co/Kijai/WanVideo_comfy/blob/main/umt5-xxl-enc-fp8_e4m3fn.safetensors
Este archivo lo copiamos a “C:\tools\ComfyUI\models\text_encoders\”.
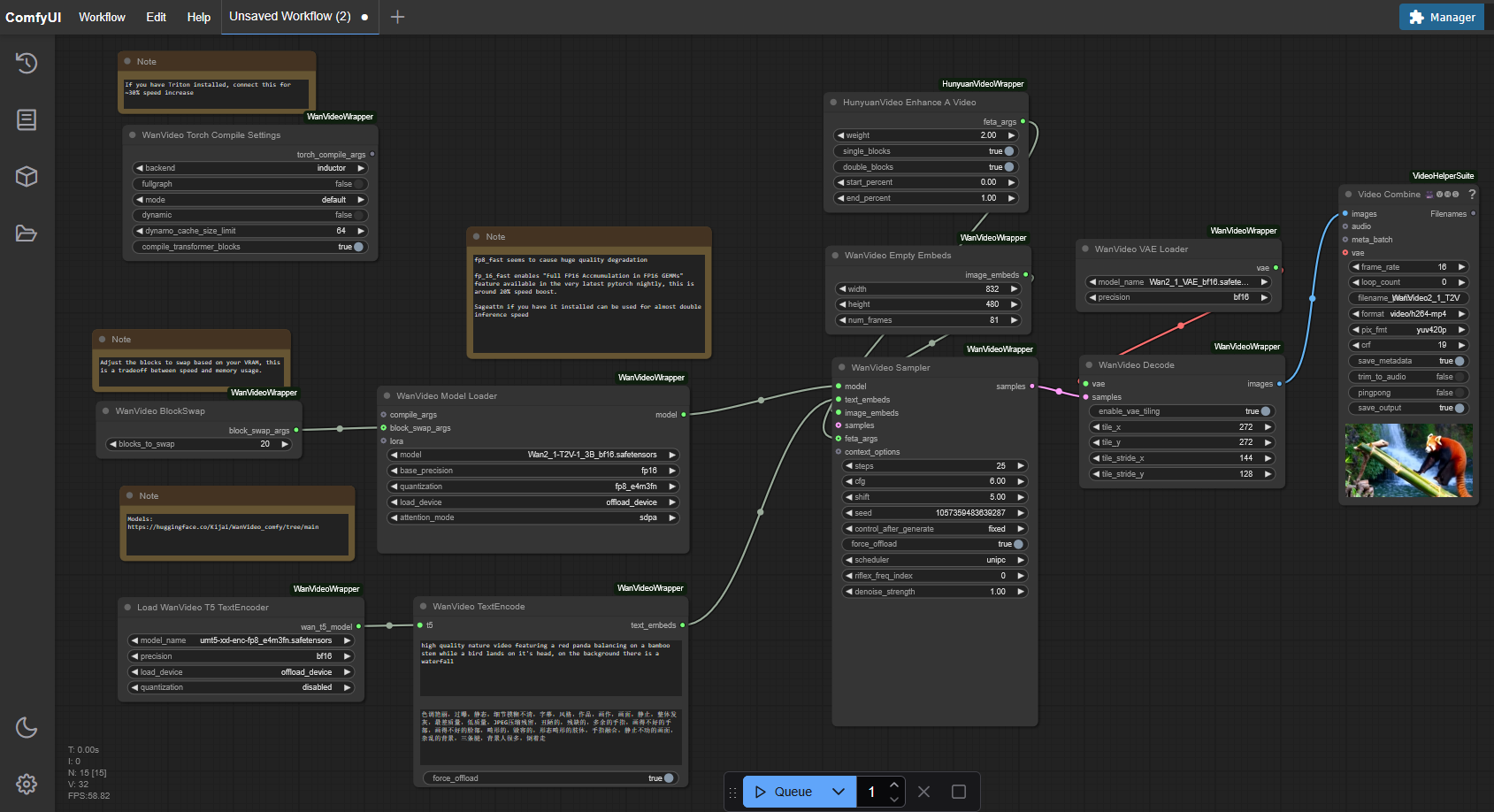
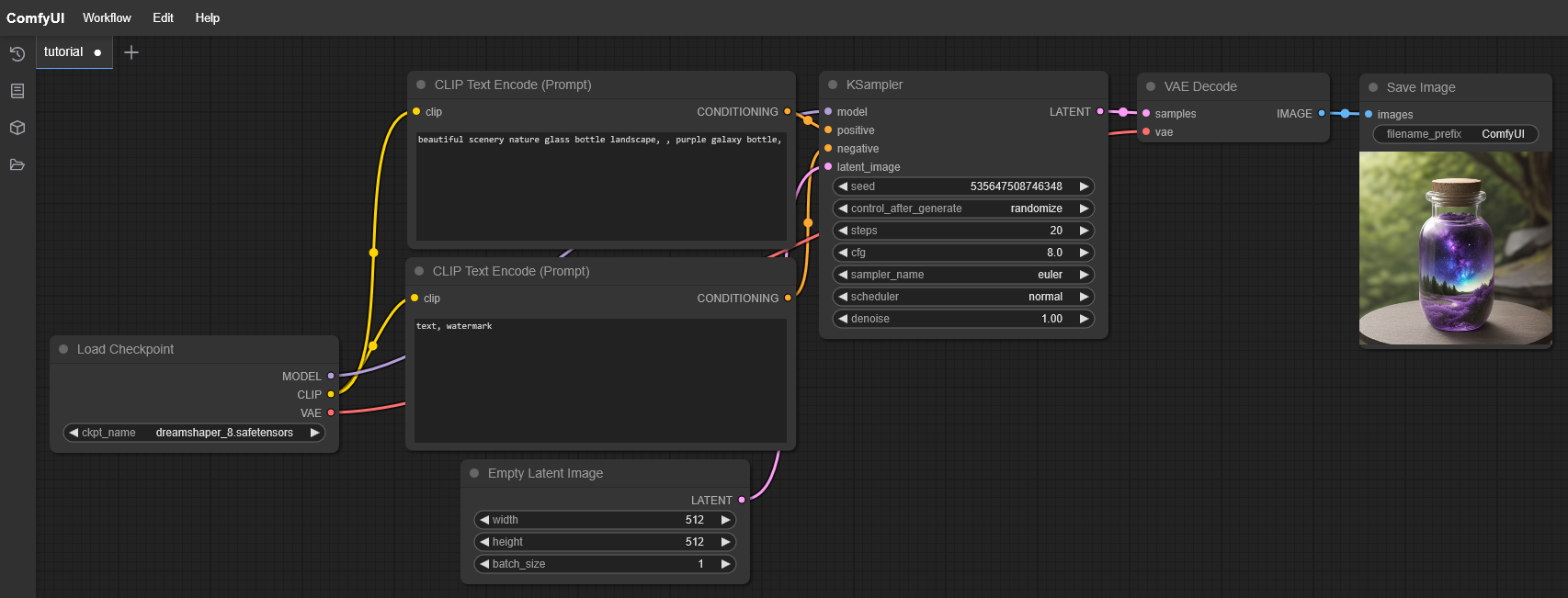
Configurar workflow para Wan 2.1
Para poder usar el nuevo modelo Wan 2.1 en ComfyUI, necesitamos luego el workflow adecuado: https://github.com/kijai/ComfyUI-WanVideoWrapper/blob/main/example_workflows/wanvideo_T2V_example_01.json
Copiar el contenido JSON y pegarlo en ComfyUI como un nuevo workflow.
Iniciar y probar ComfyUI
Luego se puede iniciar ComfyUI:
python main.py –cuda-device 0