En esta entrada te explico cómo usar Whisper, una herramienta basada en IA de OpenAI, para la transcripción automática de vídeos. Whisper puede convertir con precisión el lenguaje hablado en varios idiomas – incluido el alemán – en texto. Por ello, es ideal para transcribir, por ejemplo, entrevistas, conferencias o vídeos personales.
Instalar Python 3.10
Whisper requiere el lenguaje de programación Python y necesita una versión entre la 3.7 y la 3.10. En esta guía usamos Python 3.10 para evitar problemas de compatibilidad.
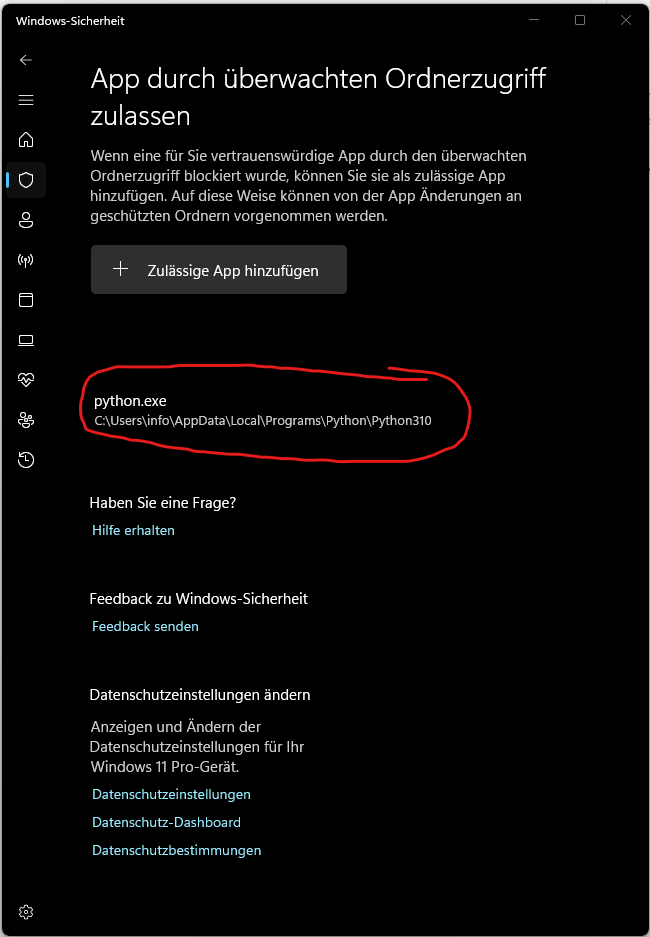
Si la seguridad de Windows bloquea la ejecución de python.exe, puedes agregar Python manualmente como una aplicación permitida:

Configurar un entorno virtual (whisper-env)
Whisper requiere varias bibliotecas (como torch para aprendizaje automático, ffmpeg para el procesamiento de audio y algunos paquetes de Python adicionales). Si instalas estos paquetes directamente en tu entorno global de Python, podrían entrar en conflicto con otros proyectos que necesiten versiones diferentes de estas bibliotecas. Un entorno virtual mantiene todas las dependencias necesarias separadas, de modo que solo afectan a Whisper.
Crea ahora el entorno virtual con el nombre whisper-env en la carpeta del proyecto, lo que generará un nuevo directorio llamado whisper-env en el directorio del proyecto. Este contendrá el entorno de Python aislado donde se instalarán todos los paquetes para Whisper.
Para usar el entorno virtual, debes activarlo. Después de la activación, el prompt mostrará (whisper-env), lo que indica que el entorno virtual está activo. Todos los comandos de Python posteriores (por ejemplo, pip install) se aplican únicamente a este entorno mientras esté activo.
Ahora puedes instalar Whisper y todas las dependencias necesarias en el entorno virtual sin que afecten a tu sistema global.
Si durante la instalación surgen errores porque faltan dependencias o herramientas adicionales, puedes instalarlas de la siguiente manera:
Instalar ffmpeg y agregarlo al PATH del sistemax
Whisper necesita ffmpeg para extraer el audio de los archivos de vídeo. Aquí están los pasos para instalar ffmpeg. El archivo necesario “ffmpeg-release-essentials.zip” lo puedes descargar desde el sitio web oficial. A continuación, debes agregar la carpeta bin (C:\tools\ffmpeg-7.1-essentials_build\bin) a la variable de entorno PATH. La versión de ffmpeg la puedes visualizar a continuación de la siguiente manera:
Usar Whisper para la transcripción
En el directorio del proyecto “whisper” creado anteriormente, he creado las siguientes carpetas:
- quelle: Esta carpeta contiene los archivos de vídeo que se van a transcribir.
- transkript: Aquí se guarda la transcripción final.
- whisper-env: Esta es la carpeta con el entorno virtual en el que se instaló Whisper.
Con el siguiente comando puedes transcribir el archivo Video1.mkv de la carpeta quelle y guardar la transcripción sin marcas de tiempo en la carpeta transkript.
"C:\Users\Benutzername\Videos\whisper\quelle\Video1.mkv": La ruta al archivo de vídeo que se va a transcribir.--language German: Indica que el vídeo está en alemán para que Whisper use el idioma correcto.--output_format txt: Guarda la transcripción como un archivo de texto plano (.txt) sin marcas de tiempo.--output_dir "C:\Users\Benutzername\Videos\whisper\transkript": Especifica que el archivo de texto se almacenará en la carpeta transkript.
Salir del entorno virtual
Al finalizar la transcripción, puedes desactivar el entorno virtual. Simplemente ejecuta el siguiente comando:
Transcripción automatizada de varios vídeos
Si tienes varios archivos de vídeo en la misma carpeta y quieres transcribirlos automáticamente sin volver a procesar los que ya fueron procesados, puedes usar el siguiente script de Python. El script busca en una carpeta especificada archivos de vídeo nuevos o modificados, los transcribe y guarda los resultados como archivos de texto en una carpeta de destino. Las transcripciones tienen el mismo nombre que los archivos de vídeo y contienen solo el texto sin marcas de tiempo. Un archivo de historial adicional garantiza que los vídeos ya procesados se omitan en la siguiente ejecución. De este modo, puedes ejecutar el script regularmente y este procesará automáticamente solo los archivos relevantes.
Ejecuta el script con el siguiente comando:
Usar Whisper con el modelo Large y soporte GPU
En esta sección aprenderás cómo utilizar el modelo Large de Whisper de forma óptima en tu GPU NVIDIA para lograr la mejor precisión en la transcripción y al mismo tiempo maximizar la velocidad. Dado que el modelo Large es intensivo en cálculos, resulta conveniente usar una GPU para acelerar significativamente el procesamiento.
Antes de entrar en detalles, hay que aclarar algunos términos básicos.
¿Qué es PyTorch (o torch)?
PyTorch es una biblioteca de código abierto para aprendizaje automático que fue desarrollada principalmente por Facebook AI. Ofrece una gran variedad de herramientas y algoritmos para Deep Learning y se utiliza en el lenguaje de programación Python.
En tu caso, Whisper utiliza PyTorch en segundo plano como „backend“, para realizar los complejos cálculos necesarios para la transcripción de audio a texto. Cuando instalas y usas Whisper, PyTorch se carga automáticamente en segundo plano – por lo que no tienes que ocuparte directamente de PyTorch, sino solo asegurarte de que esté correctamente instalado.
¿Qué es torch?
torch es el nombre del paquete de PyTorch en Python. Esto significa que cuando ves import torch en el código de Python, se refiere a la biblioteca PyTorch. El nombre „torch“ se usa porque PyTorch se importa en Python con este nombre de paquete.
¿Qué es CUDA?
CUDA (Compute Unified Device Architecture) es una tecnología e interfaz de programación desarrollada por NVIDIA. Permite a programas como PyTorch aprovechar la potencia de cálculo de una GPU NVIDIA. Las GPU son especialmente eficientes en cálculos paralelos, ya que pueden ejecutar muchas operaciones simultáneamente. Cuando un modelo como Whisper necesita procesar grandes cantidades de datos, CUDA puede reducir significativamente el tiempo de cómputo al utilizar la GPU para los cálculos.
Para PyTorch, esto significa que puede usar CUDA para ejecutar los cálculos en una GPU NVIDIA en lugar de la CPU, siempre que haya una GPU disponible y PyTorch esté instalado con soporte CUDA.
Instalación de PyTorch con soporte CUDA
Para que tu GPU se pueda usar con Whisper, PyTorch debe estar instalado con soporte CUDA. Sin CUDA, PyTorch usaría solo la CPU, lo cual es más lento. Ejecuta el siguiente comando en la línea de comandos para instalar PyTorch con la versión de CUDA adecuada:
Para asegurarte de que PyTorch esté instalado con soporte CUDA y que la GPU sea reconocida, puedes ejecutar el siguiente script de Python. Este comprueba si CUDA está disponible y muestra la información de la GPU.
En mi caso, CUDA no estaba preinstalado. La versión actual la podéis descargar en el sitio web de NVIDIA.
A continuación, puedes ejecutar de nuevo el script. En el mejor de los casos, se mostrará un mensaje similar:

El script se ha ampliado para usar “CUDA” y “large model”.
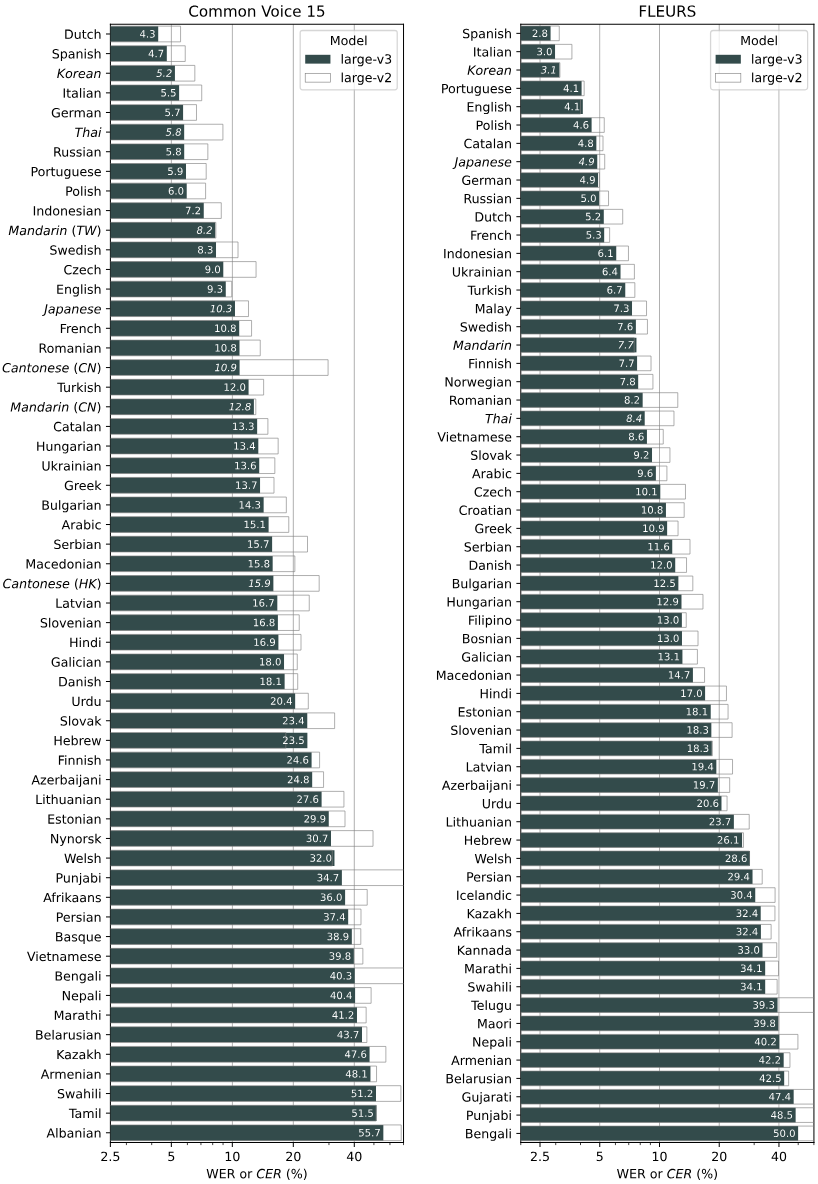
Modelos y su precisión en diferentes idiomas
La siguiente gráfica de OpenAI muestra la precisión de los distintos modelos de Whisper en una gran variedad de idiomas. Esta evaluación de rendimiento se basa en WER (Word Error Rate) y CER (Character Error Rate), que se evaluaron con los conjuntos de datos Common Voice 15 y Fleurs. Cada modelo de Whisper se probó en varios idiomas para mostrar su capacidad de transcripción precisa y sus diferencias de rendimiento según el idioma. Por ejemplo, un valor WER de 5,7 para el alemán significa que el modelo comete aproximadamente 5,7 errores por cada 100 palabras transcritas, lo que representa una precisión relativamente alta. La gráfica te da así una buena idea de qué modelo es especialmente efectivo en cada idioma.