- Ollama LLM-Laufzeitumgebung downloaden und installieren. Nach der Installation kann der Server unter http://127.0.0.1:11434/ aufgerufen werden.
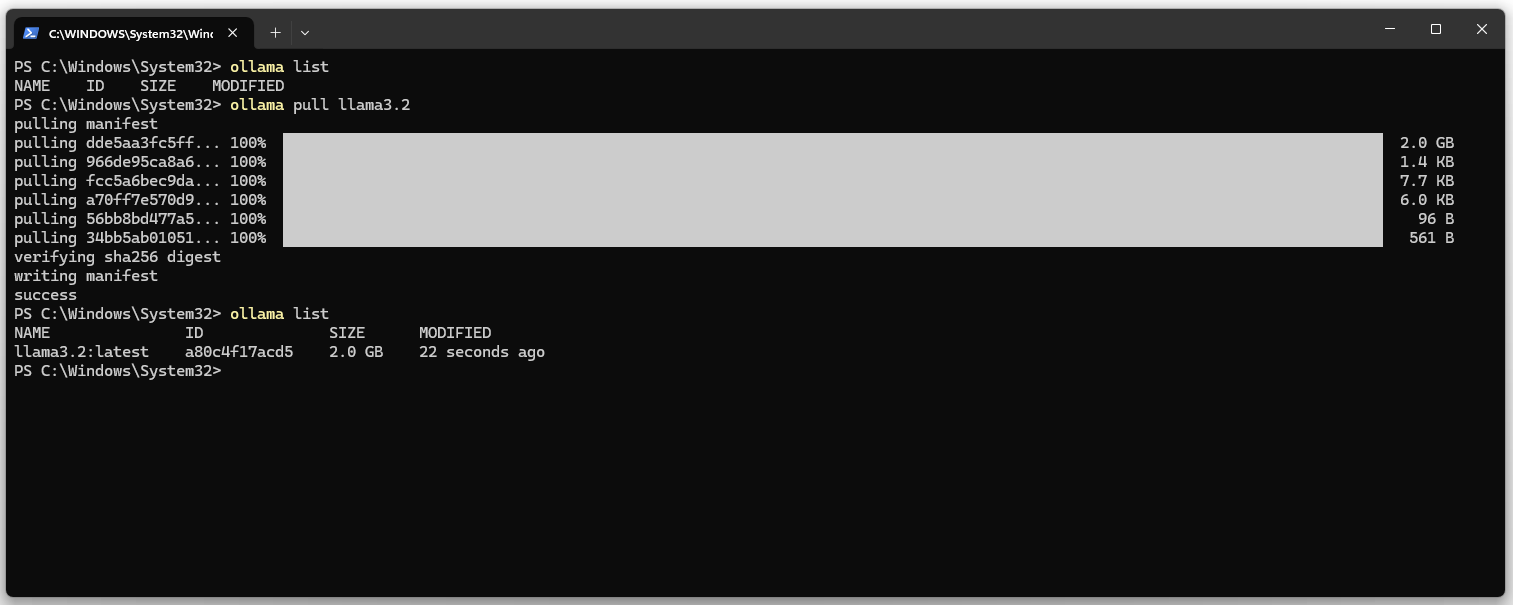
3. Liste der installierten Modelle anzeigen lassen. Die Liste sollte leer sein.
ollama list
4. llama3.2 LLM und DeepSeekv3 (404 GB HD & 413GB RAM) downloaden.
ollama pull llama3.2 ollama pull deepseek-v3
Auf der Webseite von Meta sind die aktuellen Versionen des LLMs zu finden.
5. llama3 starten.
ollama run llama3.2
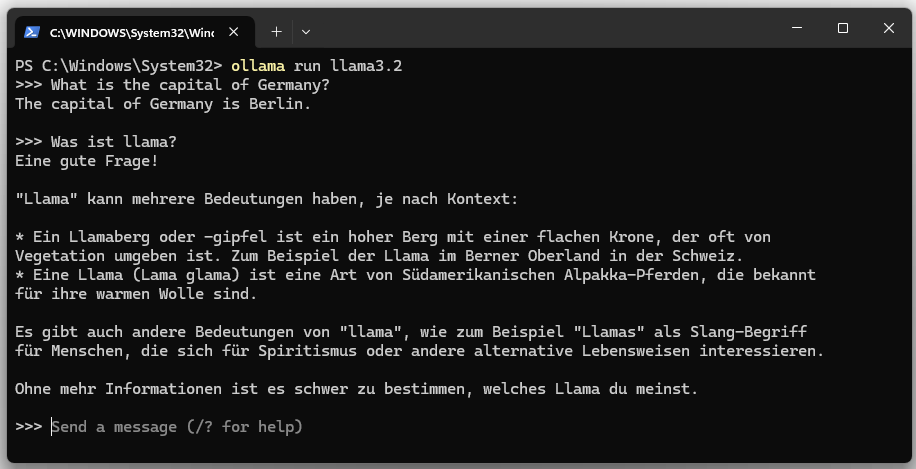
Das Sprachmodell lässt sich mit “Ctrl + d” oder mit dem Kommando “/bye” anhalten.
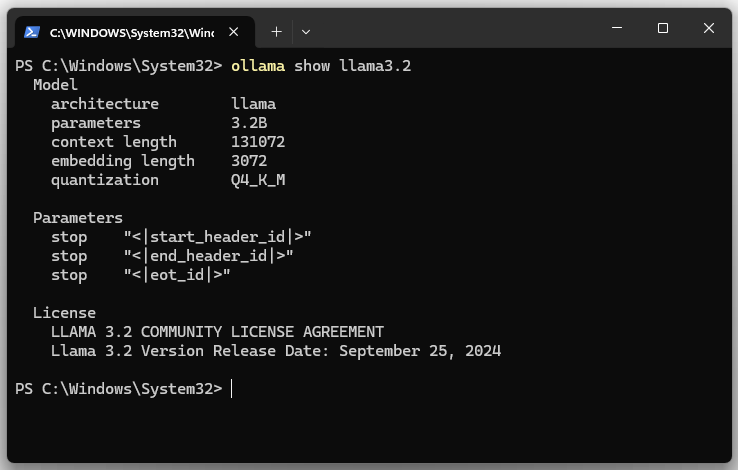
6. Modell-Details zu llama3.2 anzeigen lassen.
ollama show llama3.2
| Parameter | |
|---|---|
| architecture | Gibt die Architektur des Modells an. Die Architektur definiert den Aufbau des neuronalen Netzwerks. LLaMA ist eine Familie von Transformer-Modellen. |
| parameters | Zeigt die Anzahl der Modellparameter. Das Modell hat 3.2B (3,2 Milliarden) Parameter. Die Parameter sind die Gewichte und Biases des Modells. |
| context length | Gibt die maximale Länge des Kontexts (in Token) an, die das Modell während der Verarbeitung berücksichtigen kann. Der Wert ist 131072 (131.072 Token). Eine längere Kontextlänge ermöglicht es dem Modell, längere Texte, Dokumente oder Konversationen zu analysieren, ohne relevante Informationen zu verlieren. |
| embedding length | Gibt die verwendete Quantisierungsmethode an. Hier ist es Q4_K_M. Quantisierung ist eine Technik, um die Modellgröße zu reduzieren, indem die Präzision der Modellparameter (z. B. von 32-Bit auf 4-Bit) verringert wird. |
| size | Dies ist die tatsächliche Festplattengröße, die erforderlich ist, um das Modell zu speichern. |
| download name | Der Name des Modells. |
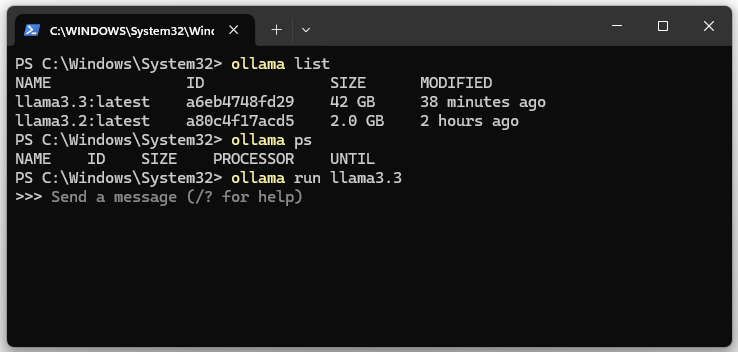
7. Laufende LLM bzw. llama3.x Instanzen anzeigen lassen.
ollama ps
8. Ollama Server anhalten
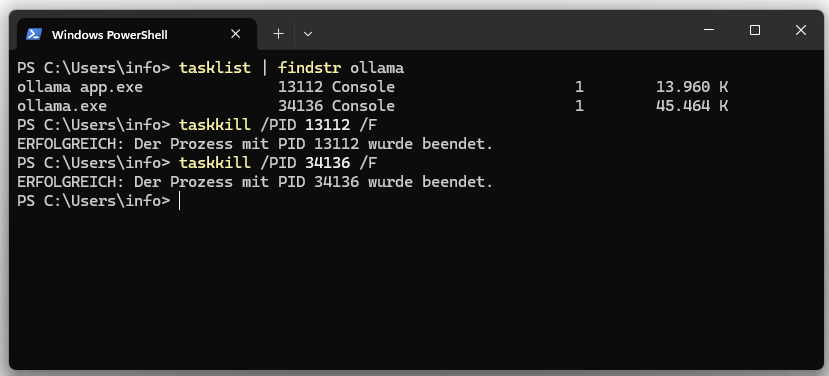
Der beiden Prozesse lassen sich über den Taskmanager oder Bash beenden.
tasklist | findstr ollama taskkill /PID /F
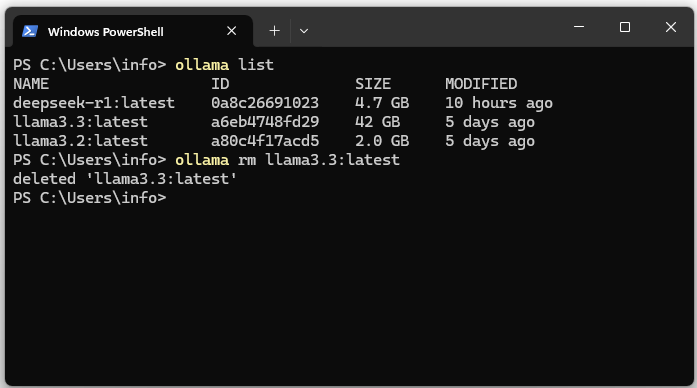
09. Ollama Modell deinstallieren

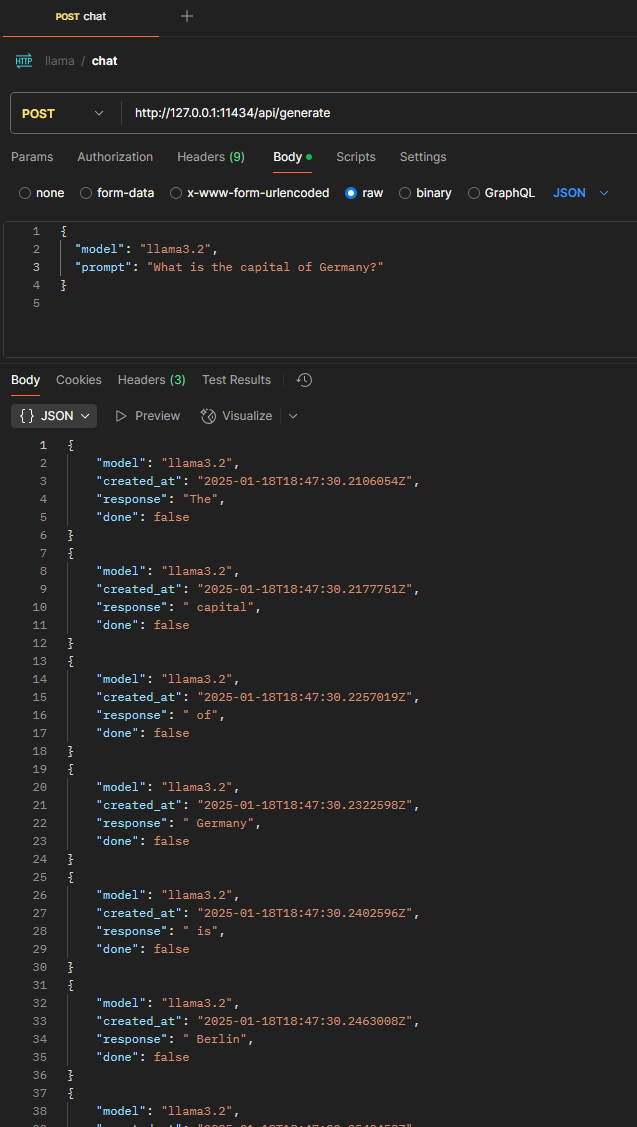
10. REST Aufruf via Postman
| Request Type | POST |
|---|---|
| Content-Type | application/json |
| Request Body | { “model”: “llama3.2”, “prompt”: “What is the capital of Germany?” } |