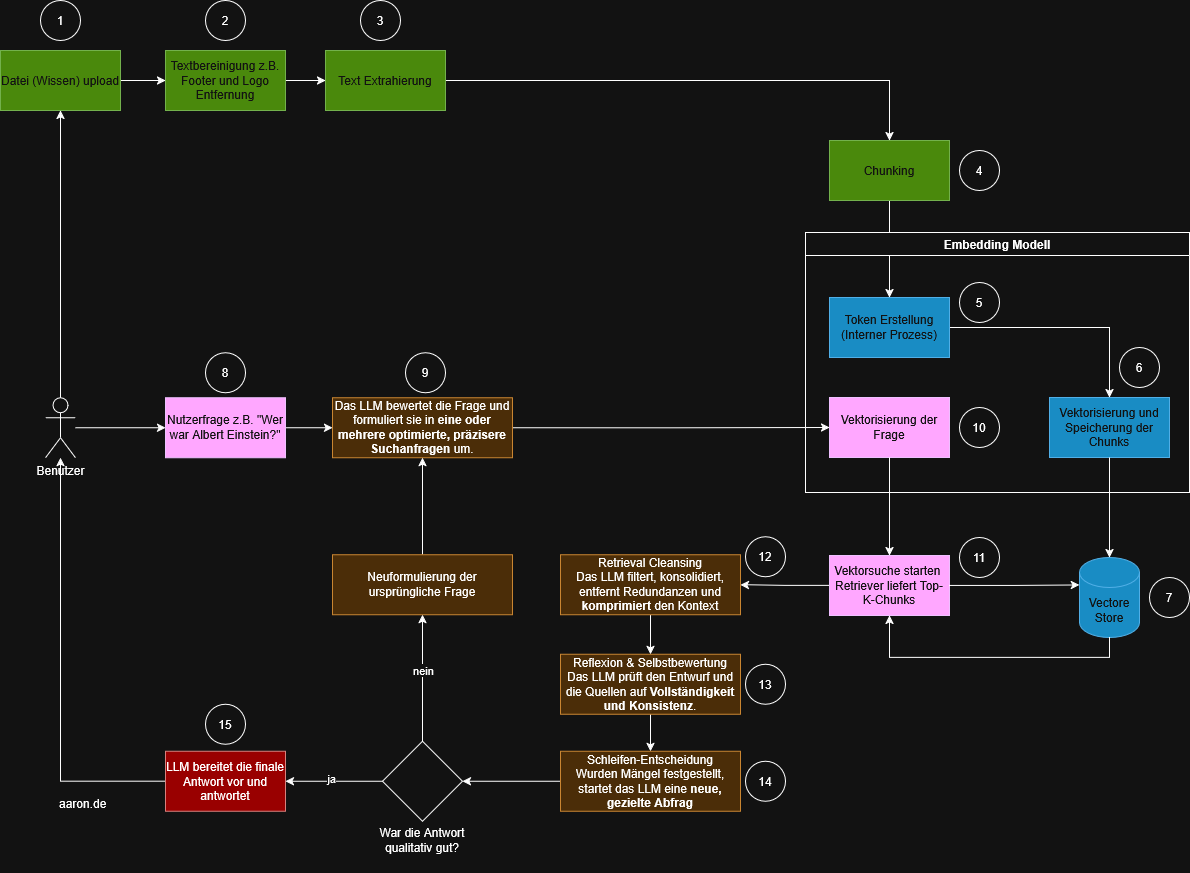
Bau eines automatischen KI-News-Bots mit n8n, LLM & Telegram
Einleitung Jeden Tag erscheinen hunderte neue Artikel über KI und Technik. Niemand hat die Zeit, das alles manuell zu durchsuchen. Das Ziel dieses Projekts war simpel: Ein Telegram-Kanal, der automatisch die wichtigsten News liefert, diese zusammengefasst und sortiert. Das Ergebnis dieses Systems ist für jeden zugänglich. Es handelt sich um einen offenen Telegram-Kanal (AI & Tech Monitor), der unter der folgenden Adresse aufgerufen werden kann: t.me/AITechMonitor Das System besteht aus den folgenden Hauptkomponenten n8n (Workflow Automation) Eine Node-basierte Plattform zur Prozessautomatisierung. Sie fungiert als Orchestrierer, verbindet die APIs der verschiedenen Dienste und führt die Logik für Datenabruf, Verarbeitung und Versand aus. ...