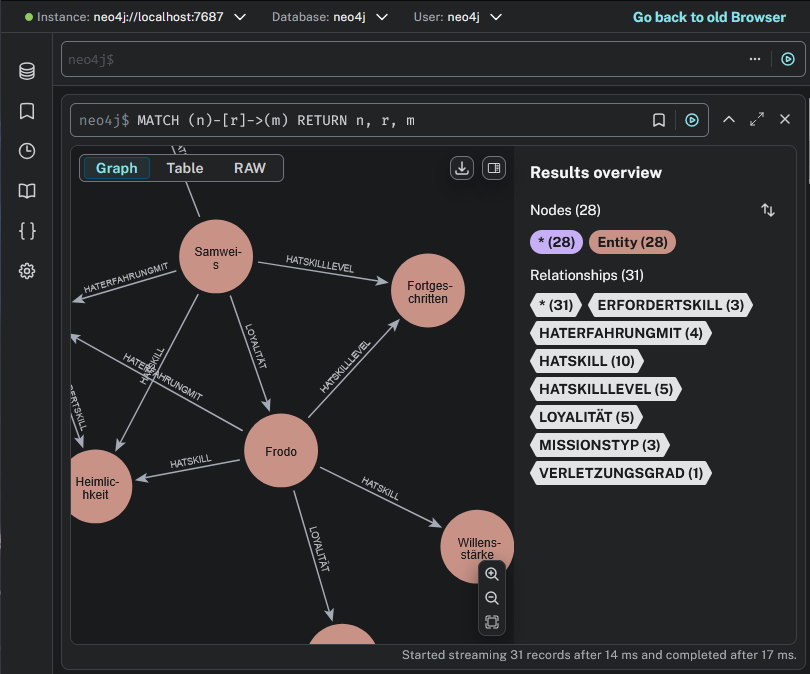
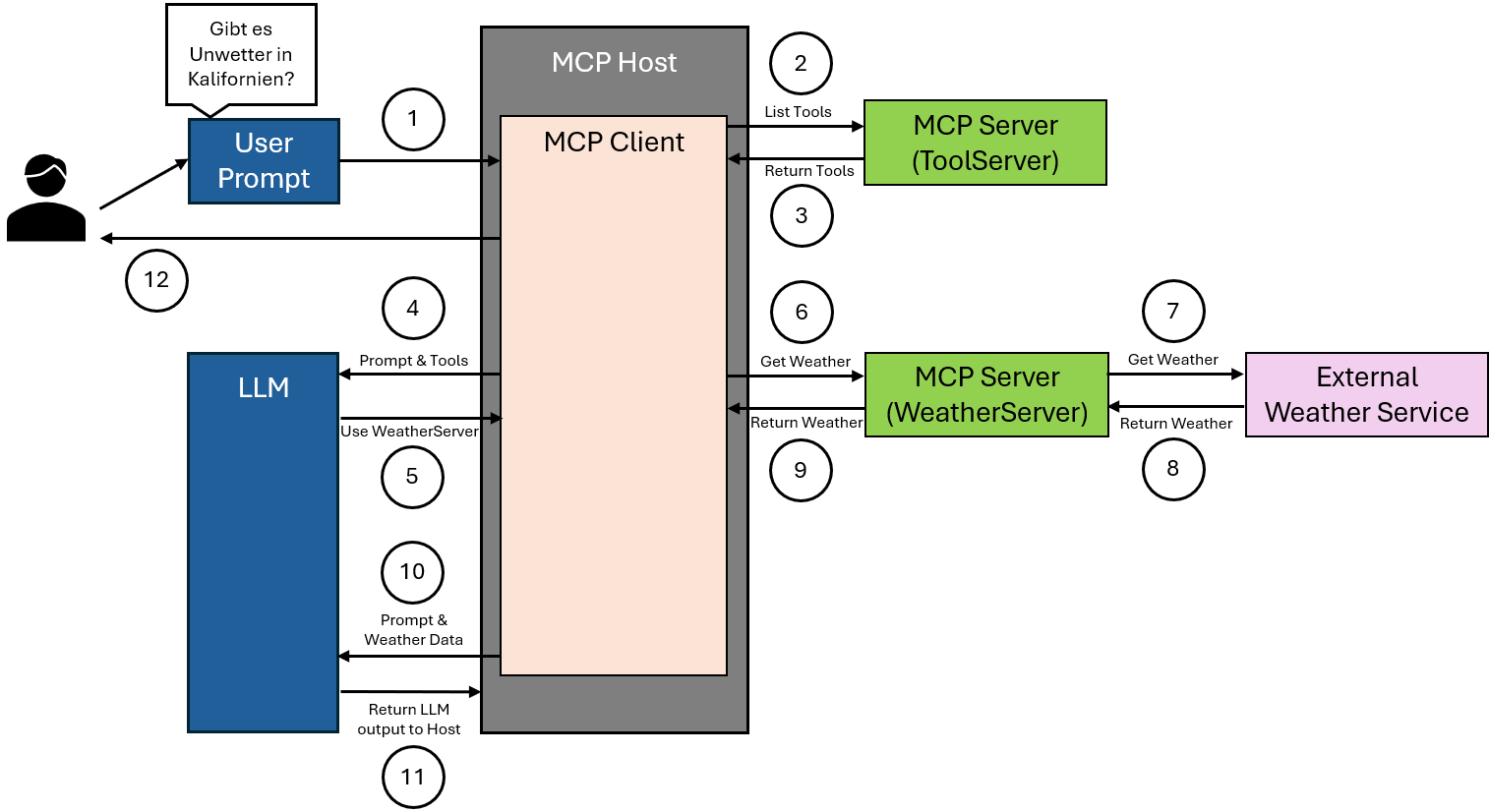
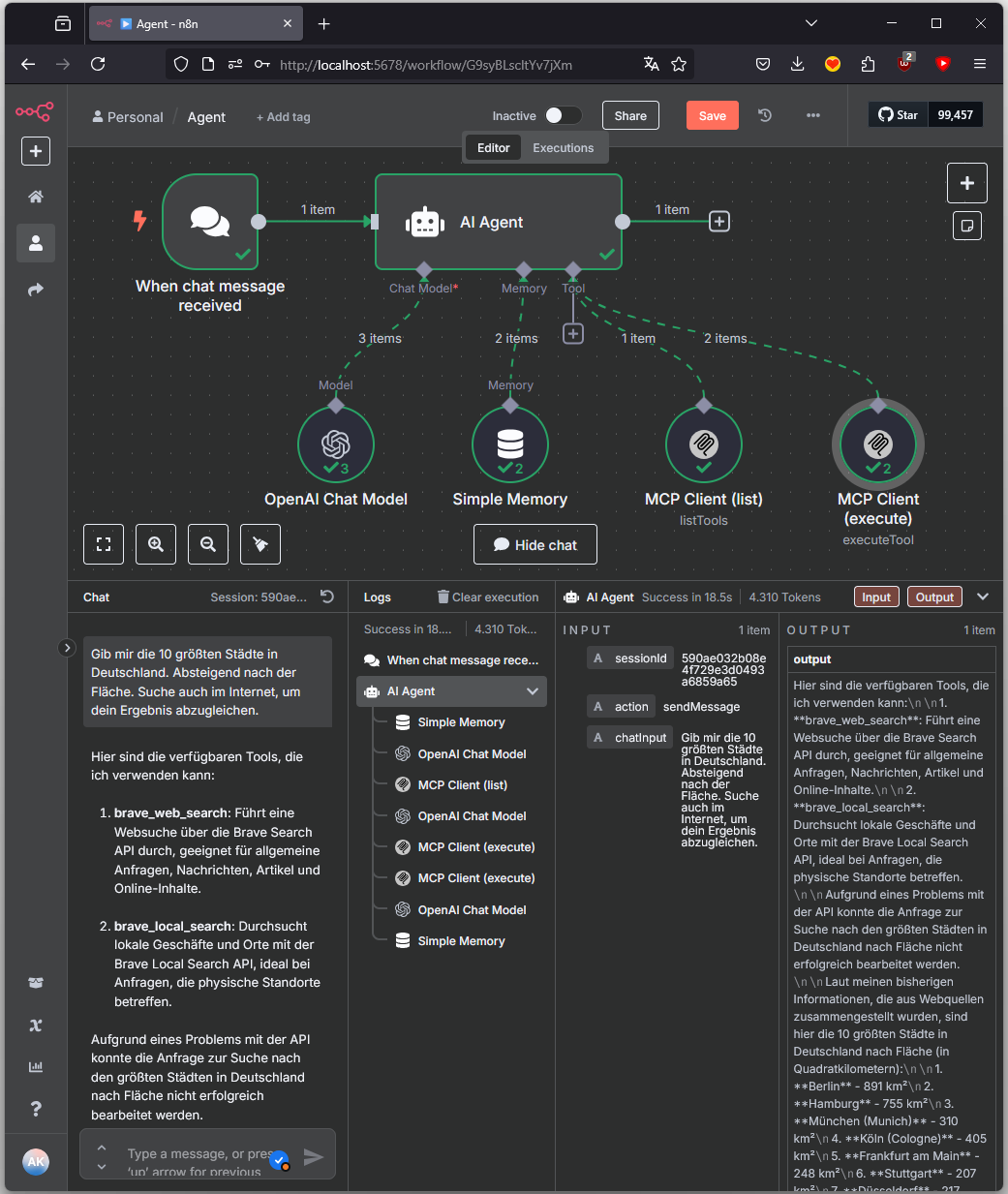
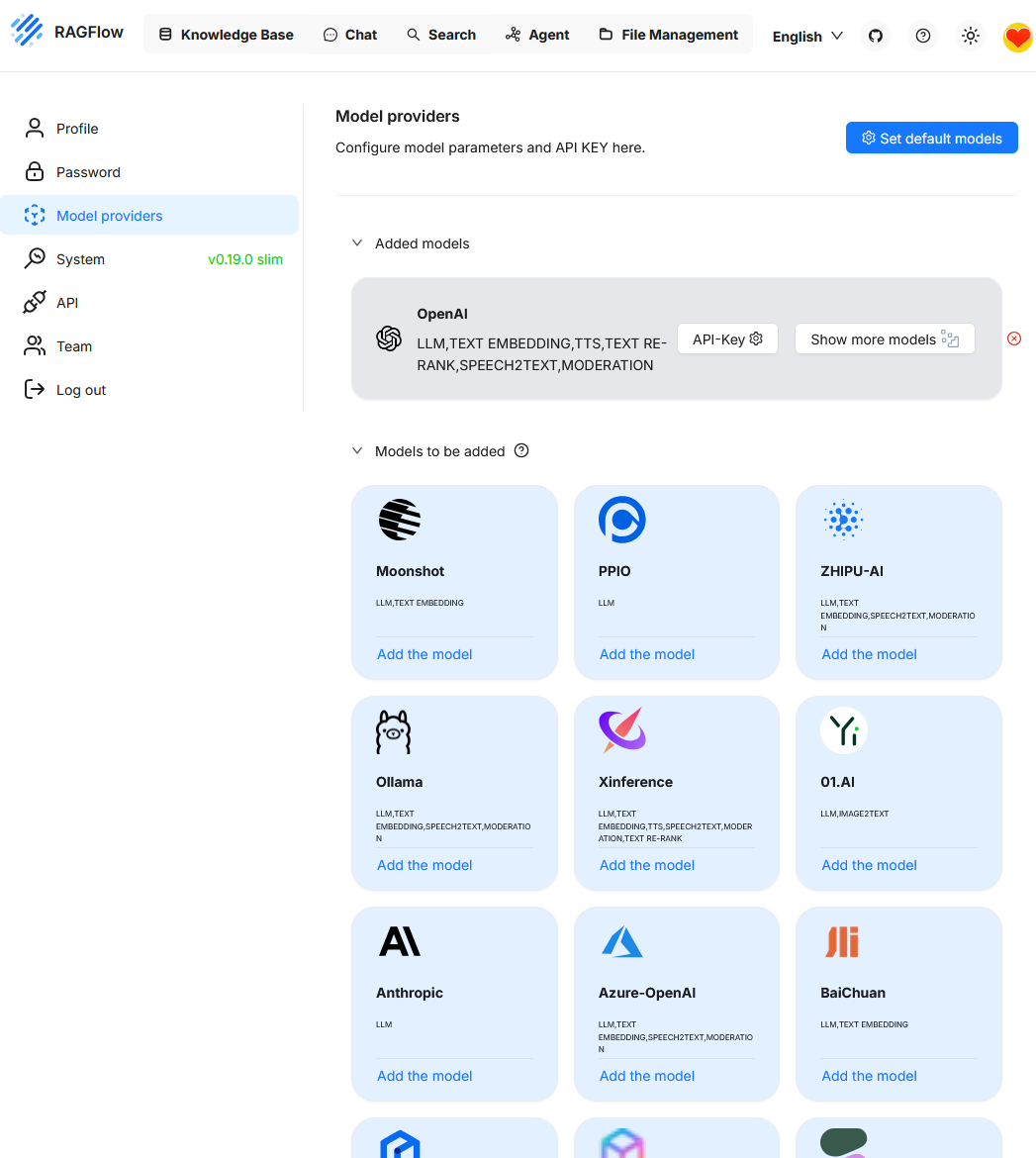
Teil 2: Strategien für bessere Ergebnisse mit RAG
In Teil 1 haben wir gesehen, wie entscheidend eine saubere Dokumentenaufbereitung und ein durchdachtes Chunking für die Qualität von Retrieval Augmented Generation sind. Diese Grundlagen bilden den Startpunkt für eine ganze Reihe weiterer Optimierungen, die den gesamten Prozess prägen. In Teil 2 setzen wir die Reihe fort und widmen uns den nächsten Bausteinen, die auf dieser Basis aufbauen und den Einsatz von RAG im Unternehmen weiterentwickeln. Embedding Domänenspezifische Embeddings Domänenspezifische Embeddings bedeuten, dass Vektordarstellungen von Texten nicht mit allgemein trainierten Embeddingmodellen erzeugt werden, sondern mit Modellen, die auf die Fachsprache und Inhalte einer bestimmten Branche oder eines Unternehmens angepasst wurden. Allgemeine Modelle sind auf sehr große, unspezifische Textmengen trainiert, darunter Bücher, Webseiten, Wikipedia und weitere Quellen. Sie verstehen Alltagssprache und viele Standardkonzepte, verfehlen aber oft die Feinheiten in z.B. juristischen Verträgen, technischen Handbüchern oder medizinischen Befunden. Domänenspezifische Embeddings entstehen durch Feintuning eines vorhandenen Modells mit Daten aus der jeweiligen Fachdomäne oder durch Training eines eigenen Modells auf einem Korpus aus internen Dokumenten, Richtlinien, Protokollen und Handbüchern. ...