Sende Nachricht via LangChain an ChatGPT
Hier senden wir eine Nachricht via LangChain an ChatGPT und geben die Antwort aus.
Mit “chain” eine Verkettung vornehmen
Benutze “chain” um das Model und den Parsen miteinander zu verketten.
Template Prompts
Die Prompts mit einem Template vorbereiten.
Verwende das Template:
Die Zielsprache wird ausgelagert:
Weitere Verkettungen
Verkette das Template mit model & parser:
Server via FastAPI & REST Endpoint
Erstelle via FastAPI einen Server. Der Server lädt die Anwendung (app.py), nimmt die REST Anfrage entgegen und gibt die Übersetzung aus:
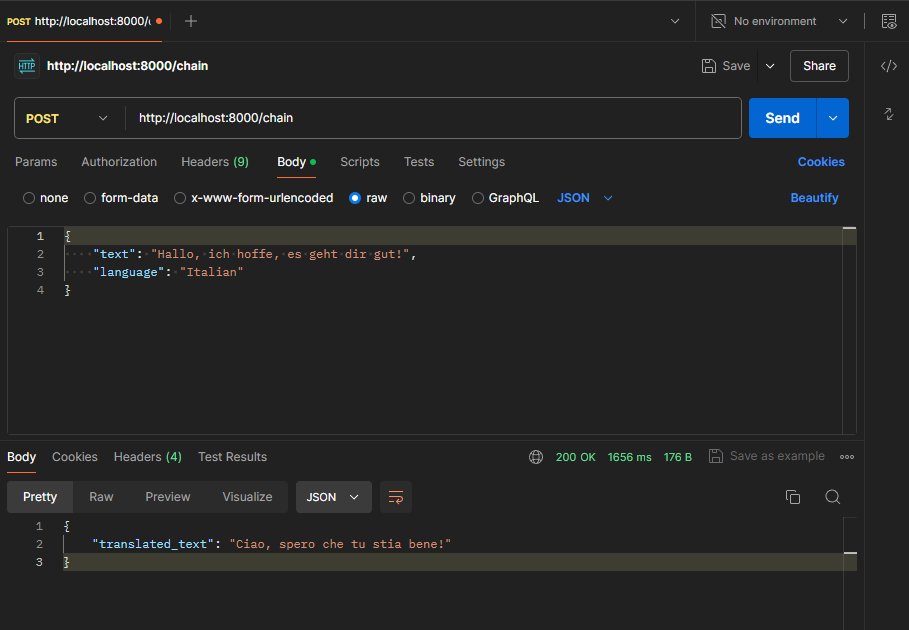
Chatbot
Dieser Bot gibt alle Anfragen 1:1 an ChatGPT weiter und dient daher als “Proxy”.
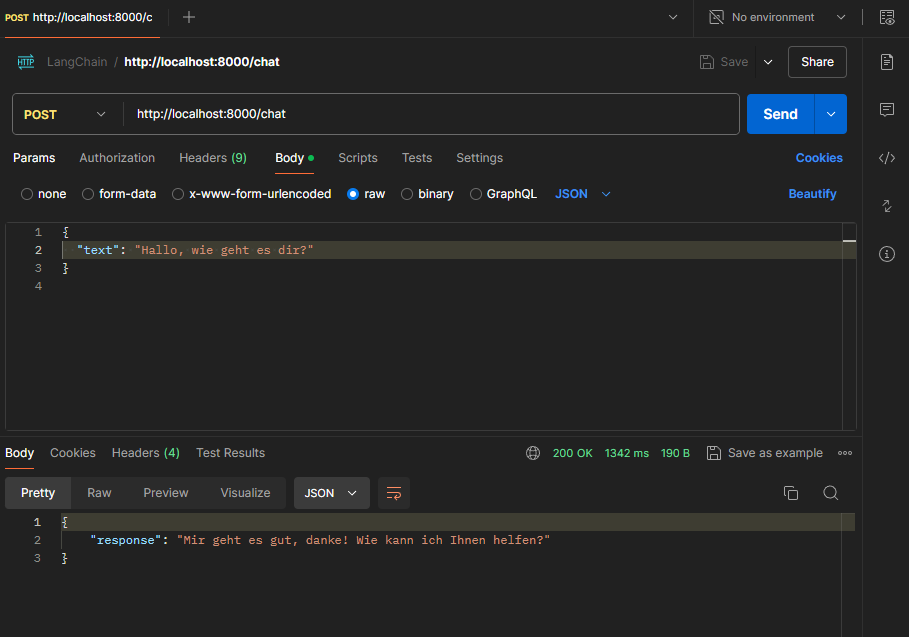
Chatbot inkl. Prompt Template
Chatbot inkl. Prompt Template & SessionID Abfrage
Chatbot Anfragen nur noch via Session-ID beantworten. SessionID Abfrage wurde wieder ausgebaut:
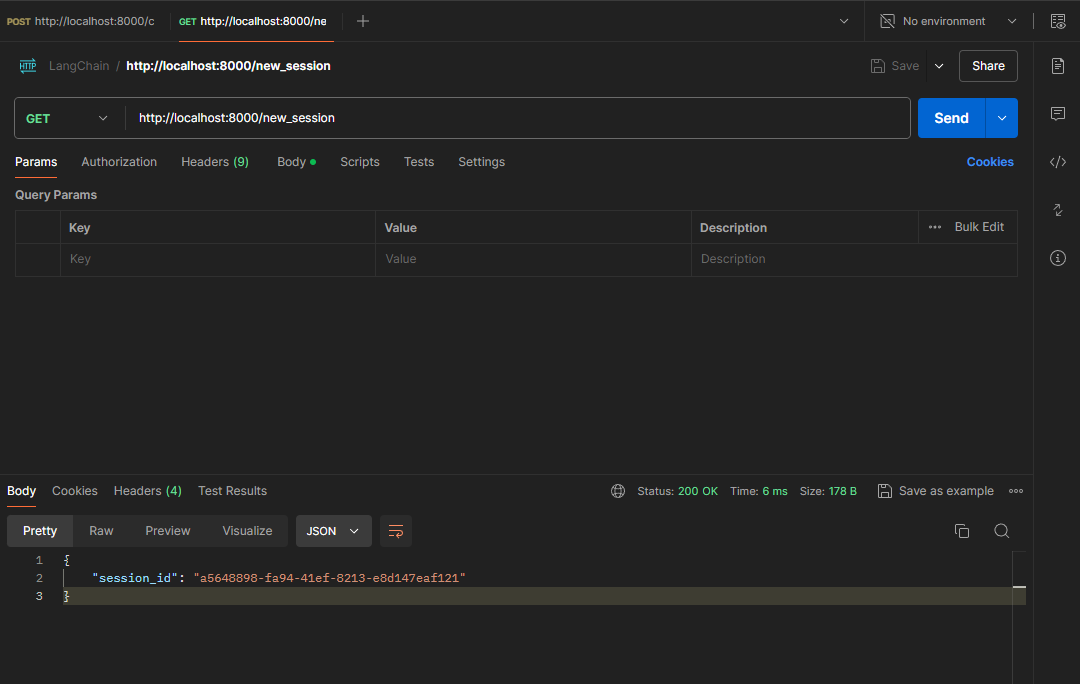
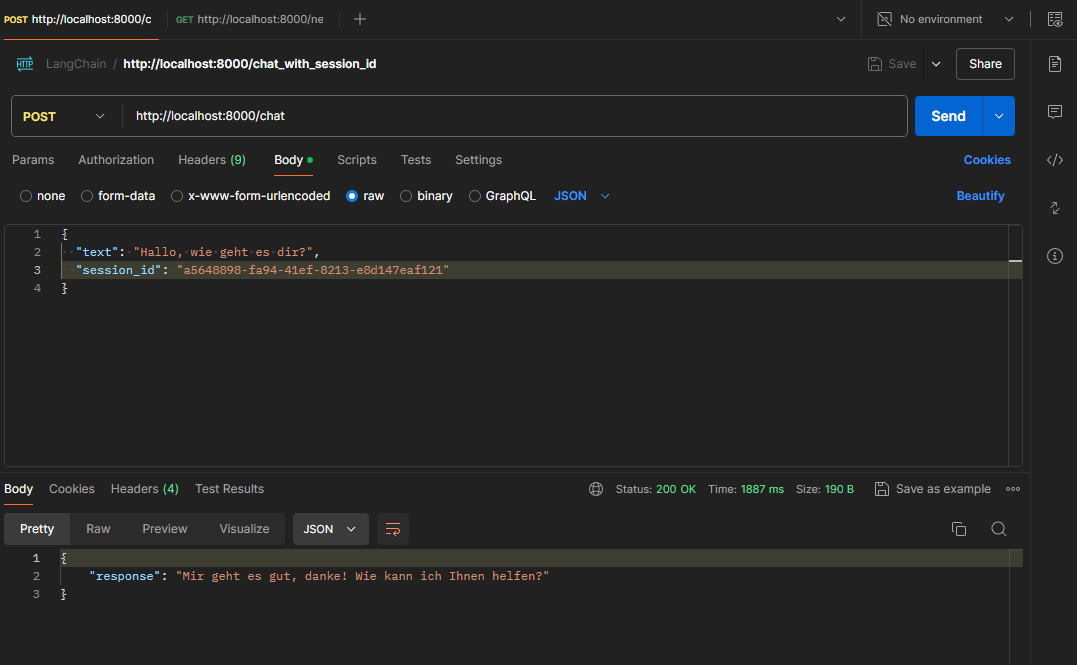
Chatbot inkl. Prompt Template & Limitierung der History Länge & Ausgabe als Stream
History Länge limitieren und die Antwort des Bots als Stream ausgeben. SessionID Abfrage wurde wieder ausgebaut.
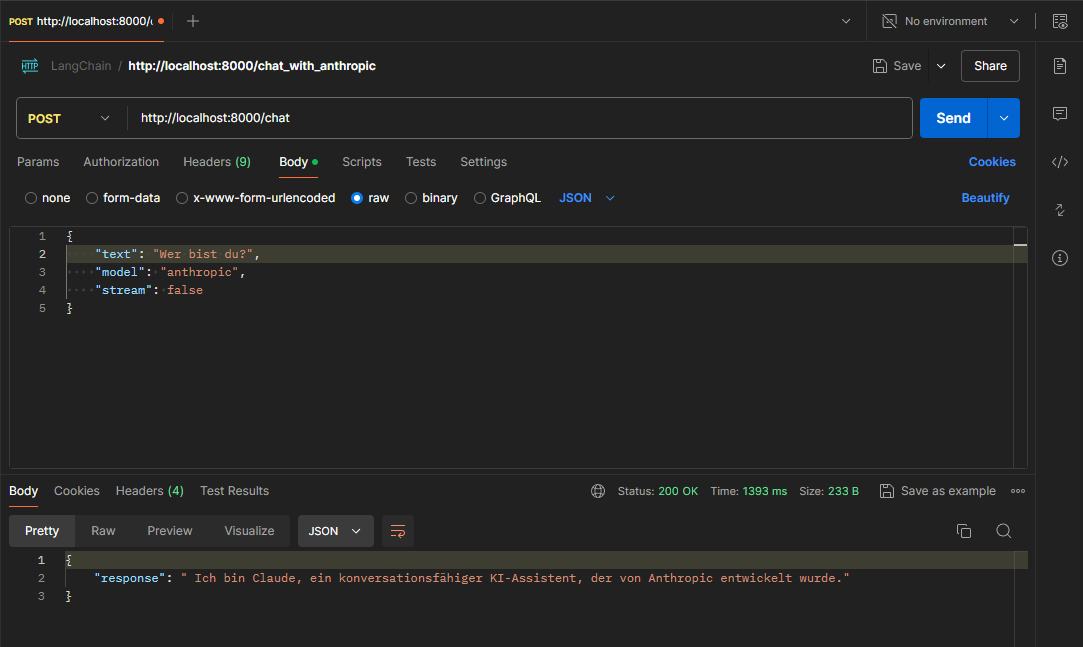
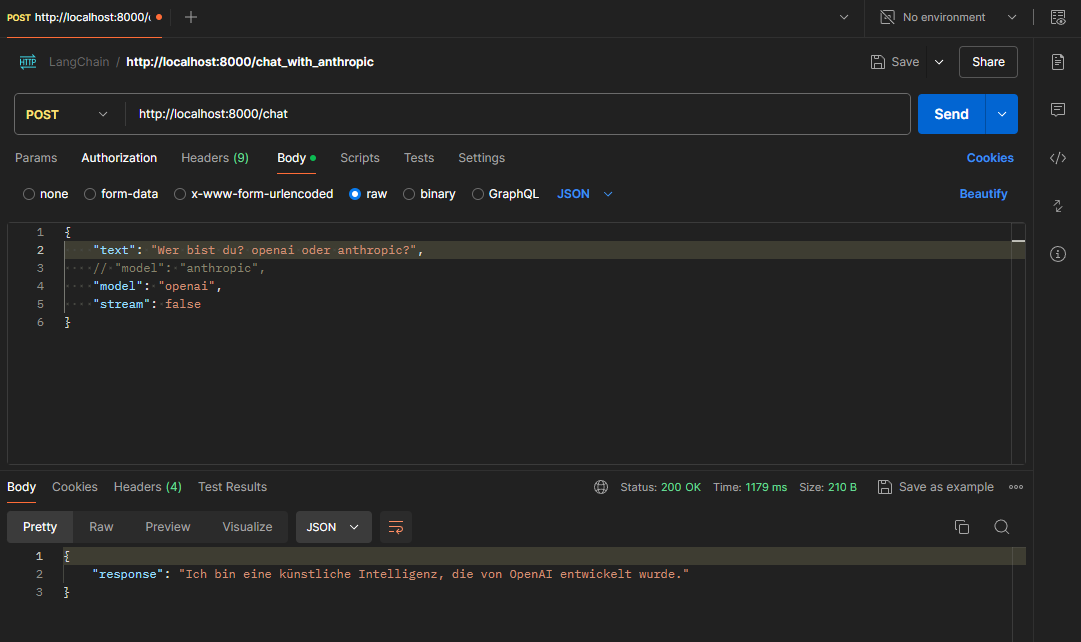
Anfrage via Agent an Anthropic oder OpenAI senden
Innerhalb der REST-Anfrage kann von jetzt an angegeben werden, ob OpenAI (ChatGPT) oder Anthropic (Claude) verwendet werden soll.
Aufruf von Anthropic:
Aufruf von OpenAI:
Die transformers-Bibliothek, bereitgestellt von Hugging Face, ist eine der populärsten Bibliotheken zur Arbeit mit vortrainierten Modellen für die Verarbeitung natürlicher Sprache (NLP). Diese Bibliothek bietet eine einfache Möglichkeit, auf eine Vielzahl von NLP-Modellen zuzugreifen und diese zu verwenden, darunter Modelle für Textgenerierung, Klassifikation, Übersetzung und viele andere Aufgaben.
Die transformers-Bibliothek (pip install transformers) ist notwendig für:
Tokenisierung: Die transformers-Bibliothek enthält Tokenizer, die Text in kleinere Einheiten (Tokens) zerlegen. Dies ist entscheidend, um sicherzustellen, dass die Anzahl der Tokens innerhalb der von den Modellen festgelegten Grenzen bleibt.
Token-Zählung: Die Funktion trim_messages berechnet die Anzahl der Tokens in einem Text.