Einleitung
Spätestens mit dem Aufkommen großer Sprachmodelle (LLMs) wie GPT stellt sich vielen die Frage, wie man solchen Modellen strukturierte, präzise Informationen zur Verfügung stellen kann. Denn obwohl LLMs in der Lage sind, Fragen sehr überzeugend zu beantworten, beruhen viele ihrer Antworten lediglich auf sprachstatistischen Wahrscheinlichkeiten, nicht auf logischem Schließen oder explizitem Faktenwissen. An dieser Stelle bietet der Einsatz einer Ontologie einen systematischen Mehrwert.
Im folgenden Beitrag wird anhand einer fiktiven Mission im „Herr der Ringe“-Universum gezeigt, wie eine Ontologie ein LLM bei der Beantwortung komplexer Fragen unterstützen kann.
Was ist eine Ontologie?
Eine Ontologie ist ein formales Modell zur strukturierten Repräsentation von Wissen. Sie dient dazu, reale Sachverhalte, Zusammenhänge und Abhängigkeiten durch Konzepte und deren Beziehungen abzubilden. Technisch basiert sie in der Regel auf dem RDF-Modell (Resource Description Framework), bei dem Wissen in Form von Tripeln dargestellt wird: ein Subjekt, ein Prädikat und ein Objekt. Diese Tripel bilden die grundlegende Einheit zur Beschreibung von Fakten und Beziehungen in einer Wissensdomäne.
Statt Begriffe einfach aufzulisten, modelliert eine Ontologie die Realität in ihrer Abhängigkeit. Dabei wird beschrieben, wie Entitäten zueinander in Beziehung stehen. So kann etwa festgehalten werden, dass ein Subjekt („Aragorn“) über ein bestimmtes Merkmal („Schwertkampf“) verfügt. Diese Beziehung wird durch ein Prädikat („hatSkill“) ausgedrückt. Aragorn, ein Hauptcharakter aus Herr der Ringe, ist ein erfahrener Kämpfer mit ausgeprägten Fähigkeiten im Schwertkampf und in der Führung.
Dieses strukturierte Wissen kann durch maschinelle Systeme wie ein LLM (Large Language Model) genutzt werden, um präzisere Antworten zu geben, vor allem dann, wenn das Modell nicht auf rein statistische Wahrscheinlichkeiten zurückgreift, sondern auf explizit modelliertes Hintergrundwissen.
Solche Tripel lassen sich in Graphdatenbanken wie Neo4j speichern und mit Python-Bibliotheken wie py2neo, rdflib oder networkx analysieren und visualisieren.
Beispiel Ontologie:
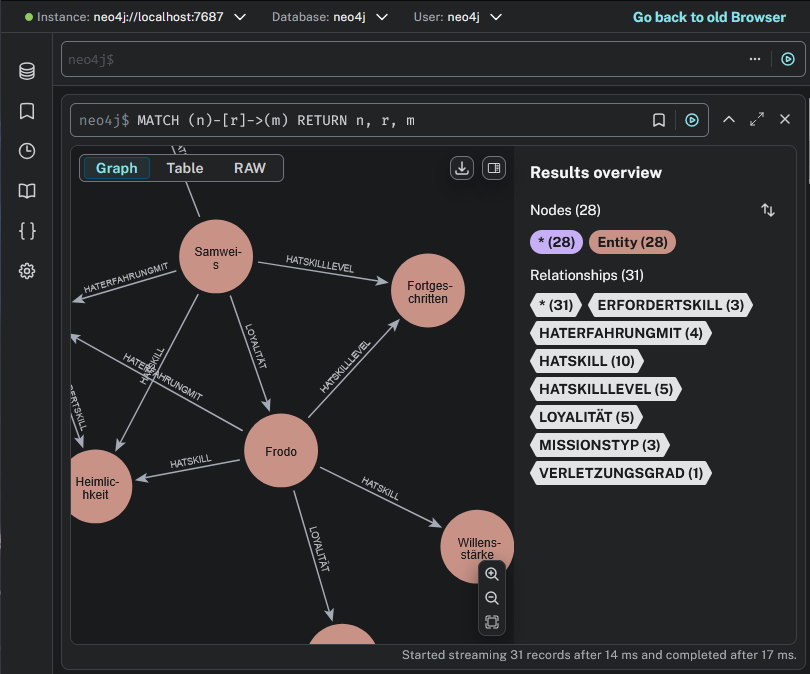
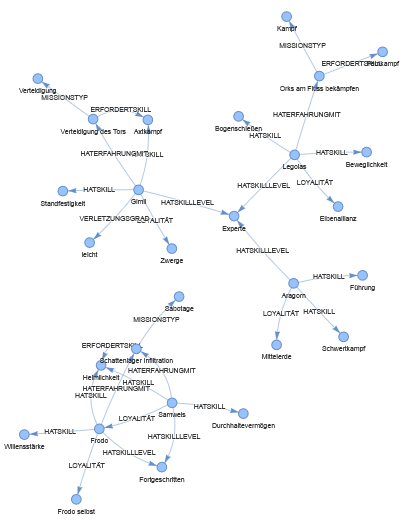
Nehmen wir an, wir modellieren eine Ontologie mit Charakteren aus Herr der Ringe. In dieser Ontologie sind folgende Informationen enthalten:
Visuelle Darstellung der obigen Ontologie:
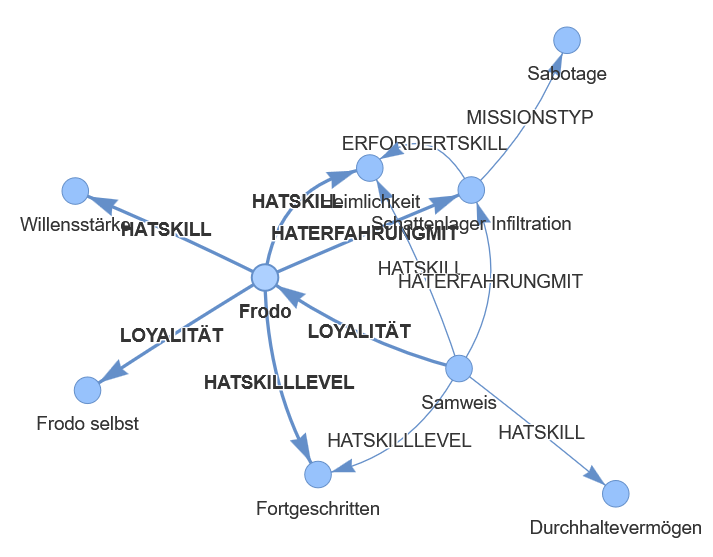
Frodo Detailansicht:
Was leistet eine Ontologie im Zusammenspiel mit einem LLM?
Statt einem LLM einfach eine offene Frage zu stellen (und damit dem Modell zu überlassen, ob es auf Halluzinationen oder Fragmentwissen zurückgreift), kann man das LLM so steuern, dass es zunächst strukturiertes Wissen aus einer Ontologie berücksichtigt. Das hat mehrere Vorteile:
Konsistenz
Das LLM bezieht sich nur auf definierte und überprüfbare Fakten.Einschränkung des Suchraums
Die Antwortsuche wird gezielt geführt.Explainability
Entscheidungen können über den zugrunde liegenden Graph nachvollzogen werden.Kombination von Logik und Sprache
Die Ontologie liefert die Fakten, das LLM formuliert elegant.
Beispiel: Eine Mission im Herr-der-Ringe-Universum
Angenommen, wir haben die folgende Frage und fragen ein LLM nach der Antwort:
ChatGPT bzw. das LLM Antwort auf diese Frage wie folgt:
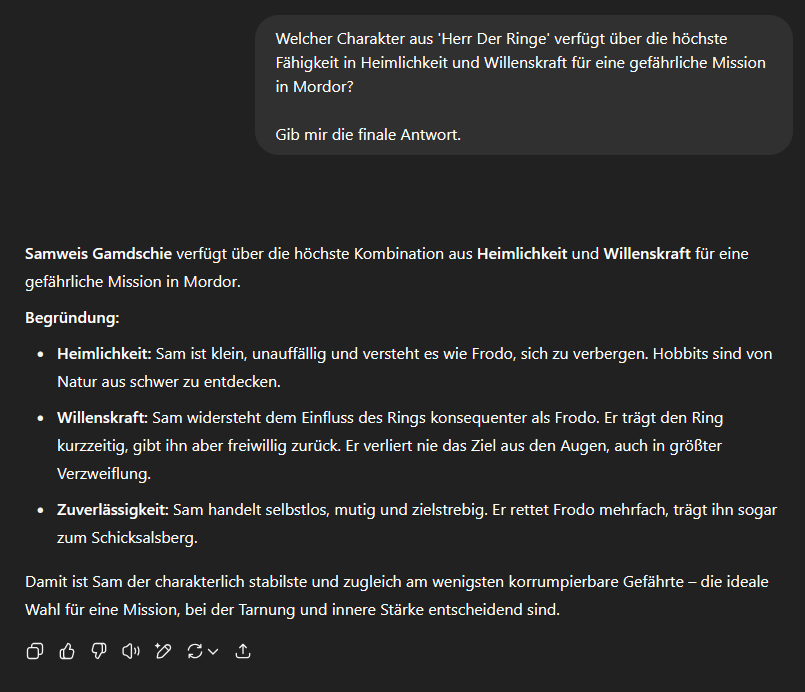
Im gezeigten Beispiel wird deutlich, wie ein LLM, in diesem Fall ChatGPT, zwar inhaltlich nachvollziehbare Antwort liefert, dabei jedoch nicht zwingend korrekt auf eine spezifische Faktenlage reagiert. Die gegebene Antwort basiert auf einem allgemeinen Weltwissen, das das Modell während seines Trainings aus einer Vielzahl öffentlich zugänglicher Quellen gelernt hat. Sie reflektiert damit eine wahrscheinliche Sichtweise, aber nicht notwendigerweise die tatsächlichen, im aktuellen Kontext geltenden Fakten.
LLMs arbeiten im Kern auf der Basis von Wahrscheinlichkeiten. Sie berechnen, welche Antwort auf eine Eingabe statistisch am wahrscheinlichsten erscheint, basierend auf dem Sprach- und Wissensraum, in dem sie trainiert wurden. In vielen Fällen führt das zu plausiblen Ergebnissen. Doch sobald die Fragestellung auf domänenspezifisches Wissen abzielt, etwa internes Fachwissen, projektbezogene Zusammenhänge oder speziell kuratierte Fakten, stoßen solche Modelle ohne zusätzliche Steuerung an Grenzen.
Hier kommt der Mehrwert einer Ontologie ins Spiel. Eine Ontologie ermöglicht es, solches Spezialwissen strukturiert zu modellieren, also welche Entitäten existieren, welche Eigenschaften sie haben und wie sie zueinander stehen. In einer Ontologie kann exakt festgelegt werden, dass Frodo sowohl über die Fähigkeit Heimlichkeit als auch über Willensstärke verfügt, während Samweis zwar Heimlichkeit, aber keine Willensstärke besitzt. Dieses Wissen ist explizit hinterlegt und maschinenlesbar.
Durch die Einbindung eines solchen strukturierten Wissensmodells in die LLM-Verarbeitung wird die ursprüngliche Wahrscheinlichkeitsverteilung gezielt beeinflusst. Das LLM muss nicht mehr erraten, wer geeignet sein könnte, sondern es erhält klare Fakten, auf deren Basis die Antwort generiert wird. Die Wahrscheinlichkeit für eine korrekte und spezialisierte Antwort steigt deutlich, weil das Modell nicht mehr ausschließlich auf seinem generalisierten Trainingswissen basiert, sondern zusätzlich auf spezialisierte, kontextspezifische Informationen zugreift.
Die Ontologie wirkt somit als semantische Leitstruktur. Sie erhöht die faktische Treffsicherheit und zwingt das Modell, innerhalb eines Bedeutungskontexts zu argumentieren. Besonders in realen Anwendungsszenarien, etwa in Unternehmen, medizinischen Systemen oder technischen Assistenzlösungen, kann diese Integration über den Unterschied zwischen plausibel und korrekt entscheiden.
Erweiterung von Prompts durch Ontologie-Wissen zur präziseren LLM-Antwortgenerierung
Bevor eine Frage an das Sprachmodell gesendet wird, wird der ursprüngliche Prompt durch strukturiertes Wissen aus der Ontologie ergänzt. Dieses Wissen besteht aus Tripeln, die relevante Informationen über die Domäne enthalten, zum Beispiel über Eigenschaften von Figuren oder Zusammenhänge zwischen Konzepten. Durch die Einbettung dieser Fakten kann das Sprachmodell nicht nur auf statistische Muster zurückgreifen, sondern gezielt auf das bereitgestellte Spezialwissen zugreifen. Das führt zu besseren, nachvollziehbaren und domänenspezifisch korrekten Antworten.
Nach der Erweiterung des Prompts durch die Metadaten erhalten wir als Antwort “Frodo” statt wie zuvor “Samweis”.
Zur Beantwortung der Frage wurde im aktuellen Beispiel die gesamte Ontologie in den Prompt eingebunden. Alle verfügbaren Fakten wurden dem LLM vollständig mitgegeben, um sicherzustellen, dass die Antwort ausschließlich auf dem modellierten Wissen basiert. Dieses Vorgehen funktioniert in kleineren Beispielen, eignet sich aber nicht für reale, umfangreiche Anwendungen.
In professionellen Umgebungen enthalten Ontologien oft zehntausende oder sogar Millionen Einträge. Es wäre ineffizient, jedes Mal alle Informationen zu übertragen, da
die maximale Eingabelänge des Modells überschritten werden kann
unnötige Informationen die Rechenzeit verlängern
viele irrelevante Fakten im Prompt enthalten wären
Deshalb wird in der Praxis nur ein relevanter Ausschnitt aus der Ontologie verwendet, der zur aktuellen Frage passt.
Wie eine sinnvolle Auswahl funktioniert
Eine Ontologie ist ein strukturiertes Modell aus Subjekten, Prädikaten und Objekten. Die Auswahl der relevanten Informationen zur Beantwortung einer konkreten Frage erfolgt nicht durch statistische Ähnlichkeit oder semantisches Raten, sondern durch strukturierte Traversierung der modellierten Beziehungen.
Entscheidend ist, dass man aus der Ontologie gezielt jene Teilmengen auswählt, die inhaltlich in Abhängigkeit zur Fragestellung stehen. Dafür werden keine ML-Modelle benötigt, sondern regelbasierte Mechanismen:
Beziehungsorientierte Navigation
Über Abfragen wie „MATCH (c:Charakter)-[:HATSKILL]->(s:Skill) WHERE s.name = ‘Heimlichkeit’“ kann man gezielt alle Entitäten finden, die mit dem gesuchten Konzept in Verbindung stehen.Pfadbasierte Selektion
Es kann definiert werden, dass nur Entitäten berücksichtigt werden, die mit bestimmten Missionsanforderungen über mehrere Kanten hinweg verknüpft sind, z. B. über „erfordertSkill“ und „hatSkill“.Einschränkung nach Attributen
Durch gezielte Filterung auf Knotenattribute wie „hatSkillLevel = Experte“ wird die Auswahl weiter eingegrenzt.Graphorientierte Nachbarschaftsanalyse
Man kann mit festen Regeln entscheiden, welche benachbarten Knoten entlang definierter Prädikate betrachtet werden sollen, um zum Beispiel Erfahrungen, Loyalitäten oder Verfügbarkeiten in die Auswahl einzubeziehen.
Diese Form der Selektion nutzt die Struktur der Ontologie, also ihre expliziten Kanten und Knoten, um genau die Wissenselemente zu extrahieren, die für die Fragestellung notwendig sind.
Ein LLM kommt erst nachgelagert ins Spiel, um auf Basis dieser verdichteten Faktenlage eine sprachliche Antwort zu formulieren. Die Qualität der Antwort hängt daher wesentlich von der Qualität und Relevanz der zuvor ausgewählten Teilstruktur der Ontologie ab.
neo4j
Neo4j ist eine Graphdatenbank, die speziell dafür entwickelt wurde, Beziehungen zwischen Daten effizient abzubilden und abzufragen. Im Gegensatz zu klassischen relationalen Datenbanken speichert Neo4j Informationen nicht in Tabellen, sondern in Form von Knoten (Entities), Kanten (Beziehungen) und Eigenschaften.
Mit Neo4j lassen sich komplexe, vernetzte Strukturen modellieren und analysieren:
Ontologien und Wissensgraphen (z. B. welche Person hat welche Fähigkeit und welche Aufgabe erfordert sie)
Soziale Netzwerke (z. B. wer kennt wen)
Empfehlungssysteme (z. B. welche Produkte passen zum Nutzerverhalten
Betrugserkennung (z. B. ungewöhnliche Muster in Zahlungsströmen)
IT-Architekturen (z. B. welche Systeme sind wie miteinander verbunden)
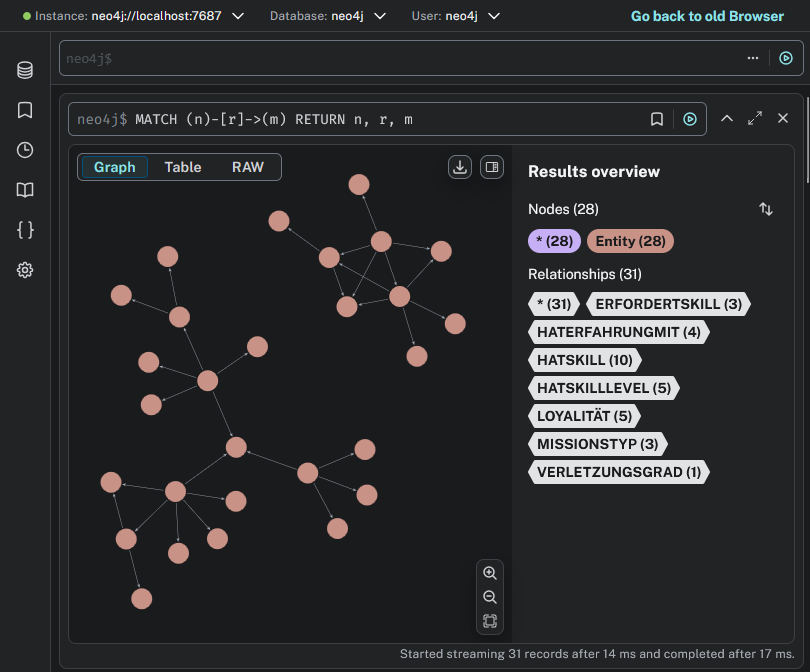
Unsere Ontologie sieht innerhalb von neo4j wie folgt aus:

Installation via Docker
Navigation via neo4j
Finde alle Charaktere (oder allgemein: Entitäten), die den Skill „Heimlichkeit“ besitzen.
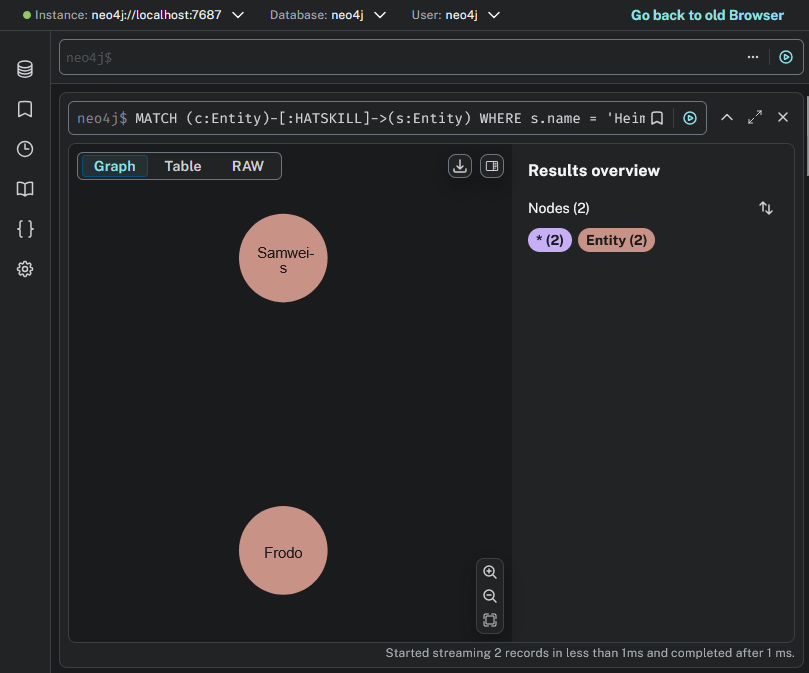
Durch diese Abfrage betrachten wir gezielt nur den für die Fragestellung relevanten Ausschnitt der Ontologie, um das Sprachmodell gezielt mit passenden Metadaten anzureichern.
Kontextuelle Reduktion der Ontologie für LLM-Abfragen
Nachdem die Ontologie gezielt nach relevanten Zusammenhängen durchsucht wurde, können dem Sprachmodell anstelle der vollständigen Ontologie nur die inhaltlich relevanten Abhängigkeiten als Kontext übergeben werden.
LLM Antwort
Code Beispiel
OWL (Web Ontology Language)
In den vorherigen Abschnitten haben wir gesehen, wie eine Ontologie in Form eines Graphen mit einfachen Tripeln (Subjekt-Prädikat-Objekt) die Qualität der Antworten eines LLMs drastisch verbessern kann. Wir haben Entitäten wie Frodo und Heimlichkeit und die Beziehung hatSkill zwischen ihnen modelliert.
Dieser Ansatz ist bereits sehr mächtig. Allerdings weiß unser System bisher nur, dass eine Verbindung besteht, aber nicht, was diese Verbindung logisch bedeutet oder welchen Regeln sie unterliegt. Um diese Lücke zu schließen und unserer Ontologie eine tiefere Ebene der “Intelligenz” zu verleihen, nutzen wir die Web Ontology Language (OWL).
OWL ist ein vom W3C standardisiertes Format zur Erstellung von umfassenden, formalen Ontologien. Man kann es sich als eine Erweiterung von RDF (dem Framework, auf dem unser Tripel-Modell basiert) vorstellen.
Wenn unser bisheriger Graph das Vokabular und die einfachen Sätze liefert, dann ist OWL die Grammatik und das Regelwerk, das die logischen Zusammenhänge dazwischen beschreibt. OWL erlaubt es uns, die Bedeutung der Begriffe und Beziehungen in unserer “Herr der Ringe”-Welt so zu definieren, dass eine Maschine sie nicht nur lesen, sondern auch verstehen und darüber schlussfolgern kann. Die Umstellung oder Erweiterung unserer Ontologie mit OWL würde uns mehrere entscheidende Vorteile bringen, die die Qualität der an das LLM übergebenen Fakten nochmals deutlich steigern.
Problem heute
In unserem Graphen sind Frodo, Heimlichkeit und Schattenlager Infiltration allesamt Knoten vom gleichen Typ (Entity). Das System weiß nicht, dass es sich um einen Charakter, eine Fähigkeit und eine Mission handelt.Lösung mit OWL
Wir können formale Klassen definieren: Charakter, Faehigkeit und Mission. Anschließend können wir sogar Hierarchien bilden, z.B. könnten Hobbit und Elb Unterklassen von Charakter sein. Frodo wäre dann eine Instanz der Klasse Hobbit.Vorteil
Das System kann viel präzisere Abfragen durchführen (“Finde alle Hobbits, die die Fähigkeit ‘Heimlichkeit’ haben”). Logische Fehler, wie eine Mission einer Loyalität zuzuweisen, werden unmöglich, und der Kontext für das LLM wird unmissverständlich klar.
Indem wir OWL verwenden, verwandeln wir unseren bestehenden Wissensgraphen von einer reinen Datensammlung in ein dynamisches, logisches Modell unserer “Herr der Ringe”-Welt. Die Fakten, die wir dann an das LLM übergeben, sind nicht nur präziser und kontextreicher, sondern können auch Wissen enthalten, das durch logische Schlussfolgerungen erst generiert wurde. Dies ist der nächste, entscheidende Schritt zur Maximierung der Antwortqualität.
Ontologie Beispiel
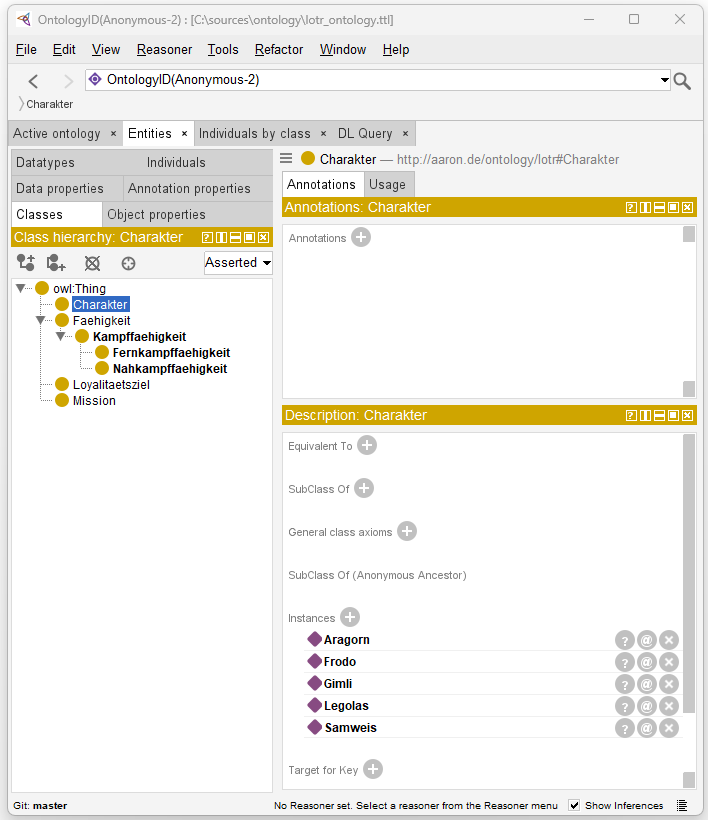
Visualisierung via Protegé
Protégé ist ein frei verfügbares Open-Source-Werkzeug zur Erstellung und Verwaltung von Ontologien, zum Beispiel in OWL. Mit Protégé lassen sich Klassen, Eigenschaften und Instanzen definieren und in Beziehung setzen. Es unterstützt sogenannte Reasoner, also logische Inferenzmaschinen, die Konsistenzprüfungen ermöglichen und zusätzliche implizite Zusammenhänge sichtbar machen. Darüber hinaus kann das Tool durch Plugins erweitert werden und existiert auch in einer webbasierten Version, die kollaboratives Arbeiten erlaubt.