Dieser Code zeigt, wie ein künstliches neuronales Netzwerk mit dem MNIST-Datensatz trainiert wird, um handgeschriebene Ziffern (0-9) zu klassifizieren. Ziel ist es, dass das Modell anhand der Bilddaten vorhersagen kann, welche Ziffer abgebildet ist.
Dies wird erreicht durch:
1. Laden und Vorverarbeiten der MNIST-Bilddaten.
2. Erstellen eines neuronalen Netzwerks mit mehreren Schichten (Layers).
3. Trainieren des Netzwerks mit Trainingsdaten.
4. Evaluieren der Leistung des Modells auf Testdaten.
5. Testen des Modells auf neuen Beispieldaten.
Das Klassifizieren von Ziffern ist ein klassisches maschinelles Lernproblem, das Anfängern hilft, die Grundlagen neuronaler Netzwerke zu verstehen. Der MNIST-Datensatz ist ideal, da er klein genug ist, um schnell trainiert zu werden, aber dennoch komplex genug, um sinnvolle Modelle zu erstellen.
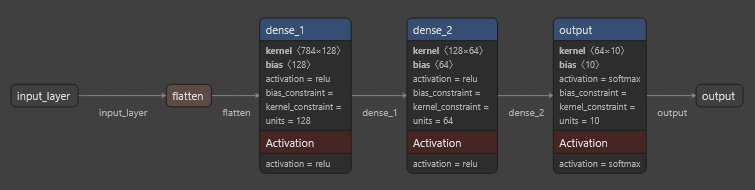
Visualisierung des Modells

Bash Ausgabe
Erklärung der Bash Ausgabe
Das sind die tatsächlichen Ziffern (Labels) der ersten zehn Bilder aus dem MNIST-Trainingsdatensatz.Dies dient dazu, die Labels zu verifizieren und sicherzustellen, dass die Daten korrekt geladen wurden.
Diese Meldung bedeutet, dass TensorFlow die CPU-Beschleunigungsfeatures AVX und AVX2 erkennt und nutzt.
TensorFlow erkennt und nutzt die NVIDIA GeForce RTX 4070 Ti als GPU für das Training. Compute Capability 8.9 bedeutet, dass die GPU Tensor Cores und andere CUDA-optimierte Berechnungen unterstützt.
Epoch 1/5 bedeutet, dass die erste von fünf Trainingsepochen beginnt.
1875/1875 zeigt, dass das Modell alle 60.000 Trainingsbilder in 1875 Batches mit je 32 Bildern verarbeitet hat.
Dauer: 3 Sekunden
Loss (Fehlerrate auf Trainingsdaten): 0.2411
Accuracy (Genauigkeit auf Trainingsdaten): 93.05%
val_loss (Fehlerrate auf Validierungsdaten): 0.1258
val_accuracy (Genauigkeit auf Validierungsdaten): 96.02%
Schon nach der ersten Epoche hat das Modell eine sehr hohe Genauigkeit von 93% auf den Trainingsdaten und 96% auf den Testdaten. Das Modell verbessert sich mit jeder Epoche. Epoch 5: Die endgültige Genauigkeit ist 98.62% auf den Trainingsdaten und 97.93% auf den Testdaten.
Das Modell wird mit den Testdaten geprüft (10.000 Bilder). Genauigkeit: 97.93% auf den Testdaten. Das bedeutet, dass das Modell in 97.93% der Fälle die richtige Ziffer vorhersagt.
Ein einzelnes Testbild wurde dem Modell gegeben. Modell sagt: 7