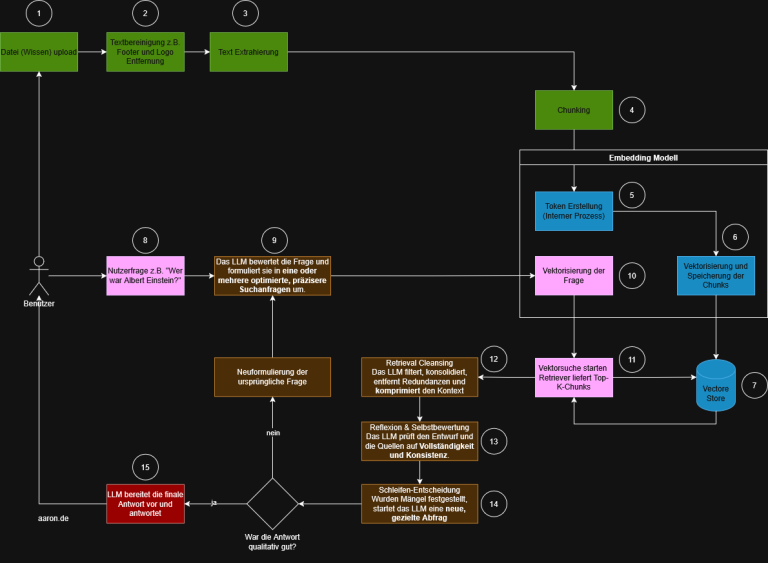
Dieser Blogbeitrag behandelt das Konzept von Embeddings und Vektordatenbanken. Dabei wird zunächst erklärt, was Embeddings sind und wie sie im Bereich des Natural Language Processing (NLP) genutzt werden. Anschließend folgt eine Erklärung der Vektoren in einem Raum mit drei Koordinaten und deren Erweiterung auf mehrdimensionale Vektoren. Schließlich wird ChromaDB vorgestellt, eine spezialisierte Vektordatenbank.
Was ist ein Embedding?
Ein Embedding ist eine Technik im Bereich des maschinellen Lernens und der Datenverarbeitung, die darauf abzielt, Objekte wie Wörter, Sätze oder Dokumente in einen kontinuierlichen Vektorraum zu transformieren. In diesem Vektorraum sind ähnliche Objekte durch ähnliche Vektoren repräsentiert, was bedeutet, dass sie nahe beieinander liegen. Embeddings werden häufig verwendet, um die semantische Bedeutung von Texten zu erfassen und zu analysieren.
Vektoren und der numerische Raum
Vektoren in drei Dimensionen
Ein Vektor ist eine Liste von Zahlen, die als Koordinaten in einem Raum betrachtet werden können. Im Alltag sind meistens drei Dimensionen bekannt: x, y und z. Diese Dimensionen können leicht visuell dargestellt werden:
- x: Horizontale Achse
- y: Vertikale Achse
- z: Tiefe
Ein Punkt in diesem dreidimensionalen Raum kann durch einen Vektor wie (x, y, z) beschrieben werden. Zum Beispiel könnte ein Punkt durch den Vektor (1, 2, 3) repräsentiert werden, was seine Position in diesem Raum angibt. Im dreidimensionalen Raum wäre das Wort „Lebewesen“ näher am Wort „Mensch“ positioniert als am Wort „Handball“.
Mehrdimensionale Vektoren
In der Mathematik und im maschinellen Lernen wird oft mit hochdimensionalen Räumen gearbeitet, die mehr als drei Dimensionen haben. Jede zusätzliche Dimension repräsentiert eine weitere unabhängige Eigenschaft oder ein Merkmal der Daten. Zum Beispiel:
- 4 Dimensionen: (x, y, z, w)
- 100 Dimensionen: (x1, x2, x3, …, x100)
Obwohl diese zusätzlichen Dimensionen nicht visuell vorstellbar sind, helfen sie dabei, komplexe Daten und deren Beziehungen genauer zu erfassen. Jede Dimension fügt eine neue Art von Information hinzu, die zur Gesamtdarstellung des Punktes (oder Wortes) beiträgt, z.B. Temperatur, Gewicht, Farbe etc. Bei mehrdimensionalen Vektoren müssen daher die x-, y- und z-Koordinaten nicht mehr für die räumliche Beschreibung verwendet werden. Diese drücken die Beziehung der einzelnen Wörter zueinander aus.
Diese Formulierung verdeutlicht, dass in hochdimensionalen Vektorräumen die Dimensionen verschiedene Merkmale oder Eigenschaften darstellen und nicht auf räumliche Beschreibungen beschränkt sind. Die Koordinaten zeigen vielmehr, wie die Wörter semantisch zueinander in Beziehung stehen.
Textkorpusanalyse und Embeddings
Um die Effizienz und Genauigkeit der Vektordatenbank von ChromaDB zu maximieren, ist eine sorgfältige Analyse des Textkorpus unerlässlich. Diese Analyse dient dazu, die Texte vorzubereiten und relevante Merkmale zu extrahieren, die anschließend in den Vektorraum eingebettet werden. Durch diesen Prozess können semantische Ähnlichkeiten zwischen den Texten präziser erfasst und genutzt werden, was die Leistungsfähigkeit von ChromaDB in der Praxis erheblich steigert. Dieser Prozess umfasst mehrere Schritte:
- Korpusvorbereitung: Sammlung und Bereinigung von Texten.
- Tokenisierung: Zerlegung des Textes in Wörter oder Sätze.
- Normalisierung: Vereinheitlichung der Wörter (z.B. Kleinschreibung, Stemming).
- Stoppwörter entfernen: Entfernen häufig vorkommender, aber wenig informativer Wörter.
- Feature-Extraktion: Methoden wie Bag of Words oder TF-IDF zur Gewichtung der Wörter.
- Modellierung und Analyse: Einsatz von Word Embeddings oder Themenmodellierung zur Erfassung semantischer Bedeutungen und Themen.
ChromaDB
ChromaDB ist eine spezialisierte Vektordatenbank, die darauf ausgelegt ist, Vektoren zu speichern, zu verwalten und abzufragen. Vektordatenbanken sind besonders nützlich für Anwendungen im Bereich NLP, wo die semantische Ähnlichkeit zwischen Texten erfasst werden muss. ChromaDB ermöglicht es, Dokumente hinzuzufügen, die in Vektoren umgewandelt werden, und ermöglicht es, Abfragen basierend auf diesen Vektoren durchzuführen.
ChromaDB Beispiel
Im Folgenden findet sich ein Beispiel, das zeigt, wie ChromaDB verwendet werden kann, um Dokumente hinzuzufügen und eine Abfrage durchzuführen. Hinweis: Innerhalb von Visual Studio Code gab es zahlreiche Bugs bei der Ausführung der Beispiele. PyCharm hat hingegen ohne Probleme funktioniert.
| Feld | Beschreibung | Wert |
|---|---|---|
| ids | Liste der IDs der zurückgegebenen Dokumente | [[‚id1‘, ‚id2‘]] |
| distances | Liste der Distanzen zwischen der Abfrage und den zurückgegebenen Dokumenten. Je kleiner der Wert, desto ähnlicher. | [[1.0404009819030762, 1.2430799007415771]] |
| metadatas | Liste der Metadaten der zurückgegebenen Dokumente | [[None, None]] |
| embeddings | Einbettungen der Dokumente. In diesem Fall nicht enthalten | None |
| documents | Liste der tatsächlichen Dokumenttexte, die als Ergebnis der Abfrage zurückgegeben wurden | [[‚This is a document about pineapple‘, ‚This is a document about oranges‘]] |
| uris | URIs der zurückgegebenen Dokumente. In diesem Fall nicht enthalten | None |
| data | Zusätzliche Daten, falls vorhanden. In diesem Fall nicht enthalten | None |
| included | Liste der Felder, die in den Ergebnissen enthalten sind | [‚metadatas‘, ‚documents‘, ‚distances‘] |
Distanzmessung zwecks Ermittlung der Ähnlichkeit zwischen Vektoren
Die Distanzwerte in der Ausgabe repräsentieren die Ähnlichkeit zwischen der Abfrage und den zurückgegebenen Dokumenten. ChromaDB verwendet Einbettungsmodelle, um Dokumente in einen mehrdimensionalen Vektorraum zu projizieren, wo die Ähnlichkeit durch die Distanzen zwischen diesen Vektoren gemessen wird.
Die Distanz zwischen Vektoren im mehrdimensionalen Raum wird üblicherweise durch verschiedene metrische Methoden berechnet. Eine der häufigsten Methoden ist die Berechnung der euklidischen Distanz. Andere Methoden umfassen die kosinussimilarität, Manhattan-Distanz und weitere.