In diesem Beitrag erkläre ich dir, wie du Whisper, ein KI-basiertes Tool von OpenAI, zur automatischen Transkription von Videos verwenden kannst. Whisper ist in der Lage, gesprochene Sprache in verschiedenen Sprachen – einschließlich Deutsch – präzise in Text umzuwandeln. Damit eignet es sich hervorragend, um z. B. Interviews, Vorträge oder persönliche Videos zu transkribieren.
Python 3.10 installieren
Whisper setzt die Programmiersprache Python voraus und benötigt eine Version zwischen 3.7 und 3.10. In dieser Anleitung verwenden wir Python 3.10, um Kompatibilitätsprobleme zu vermeiden.
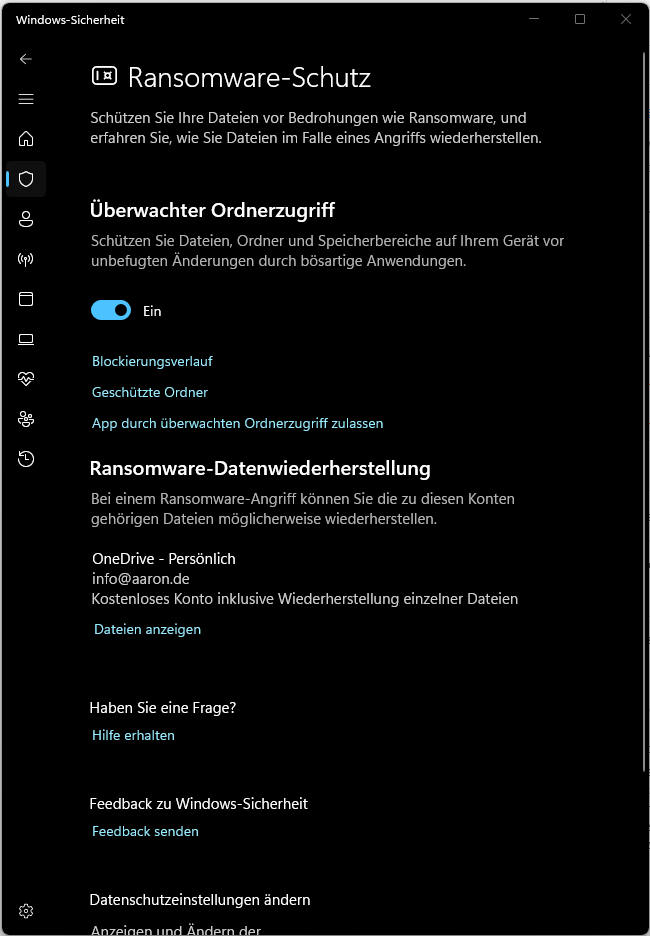
Falls Windows-Sicherheit die Ausführung von python.exe blockiert, kannst du Python manuell als zulässige App hinzufügen:
Eine virtuelle Umgebung (whisper-env) einrichten
Whisper benötigt verschiedene Bibliotheken (wie torch für maschinelles Lernen, ffmpeg zur Audioverarbeitung und einige weitere Python-Pakete). Wenn du diese Pakete direkt in deinem globalen Python-Umfeld installieren würdest, könnten sie mit anderen Projekten, die möglicherweise andere Versionen dieser Bibliotheken benötigen, in Konflikt geraten. Eine virtuelle Umgebung hält alle benötigten Abhängigkeiten getrennt, sodass sie nur für Whisper gelten.
Erstelle nun die virtuelle Umgebung mit dem Namen whisper-env im Projektordner, wodurch ein neuer Ordner namens whisper-env im Projektverzeichnis erstellt wird, der die isolierte Python-Umgebung enthält, in der alle Pakete für Whisper installiert werden.
Um die virtuelle Umgebung zu nutzen, musst du sie aktivieren. Nach der Aktivierung zeigt der Prompt (whisper-env), dass die virtuelle Umgebung aktiv ist. Alle folgenden Python-Befehle (z. B. pip install) gelten nur für diese Umgebung, solange sie aktiv ist.
Jetzt kannst du Whisper und alle notwendigen Abhängigkeiten in die virtuelle Umgebung installieren, ohne dass sie dein globales System beeinflussen.
Falls bei der Installation Fehler auftreten sollten, dass fehlen eventuell weitere Abhängigkeiten bzw. Tools. Diese kannst du wie folgt installieren:
Falls eine Fehlermeldung zur Skriptausführung erscheint, passe die PowerShell-Sicherheitsrichtlinie an:
ffmpeg installieren und zum Systempfad hinzufügenx
Whisper benötigt ffmpeg, um Audio aus Videodateien zu extrahieren. Hier sind die Schritte zur Installation von ffmpeg. Die benötigte Datei „ffmpeg-release-essentials.zip“ kannst du auf der offiziellen Webseite downloaden. Anschließend muss der bin Ordner (C:\tools\ffmpeg-7.1-essentials_build\bin) innerhalb der Umgebungsvariable als Pfad hinzugefügt werden. Die ffmpeg Version kannst du dir anschließnd wie folgt anzeigen lassen:
Whisper zur Transkription verwenden
In dem zuvor erstelltem Projektordner „whisper“ habe ich die folgenden Ordner erstellt:
- quelle: Dieser Ordner enthält die Videodateien, die transkribiert werden sollen.
- transkript: Hier wird das fertige Transkript gespeichert.
- whisper-env: Dies ist der Ordner mit der virtuellen Umgebung, in der Whisper installiert wurde.
Mit dem folgenden Kommando kannst du die Datei Video1.mkv aus dem Ordner quelle transkribieren und das Transkript ohne Zeitstempel im Ordner transkript speichern.
"C:\Users\Benutzername\Videos\whisper\quelle\Video1.mkv": Der Pfad zur Videodatei, die transkribiert werden soll.--language German: Gibt an, dass das Video auf Deutsch ist, damit Whisper die richtige Sprache verwendet.--output_format txt: Speichert das Transkript als reine Textdatei (.txt) ohne Zeitstempel.--output_dir "C:\Users\Benutzername\Videos\whisper\transkript": Gibt an, dass die Textdatei im Ordner transkript gespeichert wird.
Virtuelle Umgebung beenden
Nach Abschluss der Transkription kannst du die virtuelle Umgebung deaktivieren. Gib dazu einfach den folgenden Befehl ein:
Automatisierte Transkription mehrerer Videos
Wenn du mehrere Videodateien im selben Ordner hast und diese automatisch transkribieren möchtest, ohne dass bereits verarbeitete Dateien erneut bearbeitet werden, kannst du das folgende Python-Skript verwenden. Das Skript durchsucht einen festgelegten Ordner nach neuen oder geänderten Videodateien, transkribiert diese und speichert die Ergebnisse als Textdateien in einem Zielordner. Die Transkripte haben denselben Namen wie die Videodateien und enthalten nur den reinen Text ohne Zeitstempel. Eine zusätzliche Verlaufsdatei stellt sicher, dass bereits verarbeitete Videos beim nächsten Durchlauf übersprungen werden. So kannst du das Skript regelmäßig ausführen und es verarbeitet automatisch nur die relevanten Dateien.
Führe das Skript mit folgendem Befehl aus:
Whisper mit dem Large-Modell und GPU-Unterstützung verwenden
In diesem Abschnitt erfährst du, wie du das Large-Modell von Whisper optimal auf deiner NVIDIA-GPU nutzt, um die beste Transkriptionsgenauigkeit zu erzielen und gleichzeitig die Geschwindigkeit zu maximieren. Da das Large-Modell rechenintensiv ist, bietet sich die Verwendung einer GPU an, um die Verarbeitung deutlich zu beschleunigen.
Bevor wir ins Detail gehen, sind einige grundlegende Begriffe zu klären.
Was ist PyTorch (oder torch)?
PyTorch ist eine Open-Source-Bibliothek für maschinelles Lernen, die hauptsächlich von Facebook AI entwickelt wurde. Sie bietet eine Vielzahl an Werkzeugen und Algorithmen für das Deep Learning und wird in der Programmiersprache Python verwendet.
In deinem Fall nutzt Whisper PyTorch im Hintergrund als „Backend“, um die komplexen Berechnungen für die Transkription von Audio zu Text auszuführen. Wenn du Whisper installierst und nutzt, wird PyTorch automatisch im Hintergrund geladen – du musst dich also nicht direkt um PyTorch kümmern, sondern nur sicherstellen, dass es richtig installiert ist.
Was ist torch?
torch ist der Paketname für PyTorch in Python. Das heißt, wenn du im Python-Code import torch siehst, bezieht sich dies auf die PyTorch-Bibliothek. Der Name „torch“ wird verwendet, da PyTorch unter diesem Paketnamen in Python importiert wird.
Was ist CUDA?
CUDA (Compute Unified Device Architecture) ist eine Technologie und Programmierschnittstelle, die von NVIDIA entwickelt wurde. Sie ermöglicht es Programmen wie PyTorch, die Rechenleistung einer NVIDIA-GPU zu nutzen. GPUs sind besonders leistungsfähig bei parallelen Berechnungen, da sie viele Rechenoperationen gleichzeitig durchführen können. Wenn ein Modell wie Whisper große Mengen an Daten verarbeiten muss, kann CUDA die Rechenzeit erheblich verkürzen, indem es die GPU für die Berechnungen nutzt.
Für PyTorch bedeutet dies, dass es CUDA verwenden kann, um Berechnungen auf einer NVIDIA-GPU statt auf der CPU laufen zu lassen, sofern eine solche GPU verfügbar ist und PyTorch mit CUDA-Unterstützung installiert ist.
Installation von PyTorch mit CUDA-Unterstützung
Damit deine GPU für Whisper genutzt werden kann, muss PyTorch mit CUDA-Unterstützung installiert sein. Ohne CUDA würde PyTorch nur die CPU verwenden, was langsamer ist. Führe den folgenden Befehl in der Kommandozeile aus, um PyTorch mit der passenden CUDA-Version zu installieren:
Um sicherzustellen, dass PyTorch mit CUDA-Unterstützung installiert ist und die GPU erkannt wird, kannst du das folgende Python-Skript ausführen. Es überprüft, ob CUDA verfügbar ist und zeigt die GPU-Informationen an.
In meinem Fall war CUDA nicht vorinstalliert. Die aktuelle Version könnt ihr auf der NVIDIA Webseite downloaden.
Anschließend kannst du das Skript nochmal ausführen. Im Idealfall wird eine ähnliche Meldung angezeigt:

Das Skript wurde um die Nutzung von „CUDA“ und „large model“ erweitert.
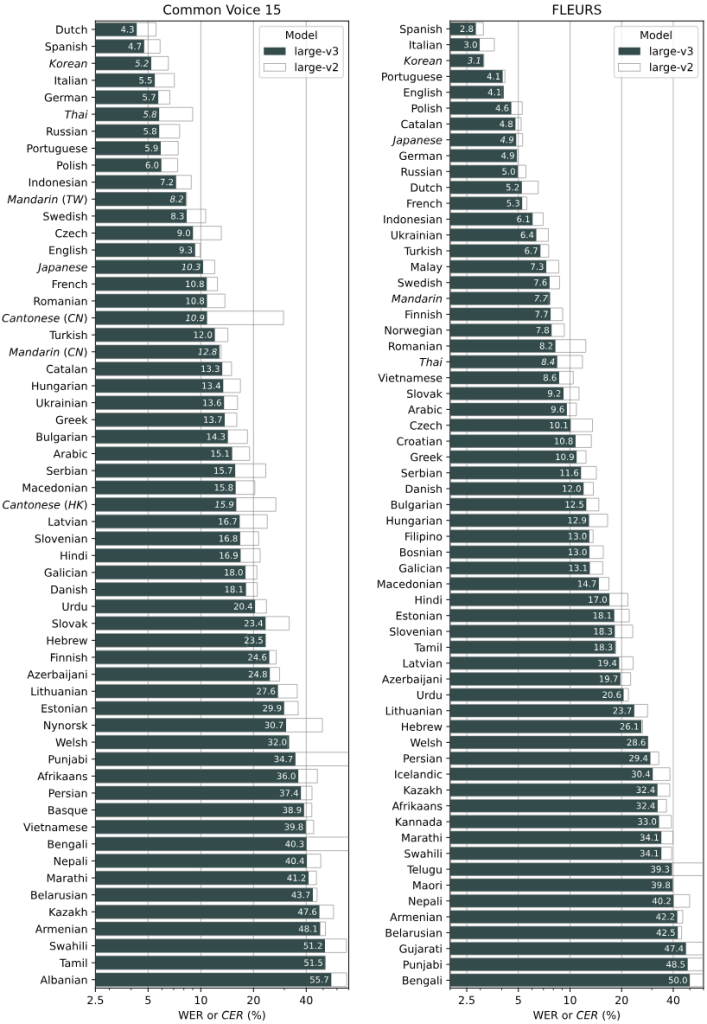
Modelle und ihre Genauigkeit in verschiedenen Sprachen
Die folgende Grafik von OpenAI zeigt die Genauigkeit der verschiedenen Whisper-Modelle in einer Vielzahl von Sprachen. Diese Leistungsmessung basiert auf WER (Word Error Rate) und CER (Character Error Rate), die auf den Common Voice 15 und Fleurs-Datensätzen evaluiert wurden. Jedes Modell von Whisper wurde für eine Reihe von Sprachen getestet, um seine Fähigkeit zur präzisen Transkription und seine Leistungsunterschiede je nach Sprache darzustellen. Zum Beispiel zeigt ein WER-Wert von 5,7 für Deutsch, dass das Modell pro 100 transkribierte Wörter etwa 5,7 Fehler macht, was eine relativ hohe Genauigkeit darstellt. Die Grafik gibt dir so eine gute Vorstellung davon, welches Modell in welcher Sprache besonders leistungsfähig ist.