try:
# TensorFlow ist eine Open-Source-Bibliothek für maschinelles Lernen und neuronale Netzwerke.
# Sie bietet die grundlegenden Werkzeuge, um Modelle zu erstellen, zu trainieren und zu evaluieren.
import tensorflow as tf
# Keras ist eine High-Level-API (Programmierschnittstelle), die ursprünglich als eigenständiges Framework für maschinelles Lernen entwickelt wurde, jedoch inzwischen vollständig in TensorFlow integriert ist.
# Keras hilft, Netzwerke auf einfache und intuitive Weise zu definieren.
# `Sequential` ist eine einfache API in Keras, um neuronale Netzwerke zu definieren.
# Damit können Schichten (Layers) nacheinander in einer linearen Reihenfolge (Sequenziell) hinzugefügt werden.
from tensorflow.keras import Sequential
# Dense, Flatten, Input sind verschiedene Schichttypen:
# - Dense: Vollständig verbundene Schicht. Jedes Neuron ist mit allen Neuronen der vorherigen Schicht verbunden.
# - Flatten: Diese Schicht reduziert die Dimension der Daten. Bei Bildern bedeutet dies, dass ein zweidimensionales Bild (z. B. 28x28 Pixel) in eine eindimensionale Liste von Zahlen umgewandelt wird.
# Diese Umwandlung ist notwendig, damit die Dense-Schichten die Daten verarbeiten können.
# - Input: Definiert die Form der Eingabedaten, z. B. 28x28 Pixel für Bilder.
from tensorflow.keras.layers import Dense, Flatten, Input
# Adam ist ein Algorithmus zur Optimierung der Gewichte im Netzwerk, um Fehler zu minimieren.
from tensorflow.keras.optimizers import Adam
except ModuleNotFoundError as e:
print("TensorFlow ist nicht installiert. Installieren Sie es mit: pip install tensorflow")
raise SystemExit
# 1. Datensatz laden
# Der MNIST-Datensatz enthält handgeschriebene Ziffern von 0 bis 9. Jedes Bild ist 28x28 Pixel groß und in Graustufen (0-255).
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# 2. Daten vorverarbeiten
# Die Pixelwerte bzw. Graustufen der Bilder liegen ursprünglich im Bereich von 0 bis 255. 0 bedeutet schwarz und 255 bedeutet weiß.
# Um die Daten für das neuronale Netzwerk besser nutzbar zu machen, werden sie auf den Bereich 0 bis 1 normalisiert. Dies geschieht durch Division jedes Pixelwerts durch 255.0.
# Vorteile der Normalisierung:
# - Verbesserte Stabilität während des Trainings (verhindert numerische Probleme).
# - Schnellere Konvergenz (das Modell lernt schneller, da kleinere Werte stabiler verarbeitet werden).
x_train = x_train / 255.0
x_test = x_test / 255.0
# 3. Labels überprüfen
# Labels geben an, welche Ziffer jedes Bild darstellt (z. B. 0, 1, ..., 9). Die ersten 10 Labels aus den Trainingsdaten werden angezeigt.
# Dies dient dazu, die Labels zu verifizieren und sicherzustellen, dass die Daten korrekt geladen wurden.
print("Beispiel-Label aus den Trainingsdaten:", y_train[:10])
# 4. Modell definieren
# Hier wird ein neuronales Netzwerk mit der Sequential-API erstellt.
# Jede Schicht verarbeitet die Daten und reicht sie an die nächste weiter.
# Verarbeitet bedeutet:
# - Jede Schicht wendet eine mathematische Funktion auf die Eingaben an, z. B. Multiplikation mit Gewichten und Addition eines Bias.
# - Aktivierungsfunktionen wie "relu" führen Nichtlinearitäten ein, um komplexe Muster zu lernen.
#
# Die Schichten im Netzwerk:
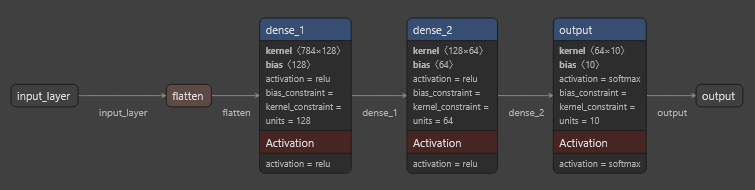
# - Input: Legt fest, dass jedes Bild 28x28 Pixel groß ist d.h. es werden 28*28=784 input Neuronen benötigt.
# - Flatten: Wandelt das Bild (2D) in eine flache Liste (784 Werte), damit es von Dense-Schichten verarbeitet werden kann.
# Das Netzwerk hat 3 Dense-Layers (Architektur), wobei jede Schicht ihre eigene spezifische Rolle im Lernprozess übernimmt.
# Layer 1: Dense(128, activation='relu')
# - Diese Schicht hat 128 Neuronen. Jedes dieser Neuronen ist mit allen Neuronen der vorherigen Schicht (der Eingabedaten oder der Flatten-Schicht) verbunden.
# - Es extrahiert Muster oder Merkmale aus den Daten und verwendet die ReLU-Aktivierungsfunktion, um nur positive Werte weiterzugeben.
# Layer 2: Dense(64, activation='relu')
# - Diese Schicht hat 64 Neuronen, die auf den Ausgaben von Layer 1 arbeiten. Sie verdichten und filtern die Informationen aus Layer 1.
# - Auch hier wird die ReLU-Aktivierung verwendet, um komplexe Beziehungen in den Daten zu lernen.
# Layer 3: Dense(10, activation='softmax')
# - Diese Schicht hat 10 Neuronen, die jeweils einer Klasse (den Ziffern 0 bis 9) entsprechen
# - Sie verwendet die Softmax-Aktivierungsfunktion, die sicherstellt, dass die Ausgaben als Wahrscheinlichkeiten interpretiert werden können. Die Summe der Ausgaben beträgt immer 1.
model = Sequential([
Input(shape=(28, 28)),
Flatten(),
# Layer 1 (128 Neuronen): Lernt viele Merkmale aus den Rohdaten.
Dense(128, activation='relu'),
# Layer 2 (64 Neuronen): Verdichtet die Merkmale aus Layer 1.
Dense(64, activation='relu'),
# Layer 3 (10 Neuronen): Gibt Wahrscheinlichkeiten für jede der 10 Klassen (Ziffern 0 bis 9) zurück.
Dense(10, activation='softmax')
])
# 5. Modell kompilieren
# - optimizer=Adam: Optimierungsalgorithmus, der die Gewichte im Netzwerk anpasst, um den Fehler zu minimieren.
# - loss=sparse_categorical_crossentropy: Verlustfunktion für Klassifikationsprobleme.
# Ein Klassifikationsproblem liegt vor, wenn das Ziel darin besteht, Daten einer von mehreren Kategorien (hier Ziffern 0-9) zuzuordnen.
# Der "Verlust" ist eine Zahl, die angibt, wie weit die Vorhersage des Modells von der tatsächlichen Antwort entfernt ist.
# - metrics=['accuracy']: Metriken sind Kennzahlen, die die Leistung des Modells bewerten. "accuracy" misst den Prozentsatz der korrekt vorhergesagten Ziffern.
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='sparse_categorical_crossentropy',
# Accuracy misst die Genauigkeit des Modells, also den Prozentsatz der richtig klassifizierten Datenpunkte. Die Range reicht von 0 bis 1.
# 0.0 bedeutet: Keine Vorhersage war korrekt. 1.0 bedeutet: Alle Vorhersagen waren korrekt.
# Bei der Ausgabe bedeutet z.B. 0.8790, dass 87,90 % der Daten korrekt klassifiziert wurden.
metrics=['accuracy']
)
# 6. Modell trainieren
# - epochs=5: Das Modell durchläuft die gesamten Trainingsdaten 5-mal. Jede Wiederholung wird als "Epoche" bezeichnet. Mehr Epochen geben dem Modell mehr Chancen, Muster in den Daten zu lernen.
# - batch_size=32: Die Daten werden in Gruppen (Batches) von 32 Bildern verarbeitet. Dies reduziert den Speicherbedarf und beschleunigt die Berechnungen, da nicht alle Daten gleichzeitig geladen werden.
# - validation_data: Testdaten werden während des Trainings verwendet, um die Leistung zu bewerten, ohne die Gewichte anzupassen.
history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_data=(x_test, y_test))
# 7. Modell evaluieren
# - model.evaluate: Misst den Verlust (Fehler) und die Genauigkeit auf den Testdaten.
# Verlust gibt an, wie gut oder schlecht das Modell ist, und Genauigkeit zeigt den Prozentsatz korrekt klassifizierter Ziffern.
# Loss misst den Fehler des Modells während des Trainings. Es gibt an, wie weit die Vorhersagen des Modells von den tatsächlichen Labels entfernt sind.
# Ob ein Loss-Wert „gut“ oder „schlecht“ ist, hängt vom Problem ab. Für MNIST ist ein Loss von unter 0.1 in der Regel gut.
test_loss, test_accuracy = model.evaluate(x_test, y_test, verbose=2)
print(f"\nTest Accuracy: {test_accuracy * 100:.2f}%")
# 8. Modell testen
# Vorhersage für ein einzelnes Bild. Gibt Wahrscheinlichkeiten für jede Ziffer (0-9) zurück.
# Jede "Klasse" entspricht hier einer Ziffer (z. B. Klasse 0 für Ziffer 0, Klasse 1 für Ziffer 1 usw.).
import numpy as np
sample_image = x_test[0].reshape(1, 28, 28)
prediction = model.predict(sample_image)
predicted_label = np.argmax(prediction)
print(f"\nVorhersage: {predicted_label}")
print(f"Tatsächliches Label: {y_test[0]}")
# Zusätzliche Tests
# Testet 10 Bilder aus den Testdaten.
def test_multiple_images(model, images, labels, num_tests=5):
for i in range(min(num_tests, len(images))):
img = images[i].reshape(1, 28, 28)
pred = np.argmax(model.predict(img))
print(f"Bild {i 1}: Vorhergesagt: {pred}, Tatsächlich: {labels[i]}")
test_multiple_images(model, x_test, y_test, num_tests=10)
# Eine Verbesserung des Modells zeigt sich durch:
# - Sinkenden Loss: Sowohl loss als auch val_loss sollten kleiner werden.
# - Steigende Accuracy: Sowohl accuracy als auch val_accuracy sollten größer werden.
mnist.py