Audio2Face ist ein KI-gestütztes Tool innerhalb von NVIDIA Omniverse, das speziell dafür entwickelt wurde, realistische Gesichtsanimationen allein auf Basis von Audio zu erzeugen. Es gehört zur Omniverse-Plattform, die eine Echtzeit-Kollaborations- und Simulationsumgebung für 3D-Workflows bietet. Audio2Face nutzt ein neuronales Netzwerk, um gesprochene Sprache automatisch in lebendige Mimik und Gesichtsbewegungen umzuwandeln. Typischerweise verwendet man Audio2Face, um Charaktere in Spielen, Filmen oder digitalen Avataren sprechen zu lassen, ohne aufwendige Keyframe-Animationen. Die erzeugten Bewegungen können entweder direkt verwendet oder auf eigene 3D-Charaktere übertragen werden, was besonders für virtuelle Produktionen, digitale Zwillinge oder interaktive Anwendungen interessant ist.
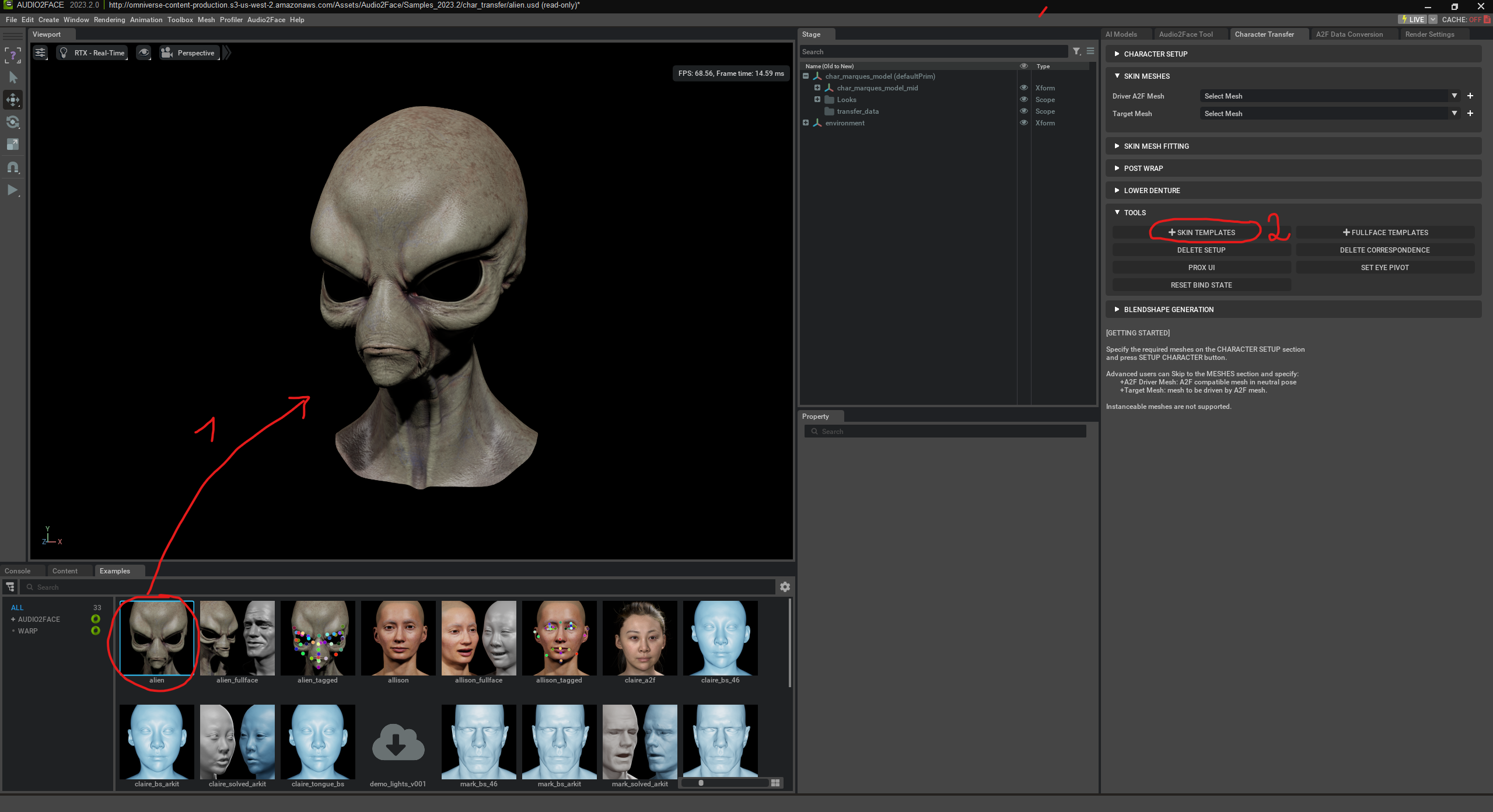
Als Erstes können wir eines der existierenden Gesichter auswählen. Anschließen wählen wir “Skin Templates” aus.

Skin Templates in NVIDIA Audio2Face sind vordefinierte Vorlagen, die das Gesicht in verschiedene Zonen unterteilen – etwa Mund, Kiefer, Augen, Nase oder Stirn. Diese Zonen helfen der KI dabei zu verstehen, wie sich bestimmte Bereiche des Gesichts bei Sprache und Emotionen bewegen sollen. Ein Skin Template beschreibt also, welche Vertices (Punkte im 3D-Mesh) zu welchen Gesichtsregionen gehören und wie stark sie sich bei bestimmten Lauten oder Gesichtsausdrücken mitverformen. Wenn man einen eigenen Charakter in Audio2Face verwenden möchte, wird mithilfe des Skin Templates definiert, wie die Bewegungen vom KI-gesteuerten „Driver Mesh“ auf das Zielmodell übertragen werden.

Skin Mesh Fitting wird verwendet, um deinen eigenen Charakter (Target Mesh) automatisch an das KI-gesteuerte Driver Mesh zu binden (fitting).

„Begin Mesh Fitting“ startet den automatischen Anpassungsprozess deines Charakter-Meshes an das Audio2Face-System. Dabei wird dein Mesh analysiert, mit dem KI-gesteuerten Driver Mesh verglichen und mithilfe eines Skin Templates passend angepasst. Ziel ist, dass dein Charakter die Mimik und Sprache automatisch übernehmen kann – ohne manuelles Rigging (also ohne Knochen/Skelette zu setzen) oder Blendshapes. Blendshapes sind vorbereitete Gesichtsformen wie „Mund offen“, „Lächeln“ oder „Augenbrauen hoch“. Die KI kann diese mischen, um Gesichtsausdrücke zu erzeugen – z. B. 0 % Lächeln = neutral, 100 % = volles Lächeln.

„Begin Post Wrap“ ist der letzte Schritt nach dem Mesh Fitting in Audio2Face. Er sorgt dafür, dass dein Charakter-Mesh korrekt an das animierte Driver Mesh „angeheftet“ wird. Dabei wird dein Mesh wie eine Hülle („Wrap“) auf das Driver Mesh gelegt, sodass alle Gesichtspartien bei Sprache und Mimik realistisch mitbewegt werden. Dieser Schritt verfeinert die Übertragung der Bewegungen und verbessert die Genauigkeit und Qualität der Animation. Ziel ist, dass dein Charakter natürlich spricht und sich wie das Original bewegt – ohne manuelles Eingreifen.

Hier wird eine sogenannte „A2F Pipeline“ erstellt. Diese Pipeline ist notwendig, um ein 3D-Gesicht mit der Audio-gesteuerten KI-Animation zu verbinden. Im gezeigten Fenster wählt der Benutzer den Audioplayer-Typ und ein vortrainiertes KI-Modell („Mark“) aus, das für die Gesichtsanalyse verwendet wird. Zusätzlich wird die Option aktiviert, automatisch alle Gesichtskomponenten (wie Augen, Zunge, Unterkiefer) zu erkennen und zu verknüpfen. Die A2F Pipeline ist also der technische Rahmen, der das Zusammenspiel aus Audio, KI und 3D-Mesh steuert.

Als Letztes müssen wir nur noch auf “play” drücken, um die Animation zu sehen.

Das Alien lässt sich auch in Echtzeit durch gesprochene Sprache animieren.
