Im Rahmen dieses Tests wird das Open-Source-Framework unstructured eingesetzt, um den Extraktionsprozess von Text aus strukturierten Dokumenten zu evaluieren. Ziel ist es, zu prüfen, inwieweit sich unstructured für den praktischen Einsatz in KI-basierten Informationssystemen eignet – insbesondere mit Blick auf die Textextraktion, semantische Aufbereitung (Chunking/Tokenisierung) und anschließende Embedding-Erzeugung für Vektor-basierte Retrieval-Systeme.
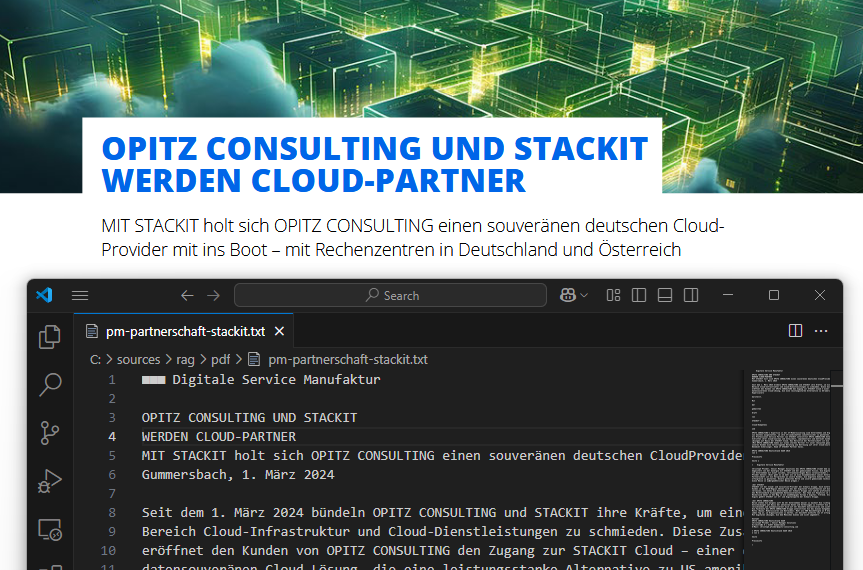
Hier sieht man ein Beispiel einer PDF-Datei, die für die Analyse mit unstructured verwendet wurde.
Zur Ausführung der unstructured-Bibliothek wird das offizielle Docker-Image verwendet. Dieses enthält alle erforderlichen Abhängigkeiten (z. B. Tesseract, Poppler, Python-Bibliotheken) und ermöglicht eine sofortige Nutzung ohne lokale Python-Installation.
Im Rahmen eines ersten Tests wurde das Tool unstructured interaktiv im Docker-Container ausgeführt, um die Qualität der Texterkennung und strukturellen Analyse einer Beispiel-PDF zu evaluieren. Ziel war es, zu prüfen, wie zuverlässig das Framework Inhalte wie Überschriften, Absätze und Fließtexte erkennt und diesen semantischen Typen wie Title oder NarrativeText zuweist. Die Analyse zeigte, dass unstructured die logische Struktur des Dokuments weitgehend korrekt rekonstruieren konnte. Der Test bildet die Grundlage für weiterführende Schritte wie das semantische Chunking und die Vorbereitung der Daten für Embedding-gestützte Retrieval-Systeme.
C:\sources\rag>docker exec -it unstructured python3 Python 3.11.11 (tags/v3.11.11-0-gd03b868-dirty:d03b868, Mar 18 2025, 22:15:31) [GCC 14.2.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> from unstructured.partition.pdf import partition_pdf >>> elements = partition_pdf(filename="/data/pm-partnerschaft-stackit.pdf") >>> for i, el in enumerate(elements): ... print(f"[{i}] {type(el).__name__}: {el.text}\n") ... [0] Header: ■■■ Digitale Service Manufaktur
[1] Title: OPITZ CONSULTING UND STACKIT WERDEN CLOUD-PARTNER
[2] NarrativeText: MIT STACKIT holt sich OPITZ CONSULTING einen souveränen deutschen Cloud- Provider mit ins Boot – mit Rechenzentren in Deutschland und Österreich
[3] Title: Gummersbach, 1. März 2024
[4] NarrativeText: Seit dem ....
Im nächsten Schritt habe ich die Textextraktion über ein Python-Skript automatisiert. Der Code erkennt zunächst automatisch die Sprache des Dokuments via „langdetect“, wendet dann die passende OCR-Konfiguration an und führt die strukturierte Analyse über unstructured durch – inklusive Klassifikation und Ausgabe der erkannten Inhalte.
pip install langdetect
import subprocess import os import time from langdetect import detect # Sprachkennung
# === Container starten falls nötig === if not container_is_running(container_name): print("🚀 Starte Docker-Container...") subprocess.run([ "docker", "run", "-dt", "--name", container_name, "-v", f"{host_pdf_dir}:/data", "downloads.unstructured.io/unstructured-io/unstructured:latest" ]) time.sleep(3) # kurz warten, damit Container vollständig startet else: print("✅ Container läuft bereits.")
# === Schritt 1: Sprache erkennen über kurzen PDF-Textausschnitt print("🌍 Erkenne Sprache im PDF...")
raw_text_code = f""" from unstructured.partition.pdf import partition_pdf elements = partition_pdf(filename="{container_pdf_path}", strategy="fast") print(" ".join([el.text for el in elements if hasattr(el, 'text')][:3])) """
# === Schritt 2: Verarbeite PDF mit erkannter Sprache (ohne deprecated Param) python_code = f""" from unstructured.partition.pdf import partition_pdf elements = partition_pdf( filename="{container_pdf_path}", strategy="hi_res", extract_image_block_output=True, infer_table_structure=True, languages=["{ocr_lang}"] ) with open("{container_output_path}", "w", encoding="utf-8") as f: for el in elements: f.write("TYPE::" type(el).__name__ "\\n") f.write("TEXT::" el.text.replace("\\n", " ").replace("\\r", "") "\\n") f.write("-----\\n") """
# === Ergebnis lesen (inkl. Umlaute korrekt) print("📄 Lese Ergebnis aus Datei...") with open(host_output_path, "r", encoding="utf-8") as f: result = f.read()
print("✅ Verarbeiteter Textauszug:") print(result[:1000]) # Vorschau der ersten 1000 Zeichen
unstructured_test.py
Am extrahierten Beispiel lässt sich gut erkennen, wie unstructured verschiedene Textbausteine differenziert klassifiziert. Die semantische Typisierung ist in vielen Fällen nachvollziehbar: Überschriften wie „OPITZ CONSULTING UND STACKIT WERDEN CLOUD-PARTNER“ werden korrekt als Title erkannt, Fließtextabsätze als NarrativeText, und Layout-Elemente wie Seitennummerierungen oder Fußzeilen als allgemeiner Text.
Insgesamt zeigt die Analyse, dass unstructured für die Strukturierung von Dokumenten mit einfacher Layoutstruktur bereits eine solide Grundlage bietet – allerdings nur bei Verwendung der Strategie hi_res, da die Ergebnisse mit der Standardverarbeitung deutlich ungenauer und fragmentierter ausfallen.
TYPE::Image TEXT:: ----- TYPE::NarrativeText TEXT::■■■ Digitale Service Manufaktur ----- TYPE::Image TEXT:: OPITZ CONSULTING UND STACKIT ----- TYPE::Title TEXT::OPITZ CONSULTING UND STACKIT WERDEN CLOUD-PARTNER ----- TYPE::NarrativeText TEXT::MIT STACKIT holt sich OPITZ CONSULTING einen souveränen deutschen Cloud- Provider mit ins Boot – mit Rechenzentren in Deutschland und Österreich ----- TYPE::Title TEXT::J‘ STACSIT ----- TYPE::NarrativeText TEXT::Gummersbach, 1. März 2024 ----- TYPE::NarrativeText TEXT::Seit dem 1. März 2024 bündeln OPITZ CONSULTING und STACKIT ihre Kräfte, um eine Allianz im Bereich Cloud-Infrastruktur und Cloud-Dienstleistungen zu schmieden. Diese Zusammenarbeit eröffnet den Kunden von OPITZ CONSULTING den Zugang zur STACKIT Cloud – einer deutschen, datensouveränen Cloud-Lösung, die eine leistungsstarke Alternative zu US-amerikanischen Hyperscalern darstellt. Mit der geballten Kraft von STACKIT's Cloud-Kompetenz und OPITZ CONSULTING's Expertise in der IT-Modernisierung sind Unternehmen und Organisationen nun bestens ausgestattet, um ihre IT-Landschaften zukunftssicher zu gestalten. ----- TYPE::NarrativeText TEXT::Als Professional Service Partner von STACKIT unterstützt OPITZ CONSULTING Unternehmen in allen Schritten ihrer Cloud-Journey und entwickelt, implementiert und betreibt kundenindividuelle Lösungen auf Basis der STACKIT Cloud. Das Herzstück der Partnerschaft ist die Vision, die individu- ellen Stärken beider Unternehmen zu bündeln, um Unternehmen eine nahtlose, effiziente und si- chere Cloud-Transformation zu ermöglichen. ----- TYPE::NarrativeText TEXT::„Mit OPITZ CONSULTING haben wir einen starken Partner für unser Ökosystem gewonnen, der unseren Kunden eine hervorragende Beratung und Betreuung auf ihrer Cloud-Journey bietet“, sagt Benedikt Scherzinger, Head of STACKIT Partner Sales. ----- TYPE::Text TEXT::OPITZ CONSULTING Deutschland GmbH 2016 Seite 1 ----- TYPE::Text TEXT::von 2 ----- TYPE::Text TEXT::Presseinfo ----- TYPE::Image TEXT::— —_ OPITZ CONSULTING ----- TYPE::Header TEXT::■■■ Digitale Service Manufaktur ----- TYPE::NarrativeText TEXT::Christoph Pfinder, Senior Manager Solutions bei OPITZ CONSULTING stimmt dem zu: „Wir sind begeistert von der Synergie mit STACKIT und der gemeinsamen Vision, die digitale Transformation von Unternehmen mit einer soliden, vertrauenswürdigen Basis voranzutreiben.“ ----- TYPE::NarrativeText TEXT::Pfinder betont: „Hier geht es um mehr als um eine Zusammenarbeit zweier Unternehmen – diese Partnerschaft ist ein Versprechen an unsere Kunden, die digitale Zukunft sicher, souverän und erfolgreich zu gestalten. Unsere geteilten Werte und unsere gemeinsame technische Vision werden diese Reise in außergewöhnlicher Weise prägen.“ ----- TYPE::Title TEXT::Über STACKIT
....
output.txt
PDF-Dokumente enthalten oft mehr, als auf den ersten Blick sichtbar ist. Insbesondere bei eingescannten oder automatisch verarbeiteten PDFs können sogenannte „Hidden Text Layers“ eingebettet sein – also unsichtbare Texte, die über dem sichtbaren Bild des Dokuments liegen. Diese entstehen zum Beispiel durch OCR-Software wie Adobe Acrobat, die erkannte Zeichen als maschinenlesbaren Text speichert, ohne sie für den Benutzer sichtbar zu machen.
Solche versteckten Texte können von PDF-Analysewerkzeugen wie unstructured gelesen und verarbeitet werden – selbst wenn sie in gängigen PDF-Viewern nicht erscheinen. Um zu prüfen, ob ein PDF solche eingebetteten Texte enthält, eignet sich das Tool pdftotext aus dem Paket poppler-utils. Mit einem einfachen Befehl lässt sich damit der gesamte maschinenlesbare Text extrahieren und in einer .txt-Datei sichtbar machen.
Das ist besonders hilfreich, wenn unerwartete oder scheinbar „falsche“ Inhalte im Analyse-Output auftauchen – denn sie stammen nicht immer aus OCR-Fehlern, sondern manchmal aus unsichtbaren Textinformationen im Originaldokument.
An dieser Stelle wollte ich ursprünglich mit dem Chunking fortfahren, musste im Rahmen der Analyse jedoch feststellen, dass die Chunking-Funktionalität von Unstructured sehr rudimentär ist. Für eine semantisch saubere Segmentierung ziehe ich daher eine Bibliothek wie NLTK vor und werde die Arbeit mit Unstructured an dieser Stelle zunächst nicht weiterverfolgen.