RAGFlow ist ein Framework zur strukturierten Umsetzung von Retrieval Augmented Generation (RAG)-Anwendungen. Es bietet eine modulare Architektur, in der einzelne Verarbeitungsschritte wie Dokumentenimport, Textaufbereitung, Vektorisierung, Indexierung und Antwortgenerierung getrennt konfiguriert und ausgeführt werden können.
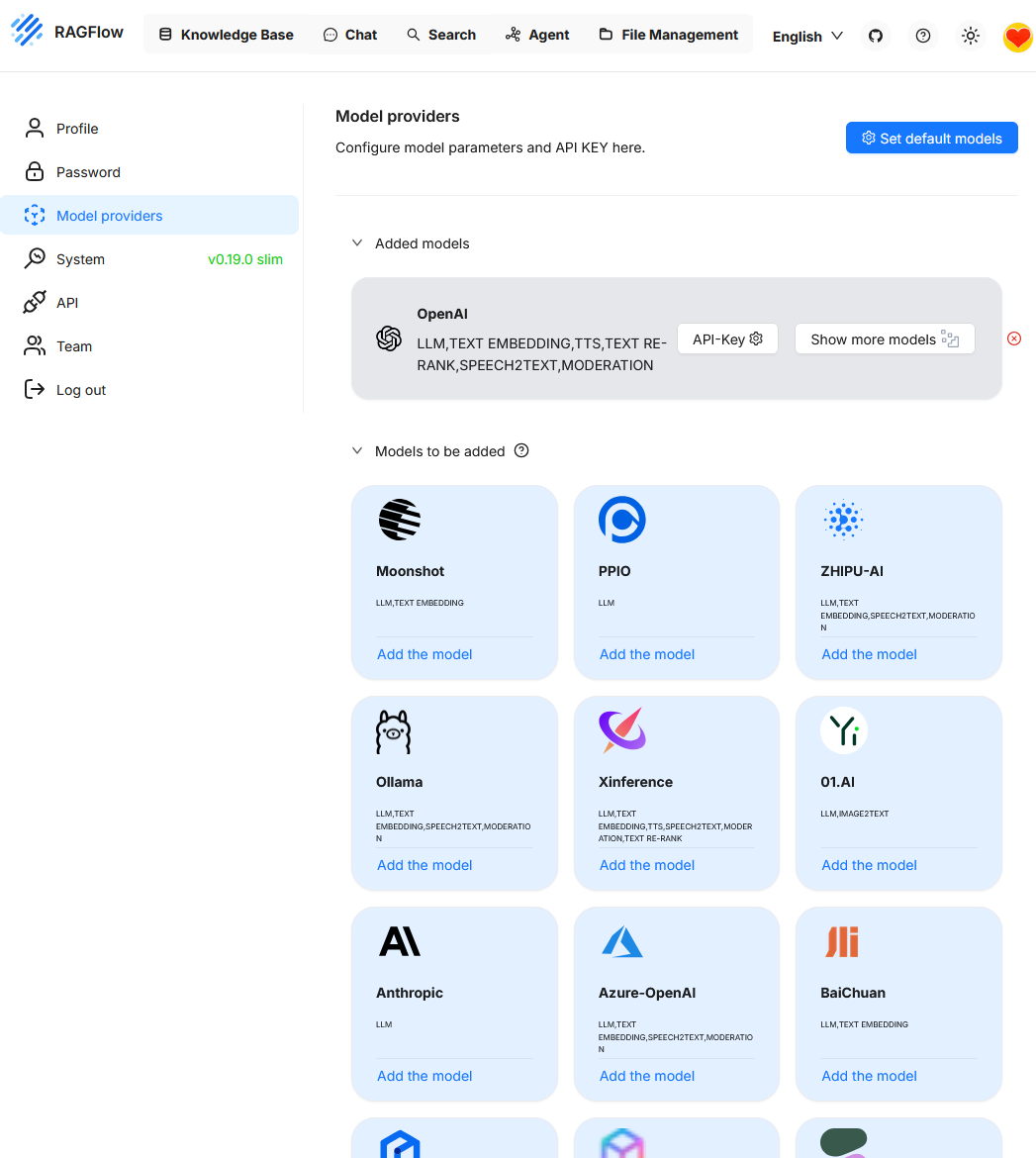
Models
Die Plattform unterstützt unterschiedliche Speicherlösungen für Vektordaten und erlaubt die Anbindung verschiedener LLMs. Die Liste der unterstützten LLM sind hier zu finden.
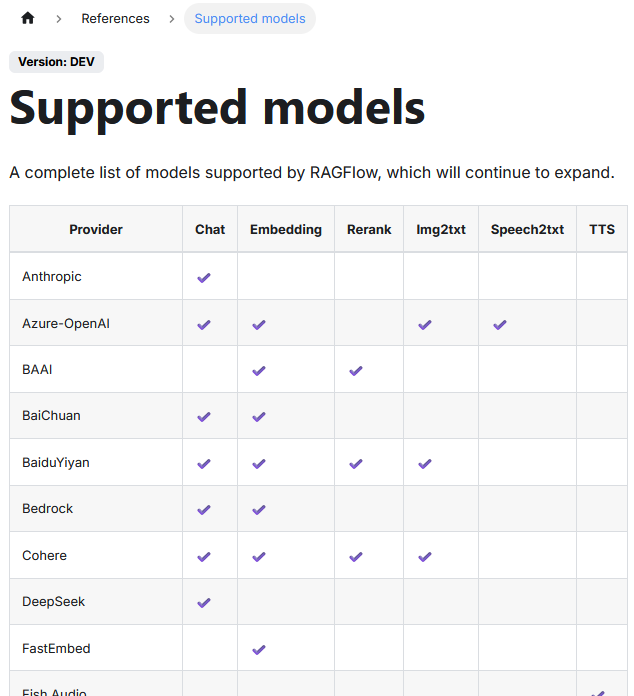
| Spalte | Bedeutung |
| Provider | Anbieter oder Quelle des Modells. Kann ein Cloud-Dienst (z.B. OpenAI) oder ein Modellentwickler (z.B. Cohere, BAAI) sein. |
| Chat | Unterstützt dialogorientierte Sprachmodelle, die für Konversation oder Antwortgenerierung verwendet werden. |
| Embedding | Bietet Einbettungsmodelle zur Umwandlung von Texten in Vektoren für semantische Suche oder Klassifikation. |
| Rerank | Modelle zur Re-Rangierung bereits gefundener Treffer, um relevantere Ergebnisse weiter oben anzuzeigen. |
| Img2txt | Modelle zur Bildbeschreibung: Wandeln ein Bild in einen beschreibenden Text um. |
| Speech2txt | Modelle zur Umwandlung von gesprochener Sprache in geschriebenen Text (ASR – Automatic Speech Recognition). |
| TTS | Text-to-Speech: Wandelt geschriebenen Text in synthetische Sprache um. In der Tabelle noch ohne Unterstützung. |
OpenAI stellt keine Unterstützung für die Funktion „Rerank“ bereit.

In diesem Beispiel ist bislang nur das OpenAI-Modell eingebunden. Weitere Modelle wie z.B. Ollama, lassen sich bei Bedarf ebenfalls hinzufügen.
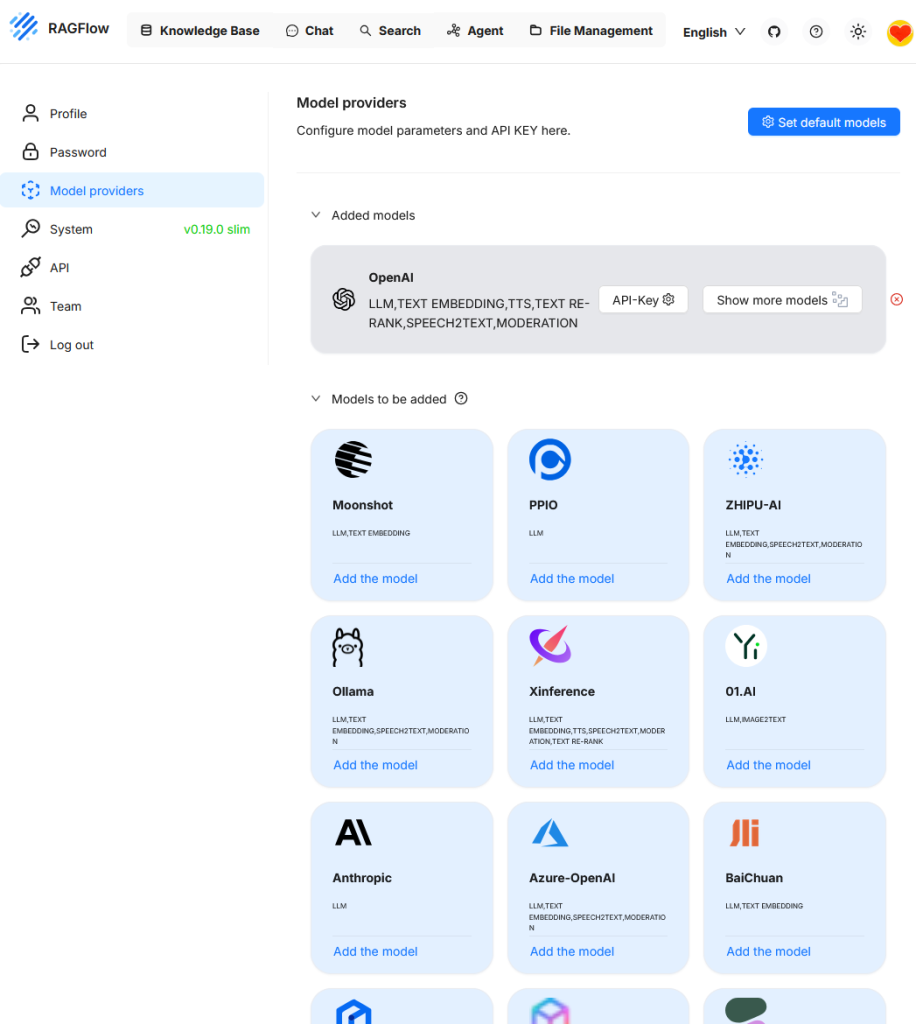
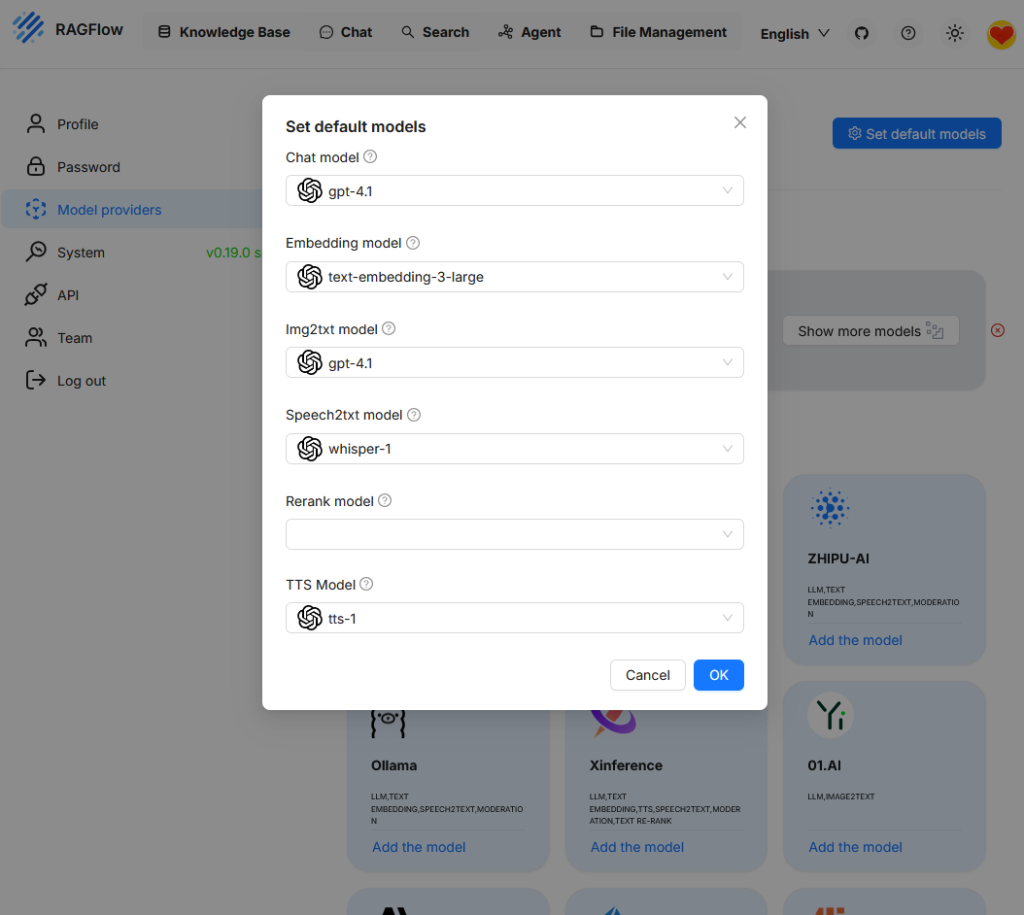
Beim Aufruf von „Set default models“ wird die derzeit aktive Modellkonfiguration angezeigt. Da zuvor lediglich „OpenAI“ als Anbieter eingebunden wurde, steht aktuell auch nur dieses Modell zur Auswahl. Um zusätzliche Funktionen wie das Reranking nutzen zu können, muss zunächst ein weiteres Modell hinterlegt werden.
Knowledge Base (NB)
In RAGFlow bezeichnet die Knowledge Base den zentralen Speicherort für Inhalte, die bei Anfragen durchsucht und als Grundlage für generierte Antworten verwendet werden. Sie besteht aus vektorisierten Chunks, die aus importierten Dokumenten stammen und ist direkt mit den Retrieval- und Ranking-Komponenten verbunden.
Beim Anlegen einer Knowledge Base kann ein Embeddingmodell ausgewählt werden, das für die Vektorisierung der Inhalte verwendet wird. Diese Wahl ist verbindlich. Eine nachträgliche Änderung des Modells ist nicht vorgesehen. Soll ein anderes Modell genutzt werden, muss eine neue Knowledge Base erstellt und der Datenbestand erneut eingebunden werden.
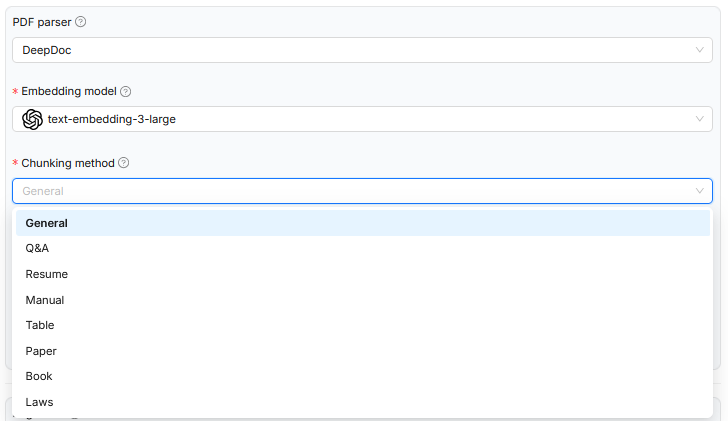
Im dargestellten Beispiel wurde beim Hochladen eines Dokuments in RAGFlow die Chunking-Methode festgelegt, um die inhaltliche Struktur des Textes möglichst sinnvoll in kleinere Einheiten zu zerlegen. Dabei wird abhängig vom gewählten Dokumenttyp wie wissenschaftliche Arbeiten, Gesetzestexte oder Tabellen eine passende Regelbasis zur Segmentierung verwendet. Diese Steuerung betrifft ausschließlich die logische Zerlegung des Dokuments und wirkt sich darauf aus, wie die Chunks später im semantischen Raum abgelegt werden. Das verwendete Embeddingmodell bleibt jedoch in allen Fällen gleich und ist nicht auf die jeweilige Dokumentart spezialisiert. Auch der Systemprompt, der den Kontext für das Sprachmodell definiert, wird nicht dynamisch angepasst. Die Verarbeitung ist damit zwar formal auf die Textstruktur abgestimmt, aber inhaltlich nicht auf die jeweilige Domäne zugeschnitten.
Eine mögliche Verbesserung wäre, den gewählten Dokumenttyp nicht nur für die Chunkinglogik, sondern auch für die Auswahl spezialisierter Modelle zu berücksichtigen. Für juristische Dokumente könnten etwa Embeddingmodelle eingesetzt werden, die auf juristische Sprache und Strukturen trainiert wurden. Alternativ ließen sich systematisch formulierte Systemprompts ergänzen, die dem Modell helfen, den Kontext der Chunks besser einzuordnen, beispielsweise durch Hinweise auf Gesetzesbezüge, Argumentationslinien oder normative Aussagen. Auch die Einbindung domänenspezifischer Ontologien könnte die semantische Einbettung und spätere Abfrage verbessern. Insbesondere bei formellen Textsorten wie Gesetzestexten oder technischen Normen könnten so Relationen, Begriffsdefinitionen und übergreifende Strukturen explizit modelliert werden. Auf diese Weise würde der Verarbeitungsprozess nicht nur formale Aspekte berücksichtigen, sondern auch semantische Tiefe und domänenspezifisches Wissen systematisch integrieren.
Dataset
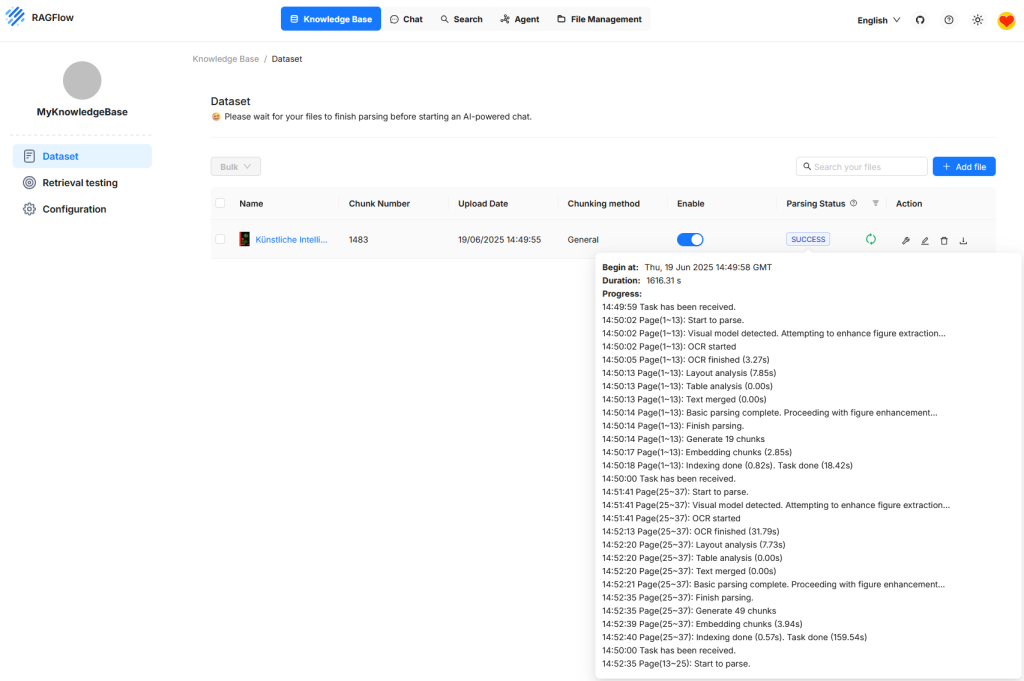
Die Abbildung zeigt die Benutzeroberfläche von RAGFlow im Bereich der Knowledge Base, konkret im Abschnitt Dataset. Es ist ein Dokument zu sehen, das erfolgreich hochgeladen und verarbeitet wurde. Der Status zeigt an, dass die Verarbeitung abgeschlossen ist und das Dokument nun für Anfragen bereitsteht. Die Verarbeitung umfasst verschiedene Schritte wie die Texterkennung, Layoutanalyse, Segmentierung in einzelne Chunks und die Einbettung dieser Abschnitte in den Vektorraum. Die Anzahl der erzeugten Chunks wird angezeigt, ebenso ein detailliertes Protokoll der Verarbeitungsschritte. Dieses kann zur Kontrolle und Fehleranalyse genutzt werden. Solange die Verarbeitung noch läuft, weist RAGFlow darauf hin, dass ein KI-gestützter Chat erst nach Abschluss aller Schritte sinnvoll ist.
Retrieval Testing
Unter „Retrieval Testing“ kann überprüft werden, ob das System relevante Textpassagen (Chunks) aus einer vorhandenen Knowledge Base zu einer konkreten Benutzerfrage korrekt auffindet. Im Testfeld unten links wurde beispielsweise die Frage „Wie heißt das Buch?“ eingegeben. Auf der rechten Seite werden die gefindenen Antworten angezegt. Die Ähnlichkeitswerte für jede Passage werden dreifach angezeigt: Hybrid Similarity, Term Similarity und Vector Similarity.
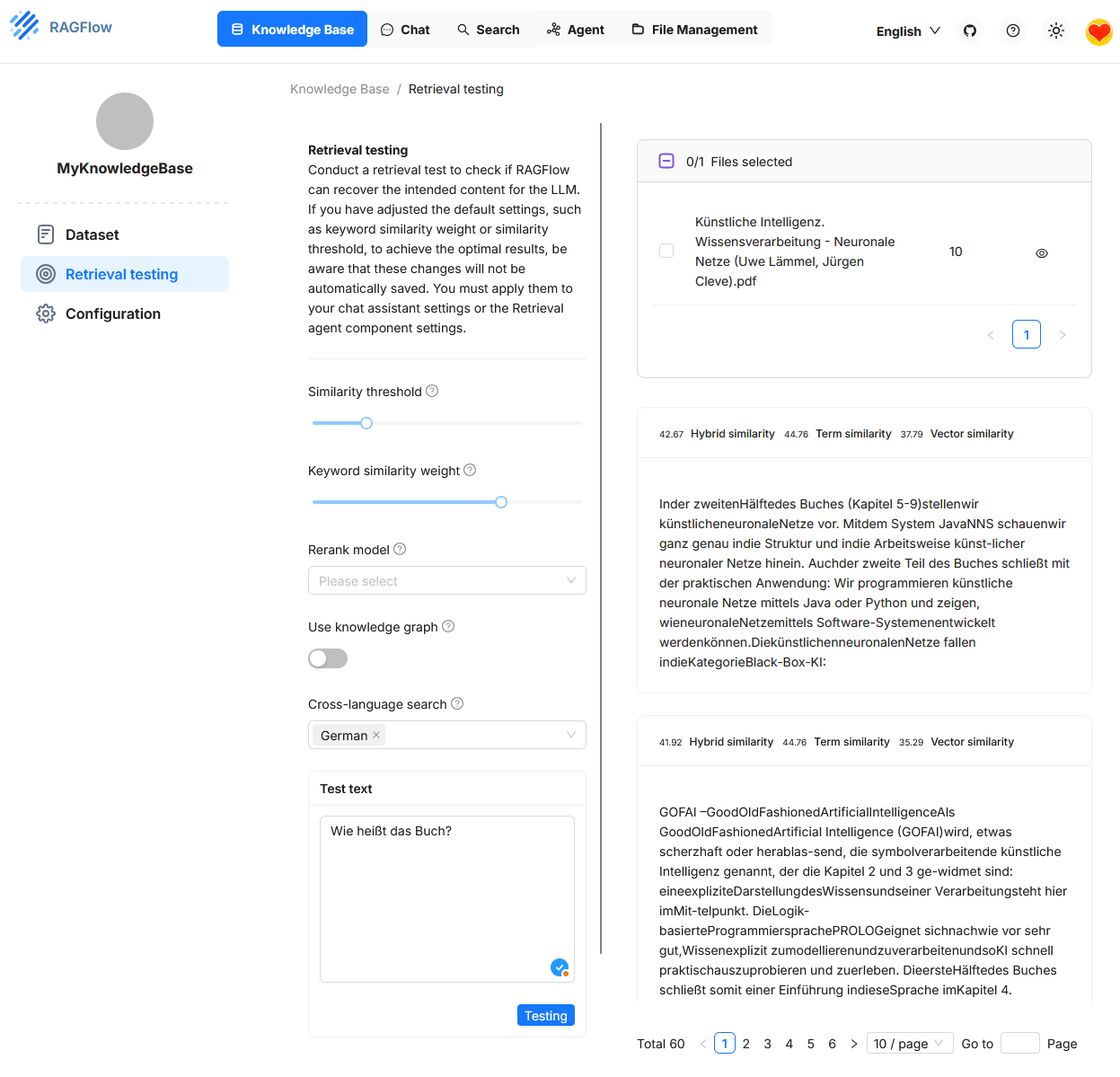
Diese Testumgebung dient der Feinabstimmung der Retrieval-Konfiguration. Sie erlaubt es, verschiedene Parameter gezielt zu verändern, um die Qualität der Trefferauswahl zu verbessern. Die Auswirkungen der Einstellungen werden dabei sofort sichtbar. Die Konfiguration selbst wirkt sich jedoch nur temporär auf den Retrieval-Test aus. Damit sie auch im eigentlichen Chat oder bei einem Agenten Anwendung findet, muss sie separat übernommen werden.3,
KB-Parameter
Vector Similarity
Vector Similarity basiert auf der semantischen Repräsentation von Texten in einem hochdimensionalen Vektorraum. Jeder Textabschnitt sowie jede Benutzeranfrage wird durch ein Embedding-Modell (z.B. OpenAI, Cohere) in einen numerischen Vektor überführt. Die Ähnlichkeit zwischen zwei Vektoren wird typischerweise über die Kosinusähnlichkeit berechnet.
- Vorteil: Erfasst Bedeutungsähnlichkeiten auch bei unterschiedlicher Wortwahl. So erkennt das System z.B., dass „Was ist künstliche Intelligenz?“ und „Worum geht es bei AI?“ semantisch ähnlich sind, obwohl keine Schlüsselwörter übereinstimmen.
- Nachteil: Reine Vektorähnlichkeit kann bei kurzen Texten oder stark domänenspezifischen Begriffen ungenau sein, besonders wenn das Embedding-Modell diese nicht korrekt abbildet.
Term Similarity
Term Similarity bewertet die lexikalische Übereinstimmung zwischen der Anfrage und dem Textabschnitt. Das Verfahren basiert meist auf dem Token-Vergleich, z.B. mit TF-IDF, BM25 oder Jaccard-Ähnlichkeit.
- Vorteil: Liefert präzise Ergebnisse, wenn konkrete Begriffe oder Namen gesucht werden. Etwa bei Fragen wie „Was sagt Müller in Kapitel 3?“.
- Nachteil: Ignoriert Synonyme und semantische Zusammenhänge. Eine rein terminologische Suche erkennt keine Bedeutungsnähe zwischen „Haus“ und „Gebäude“.
Hybrid Similarity
Hybrid Similarity kombiniert mehrere Ähnlichkeitsmetriken zu einem Gesamtwert. In RAGFlow ist dies in der Regel eine gewichtete Kombination aus Vector Similarity und Term Similarity. Alternativ kann auch ein Re-Rank-Modell hinzukommen, wenn dieses aktiviert ist.
- Vorteil: Vereint semantische und lexikalische Ähnlichkeit. Dies führt zu robusteren Ergebnissen in realen Anwendungsfällen, z. B. bei heterogenen Dokumenten oder unklaren Fragen.
- Nachteil: Kann in bestimmten Situationen schwerer nachvollziehbar sein, da die Gewichtung das Ergebnis stark beeinflusst.
Configuration
In diesem Bereich werden zentrale Eigenschaften definiert, die bestimmen, wie Dokumente verarbeitet, zerlegt und später für semantische Suchanfragen verfügbar gemacht werden. Die Konfiguration umfasst dabei sowohl strukturelle als auch funktionale Einstellungen. Auf der linken Seite werden Eingabefelder und Steueroptionen angeboten, mit denen sich die Verarbeitung von Texten und Metadaten anpassen lässt. Rechts daneben wird am Beispiel der Methode „General“ visuell dargestellt, wie Texte zunächst in Segmente aufgeteilt und anschließend zu Chunks zusammengeführt werden. Dieser Bereich erlaubt eine präzise Steuerung des Verhaltens beim Parsen und Vektorisieren und ist besonders dann relevant, wenn spezifische Dokumenttypen oder Anwendungsfälle berücksichtigt werden sollen.
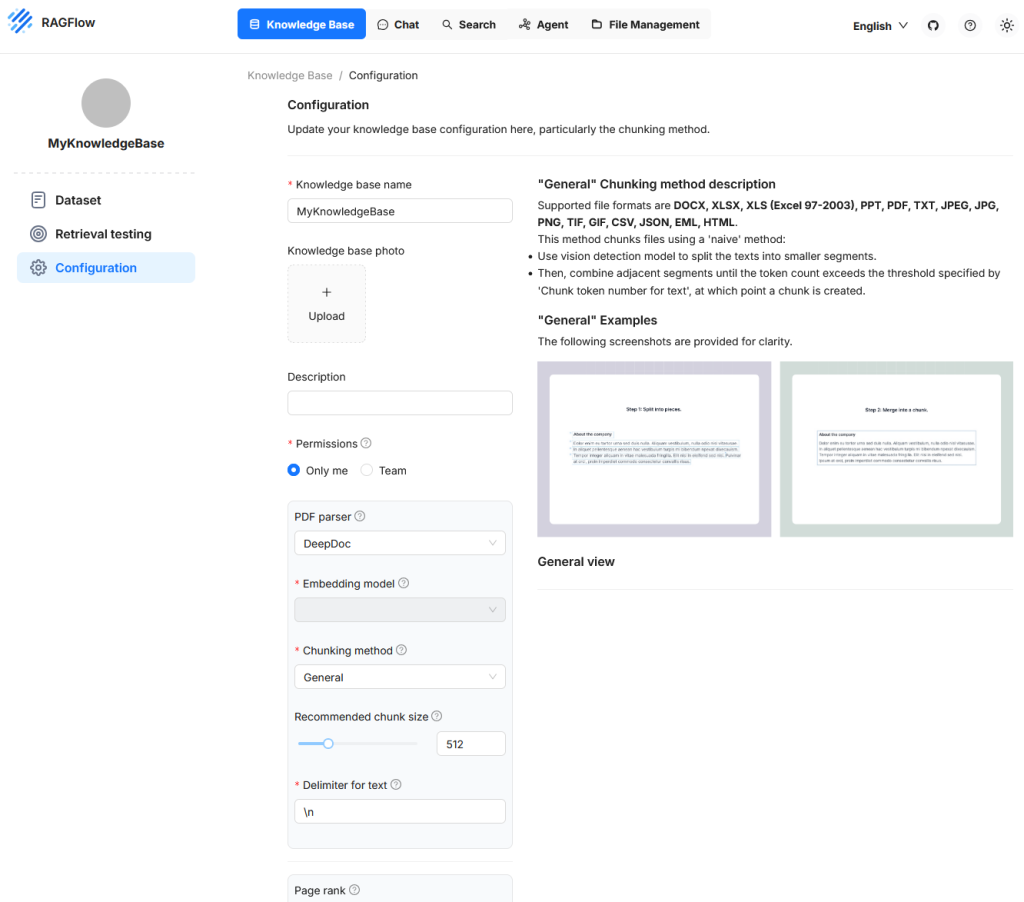
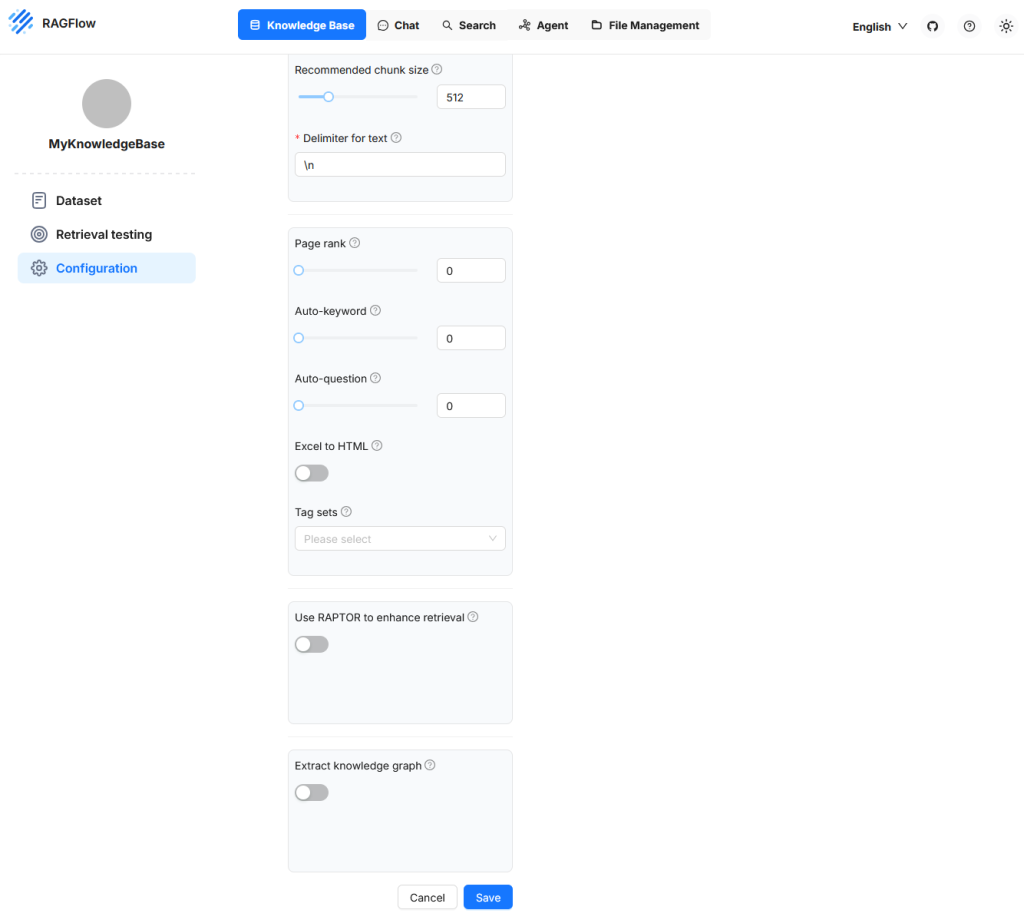
Recommended Chunk Size
Dieser Wert legt fest, wie viele Tokens ein Chunk in der Regel enthalten soll. Wenn ein Segment im Dokument weniger Tokens enthält als dieser Grenzwert, wird es mit nachfolgenden Segmenten zusammengeführt, bis die Gesamtzahl die definierte Grenze überschreitet. Erst dann wird ein neuer Chunk erzeugt. Dabei wird jedoch kein neuer Chunk gebildet, solange kein expliziter Trenner erkannt wurde. Diese Einstellung beeinflusst, wie kompakt oder fein aufgelöst die Inhalte der Knowledge Base später abgefragt werden können.
Delimiter for Text
Ein Delimiter ist ein spezielles Zeichen oder eine Zeichenfolge, die als Trennsignal zwischen Textabschnitten dient. Beispiele sind Zeilenumbrüche oder benutzerdefinierte Marker wie ## oder bestimmte Satzzeichenfolgen.
Page Rank
Mit dieser Einstellung kann eine Knowledge Base priorisiert werden. Ein höherer Page-Rank-Wert sorgt dafür, dass Inhalte aus dieser Quelle bei konkurrierenden Treffern bevorzugt werden. Der Wert wird zur berechneten Ähnlichkeit addiert und beeinflusst damit die Sortierung der Ergebnisse. So lassen sich bestimmte Datenquellen gezielt gewichten, etwa wenn sie als besonders zuverlässig gelten.
Auto-Keyword
Diese Funktion bewirkt, dass zu jedem Chunk automatisch Schlüsselbegriffe (Keywords) generiert werden. Diese Begriffe können später bei der Abfrage helfen, indem sie die Trefferwahrscheinlichkeit für Fragen mit passenden Stichwörtern erhöhen. Die Extraktion erfolgt durch ein Sprachmodell und erfordert zusätzliche Rechenressourcen. Die ermittelten Begriffe können nachträglich eingesehen und bei Bedarf angepasst werden. Der Wert z.B. 2 bedeutet, das zu einem Chunk zwei Schlüsselbegriffe generiert werden.
Auto-Question
Hierbei werden aus dem Inhalt eines Chunks automatisch mögliche Fragen erzeugt. Diese dienen dazu, die Relevanz eines Chunks bei entsprechenden Benutzeranfragen zu steigern. Auch diese Funktion verwendet ein Sprachmodell und ist fehlertolerant. Sollte die Erzeugung einer Frage scheitern, bleibt der Chunk erhalten. Die Fragen lassen sich später überprüfen und bei Bedarf manuell ergänzen oder korrigieren.
Excel to HTML
Diese Einstellung betrifft die Verarbeitung von Excel-Dateien. Ist die Option deaktiviert, werden die Inhalte als Schlüssel-Wert-Paare (Key-Value Paare) interpretiert. Ist sie aktiviert, werden die Tabellen in HTML-Strukturen überführt. Dabei werden Tabellen mit mehr als zwölf Zeilen in mehrere Blöcke unterteilt. Diese Strukturierung ist hilfreich, wenn die Tabellenstruktur in der Ergebnisdarstellung erhalten bleiben soll.
Tag Sets
Diese Funktion ermöglicht es, Textabschnitte gezielt mit Schlagwörtern zu versehen, die aus einem vorher festgelegten Begriffsvorrat stammen. Ein solcher Begriffsvorrat kann zum Beispiel aus folgenden Einträgen bestehen: Datenschutz, Vertragsrecht, Arbeitsrecht, Steuerpflicht. Wird nun ein Dokument mit juristischen Inhalten verarbeitet, prüft das System für jeden Abschnitt, ob einer dieser Begriffe enthalten ist oder inhaltlich angesprochen wird.
Die Textabschnitte, also die Chunks, werden dabei unabhängig vom Tag Set anhand der gewählten Chunking-Einstellungen gebildet. Das Tagging erfolgt erst nach der Chunk-Bildung. Wenn ein Chunk einen Begriff aus dem Tag Set enthält oder diesem semantisch entspricht, wird er mit dem zugehörigen Tag versehen. Diese Verschlagwortung ergänzt den Chunk um strukturierte Metadaten, die später bei Suchanfragen berücksichtigt werden können. So lässt sich zum Beispiel gezielt nach allen Abschnitten mit dem Tag Datenschutz filtern oder bei der Relevanzbewertung stärker gewichten. Die Zuordnung basiert auf einem festen, kontrollierten Vokabular und unterscheidet sich damit deutlich vom Auto-Keyword-Verfahren, bei dem ein Sprachmodell eigenständig relevante Begriffe aus dem Text ableitet, ohne an eine vorgegebene Begriffsliste gebunden zu sein.
Extract knowledge graph
Die Funktion Extract knowledge graph erstellt aus den vorhandenen Chunks einer Knowledge Base automatisch einen Wissensgraphen. Dabei werden Entitäten, Relationen und deren Verbindungen extrahiert und in strukturierter Form abgelegt. Ziel ist es, die logischen Zusammenhänge zwischen Begriffen und Aussagen explizit sichtbar und maschinell nutzbar zu machen.
Ein solcher Graph ermöglicht es, komplexe Abfragen zu beantworten, bei denen Informationen aus mehreren Chunks logisch miteinander verknüpft werden müssen. Das ist besonders relevant für sogenannte Multi-Hop-Fragen, bei denen eine Antwort nicht direkt in einem einzelnen Textabschnitt steht, sondern sich aus mehreren Informationen zusammensetzt.
Die Extraktion erfolgt modellgestützt während oder nach dem Parsen. Aktivierst du diese Funktion, analysiert RAGFlow die Chunks automatisch auf typische Muster wie Subjekt-Prädikat-Objekt-Strukturen, kausale Abhängigkeiten oder hierarchische Zuordnungen. Die Ergebnisse fließen in eine Graphstruktur ein, die wiederum als Grundlage für präzisere und strukturierte Retrievalprozesse genutzt werden kann.
Diese Funktion bildet die Grundlage für die spätere Aktivierung von RAPTOR, das diesen Graphen nutzt, um gezielte, logikbasierte Antwortketten zu erzeugen.
Use RAPTOR to Enhance Retrieval
Die Funktion Use RAPTOR to enhance retrieval in RAGFlow aktiviert ein erweitertes Verfahren zur Informationsabfrage, das auf der Nutzung eines Wissensgraphen basiert. Dieser Wissensgraph muss zuvor durch die Funktion Extract knowledge graph erzeugt worden sein.
Ein klassisches Retrieval sucht bei einer Benutzeranfrage nach denjenigen Chunks, die inhaltlich am besten zu der Frage passen. Diese Chunks werden einzeln bewertet, in ihrer Reihenfolge sortiert und dem Sprachmodell zur Antwortgenerierung zur Verfügung gestellt. Dabei wird jedoch jeder Chunk für sich betrachtet.
RAPTOR erweitert diesen Mechanismus: Statt nur einzelne Chunks zu bewerten, analysiert das System die Beziehungen zwischen mehreren Chunks über den aufgebauten Wissensgraphen. Es führt also mehrstufige, logikbasierte Verknüpfungen durch. Das bedeutet, dass auch dann eine Antwort gefunden werden kann, wenn die relevanten Informationen nicht in einem einzigen Chunk stehen, sondern auf mehrere verteilt sind und logisch miteinander verknüpft werden müssen.
Chat
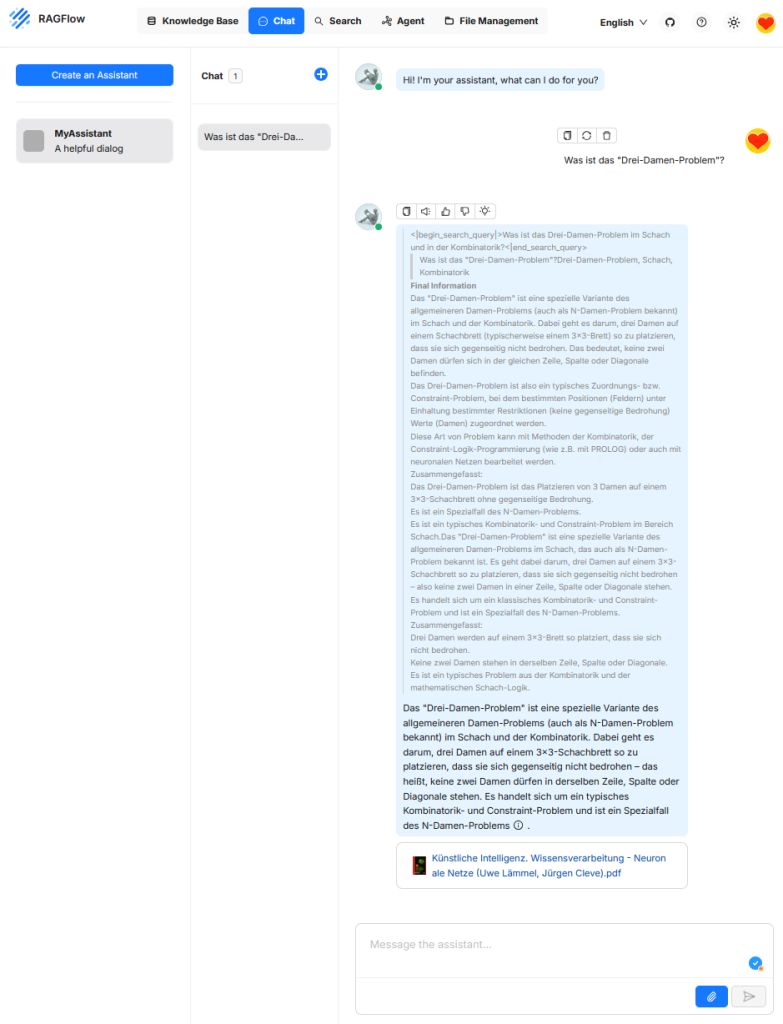
Die Funktion „Chat“ dient als Benutzerschnittstelle zur interaktiven Abfrage eines retrieval-gestützten Systems. Dabei wird eine natürliche Spracheingabe des Nutzers entgegengenommen, durch ein Large Language Model interpretiert und mit dem Ziel kombiniert, relevante Informationen aus einer angebundenen Wissensquelle zu extrahieren. Die Chat-Komponente bildet somit das zentrale Bedienfeld für den Zugriff auf die Retrieval- und Generierungslogik von RAGFlow und ermöglicht es, Dokumentinhalte explorativ, fragengesteuert und interaktiv zu erschließen. Im Unterschied zu klassischen Chatbots wie ChatGPT basiert die Antwort nicht auf allgemeinem Weltwissen des Modells, sondern auf den zuvor abgerufenen Inhalten aus der Wissensbasis.
In RAGFlow bezeichnet ein „Assistant“ eine konfigurierbare Einheit zur Durchführung von nutzergeführten Dialogen, bei denen Informationen aus definierten Wissensbasen abgerufen und durch ein Sprachmodell verarbeitet werden. Die Einrichtung eines Assistenten erfolgt über eine dialoggeführte Konfiguration, die in drei thematische Reiter unterteilt ist: „Assistant settings“, „Prompt engine“ und „Model settings“.
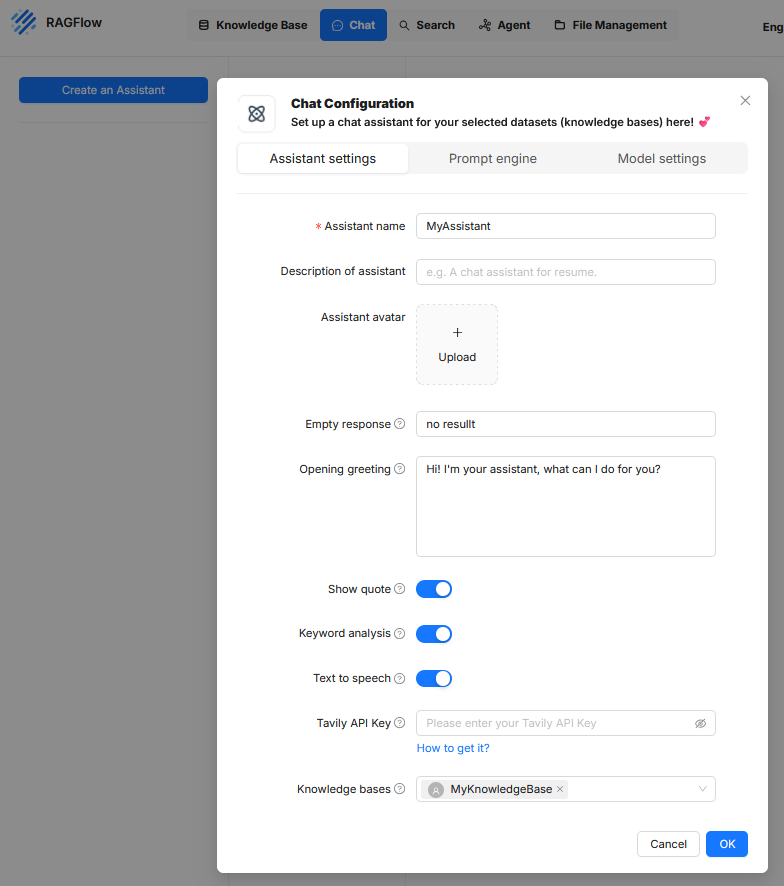
Assistant settings
Dieser Bereich definiert die Metadaten und das äußere Verhalten des Assistenten in der Benutzeroberfläche. Er enthält folgende Einstellungen:
- Assistant name bezeichnet den internen Namen des Assistenten.
- Description of assistant ist ein optionales Textfeld zur Beschreibung des Einsatzzwecks.
- Assistant avatar erlaubt das Hochladen eines Bildes zur Visualisierung des Assistenten.
- Empty response legt fest, welcher Text angezeigt wird, wenn keine passende Antwort generiert werden kann.
- Opening greeting enthält eine Begrüßungsnachricht, die beim Start der Interaktion erscheint.
- Show quote aktiviert die Anzeige von Quellenzitaten, sofern Dokumentreferenzen vorhanden sind.
- Keyword analysis steuert die Erkennung von Schlüsselbegriffen zur Verbesserung der Suchanfrage.
- Text to speech ermöglicht eine Sprachausgabe der Antwortinhalte.
- Tavily API Key erlaubt die Einbindung externer Suchdienste zur Anreicherung von Kontextdaten.
- Knowledge bases stellt die Verbindung zu einer oder mehreren Wissensquellen her, auf deren Basis die Antwortgenerierung erfolgt.
Prompt engine
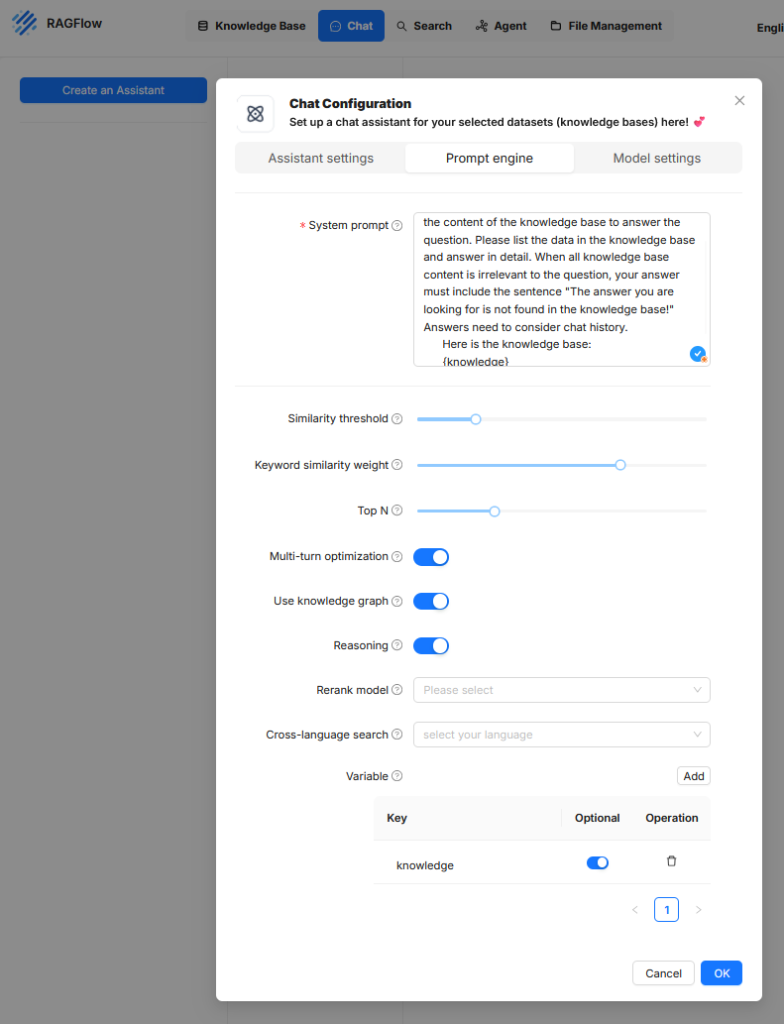
In diesem Reiter werden die internen Anweisungen und Suchstrategien festgelegt, mit denen das Sprachmodell auf die Wissensbasis zugreift und Ergebnisse verarbeite.
- Systemprompt
Ist ein fest definierter Steuertext, der dem Sprachmodell bei jeder Anfrage mitgegeben wird. Es enthält klare Anweisungen, wie das Modell auf die vom Retriever gelieferten Inhalte reagieren soll. Dieser Prompttext kann auch den Aufbau der Antwort, die Berücksichtigung des Chatverlaufs oder die Strukturierung von Quellenangaben regeln. - Similarity threshold
Dieser Schwellenwert legt fest, ab welcher semantischen Ähnlichkeit ein Dokumentausschnitt als relevant betrachtet und an das Sprachmodell weitergeleitet wird. Ein höherer Wert führt dazu, dass nur sehr eng verwandte Inhalte berücksichtigt werden. Ein niedriger Wert erhöht die Toleranz gegenüber abweichenden, aber möglicherweise dennoch informativen Inhalten. Der Schwellenwert wirkt direkt auf die Anzahl und Qualität der abgerufenen Kontextpassagen. - Keyword similarity weight
Dieser Parameter bestimmt, in welchem Ausmaß die Übereinstimmung von Schlüsselbegriffen (Tokens mit hoher Gewichtung) bei der Bewertung der Relevanz einbezogen wird. Ein hoher Wert bedeutet, dass exakte Begriffe stärker gewichtet werden, während ein niedriger Wert die semantische Nähe auf Satz- oder Bedeutungsebene priorisiert. Diese Gewichtung beeinflusst, ob der Fokus eher auf formaler Übereinstimmung oder inhaltlicher Ähnlichkeit liegt. - Top N
Definiert die maximale Anzahl an Kontextpassagen, die aus der Wissensbasis entnommen und dem Sprachmodell zur Verfügung gestellt werden. Diese Auswahl erfolgt nach Relevanzbewertung. Ein niedriger Wert wie 3 oder 5 führt zu einem kompakteren Kontext, reduziert aber möglicherweise relevante Zusatzinformationen. Höhere Werte können die Antwortqualität verbessern, führen aber zu längeren Prompts und möglicherweise zu einem Überschreiten der Token-Grenze des Modells. - Multi-turn optimization
Mit dieser Einstellung wird die Kontextführung über mehrere Gesprächsrunden hinweg aktiviert. Das bedeutet, dass der Chatverlauf berücksichtigt wird, sodass Anschlussfragen oder Rückbezüge auf vorherige Aussagen korrekt interpretiert werden können. Diese Option ist besonders bei komplexen Dialogen oder Nachfragen erforderlich, erhöht aber die Komplexität der Promptstruktur und das Tokenvolumen. - Use knowledge graph
Bei aktivierter Option wird zusätzlich zu unstrukturierten Texten ein strukturierter Wissensgraph in die Antwortgenerierung einbezogen. Dieser Graph kann Entitäten und Relationen enthalten, die systematisch aus der Wissensbasis extrahiert wurden. Dadurch kann das Modell logische Beziehungen zwischen Konzepten besser erfassen und strukturierte Antworten liefern. Voraussetzung ist, dass ein entsprechender Wissensgraph im System verfügbar ist. - Reasoning
Diese Funktion erweitert die generative Verarbeitung um logische Schlussfolgerungen. Das Modell wird dadurch angewiesen, nicht nur Inhalte wiederzugeben, sondern aus den Kontextdaten Aussagen abzuleiten, etwa Zusammenhänge zu erkennen oder implizite Bedeutungen zu erschließen. Dies kann die inhaltliche Tiefe der Antworten erhöhen, birgt aber ein gewisses Risiko für ungewollte Halluzinationen, wenn die Datengrundlage nicht eindeutig ist. - Rerank model
Falls aktiviert, wird ein zusätzliches Modell verwendet, um die vom Retriever gelieferten Dokumente nachträglich neu zu bewerten und in eine bessere Reihenfolge zu bringen. Dies dient der Qualitätskontrolle der Ergebnisliste, insbesondere wenn der primäre Retrievalmechanismus viele irrelevante oder konkurrierende Treffer liefert. Hier können spezialisierte Modelle eingesetzt werden, etwa auf Ranking oder Vergleich optimierte Transformer-Modelle. - Cross-language search
Mit dieser Option lässt sich eine Zielsprache für sprachübergreifende Suchanfragen definieren. Damit können Nutzer Fragen in einer Sprache stellen (z.B. Deutsch), während die Wissensbasis in einer anderen Sprache (z.B. Englisch) abgefasst ist. Voraussetzung ist, dass das Retrieval-Modell sowie das Sprachmodell multilingual arbeiten können. Die Ergebnisse werden dabei automatisch übersetzt oder entsprechend interpretiert. - Variable
Hier werden Platzhalter definiert, die innerhalb des Systemprompts verwendet werden können. Bei Verwendung des Platzhalters {knowledge} im Systemprompt wird dieser zur Laufzeit automatisch durch den jeweils aus der Wissensbasis abgerufenen Text ersetzt. Wird beispielsweise im Chat die Frage „Was ist ein Lastenheft?“ gestellt, sucht das System nach semantisch passenden Textpassagen in der angebundenen Wissensquelle. Findet es etwa den Satz „Ein Lastenheft beschreibt die Anforderungen des Auftraggebers an die Leistungen des Auftragnehmers“, wird dieser als Kontext ausgewählt. Ist im Systemprompt der Ausdruck „Beantworte die Frage ausschließlich auf Grundlage des folgenden Inhalts: {knowledge}“ hinterlegt, ersetzt das System den Platzhalter durch die gefundene Passage. Das Sprachmodell erhält dann den vollständigen Prompt: „Beantworte die Frage ausschließlich auf Grundlage des folgenden Inhalts: Ein Lastenheft beschreibt die Anforderungen des Auftraggebers an die Leistungen des Auftragnehmers.“ Dieser Prompt wird gemeinsam mit der ursprünglichen Nutzerfrage an das Modell übergeben, das daraus eine Antwort generiert. Die Verwendung von Platzhaltern wie {knowledge} ermöglicht eine generische Promptstruktur, die zur Laufzeit automatisch mit den relevanten Inhalten befüllt wird. Weitere Platzhalter können definiert werden, etwa für die Frage, Zeitstempel oder Metadaten. Auf diese Weise lässt sich der Prompt wiederverwendbar und modular gestalten.gefüllt werden.
Model settings
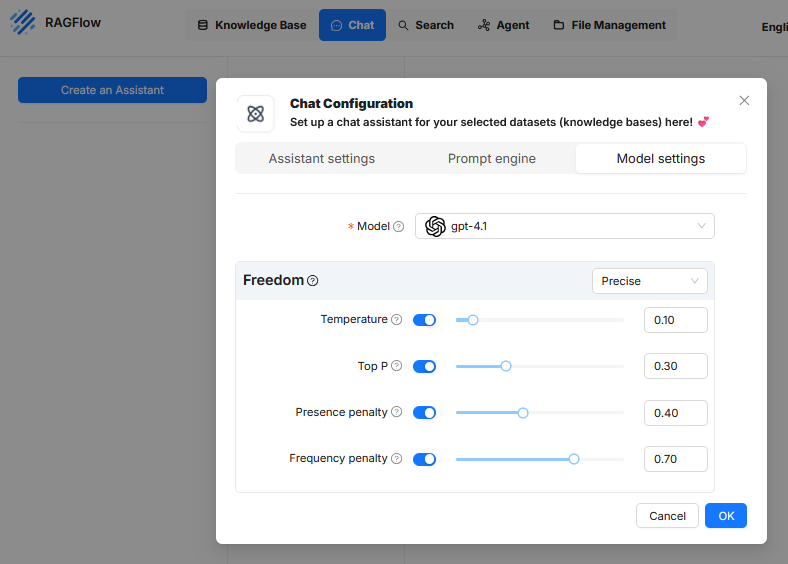
Im Reiter Model settings der Chat-Konfiguration in RAGFlow werden Parameter festgelegt, die das Antwortverhalten des zugrundeliegenden Sprachmodells steuern. Diese Einstellungen beeinflussen nicht die Auswahl der Inhalte aus der Wissensbasis, sondern die Art und Weise, wie das Modell mit diesen Inhalten arbeitet und darauf basierend Texte generiert. Ziel ist es, die Antwortqualität, Genauigkeit, Ausdrucksweise und Redundanz gezielt zu regulieren. Die folgenden Parameter stehen zur Verfügung:
- Model
Hier wird das Sprachmodell ausgewählt, das zur Generierung der Antworten verwendet werden soll. In der aktuellen Konfiguration ist „gpt-4.1“ aktiviert. Diese Auswahl bestimmt maßgeblich die Leistungsfähigkeit, den Antwortstil und die Token-Grenzen des Assistenten. - Freedom (Profilvoreinstellung)
In der Benutzeroberfläche kann ein vordefiniertes Profil ausgewählt werden, etwa „Precise“. Dieses Profil fasst die oben genannten Parameter in einer festen Kombination zusammen.- Precise (Präzise): Konfiguriert das Modell für maximale Faktentreue und deterministische Ausgaben. Die Antworten sind konsistent und eng an der Datenbasis orientiert. Typischerweise werden hierfür Temperature und Top P auf sehr niedrige Werte gesetzt.
- Improvise (Improvisieren): Konfiguriert das Modell für maximale Kreativität und Varianz. Diese Einstellung ist für die Generierung von Ideen und vielfältigen Texten vorgesehen. Temperature und Top P werden auf hohe Werte gesetzt.
- Balance (Ausgewogen): Wählt eine mittlere Konfiguration, die eine Balance zwischen zuverlässigen Informationen und natürlicher, gesprächiger Sprache herstellt
- Temperature
Dieser Parameter steuert die Zufälligkeit in der Textgenerierung.- Ein niedriger Wert (z.B. nahe 0) zwingt das Modell, fast immer die offensichtlichste und sicherste Wortwahl zu treffen. Wenn der Satz „Der Himmel ist…“ lautet, wird das Modell mit sehr hoher Sicherheit „blau“ wählen. Die Texte sind dadurch sehr präzise, faktenorientiert und bei gleicher Anfrage oft identisch.
- Ein hoher Wert (z.B. nahe 1) ermutigt das Modell, auch seltenere und kreativere Wörter auszuwählen, die ebenfalls passen könnten. Bei „Der Himmel ist…“ könnte es dann „wolkenlos“, „unendlich“ oder „atemberaubend“ wählen. Die Texte werden dadurch abwechslungsreicher und unvorhersehbarer, können aber auch an Genauigkeit verlieren.
- Top P
Um die Funktion von „Top P“ zu verstehen, muss zuerst der Prozess betrachtet werden, wie eine KI Text erzeugt. Eine KI schreibt einen Satz nicht als Ganzes, sondern Wort für Wort. Um das nächste Wort zu bestimmen, analysiert die KI den bereits geschriebenen Text. Wenn der bisherige Text also Das Wetter heute ist lautet, bezieht sich „das nächste Wort“ auf das Wort, das direkt danach folgen soll. Nach dieser Analyse erstellt die KI intern eine riesige Liste aller Wörter, die sie kennt (ihres gesamten Vokabulars) und weist jedem eine Wahrscheinlichkeit zu, wie gut es als nächstes Wort passen würde. An dieser Stelle greifen Parameter wie „Top P“. Der Parameter „Top P“ ist ein Filter, der auf diese riesige Liste aller möglichen Wörter angewendet wird. Seine Aufgabe ist es, einen kleinen, gefilterten „Auswahl-Pool“ für den aktuellen Schritt zu erstellen. Dazu wählt er die wahrscheinlichsten Wörter von der Spitze der Liste aus und addiert ihre Wahrscheinlichkeiten, bis die Summe den eingestellten Top P-Wert erreicht. Nur die Wörter, die in diese Berechnung einfließen, kommen in den finalen Auswahl-Pool. Das „nächste Wort“ wird dann endgültig aus diesem kleineren Pool ausgewählt.
Ein einfaches Beispiel verdeutlicht den Prozess: Angenommen, der Satzanfang lautet „Das Wetter heute ist“. Die KI berechnet für das nächste Wort nun verschiedene Wahrscheinlichkeiten, zum Beispiel: ’sonnig‘ hat eine Chance von 50%, ’schön‘ 25% und ‚regnerisch‘ 15%. Wenn der Top P-Wert niedrig auf 0.70 (oder 70%) eingestellt ist, erstellt die KI einen Auswahl-Pool, indem sie die wahrscheinlichsten Wörter zusammenrechnet, bis die 70%-Marke überschritten ist. In diesem Fall nimmt sie ’sonnig‘ (50%) und ’schön‘ (25%). Die Summe ist 75%, der Grenzwert ist überschritten. Der Pool besteht also nur aus den beiden Wörtern ’sonnig‘ und ’schön‘, die Antwort wird sehr vorhersehbar sein. Ist der Top P-Wert hingegen hoch auf 0.95 (oder 95%) eingestellt, ist der Pool größer. Zu ’sonnig‘ und ’schön‘ (zusammen 75%) kommt nun auch ‚regnerisch‘ (15%) hinzu, da die neue Summe von 90% unter der 95%-Grenze liegt. Der Pool enthält nun drei Wörter, was eine vielfältigere Antwort ermöglicht. - Presence penalty
Dieser Wert beeinflusst, ob das Modell in seiner Antwort bereits genannte Themen oder Begriffe erneut aufgreift.Sobald ein bestimmtes Thema oder Schlüsselwort einmal verwendet wurde, wird es mit einer negativen Gewichtung belegt. Das macht es für die KI weniger attraktiv, dieses selbe Thema erneut anzusprechen. Wenn die KI zum Beispiel in einer Beschreibung eines Autos bereits den „Motor“ erwähnt hat, sorgt die Presence Penalty dafür, dass sie im weiteren Verlauf eher dazu neigt, neue Aspekte wie die „Bremsen“ oder den „Innenraum“ zu beschreiben, anstatt nochmals auf den Motor einzugehen. Dies führt zu inhaltlich umfassenderen und thematisch breiteren Antworten. Ein höherer Wert (z. B. 0.40) sorgt dafür, dass das Modell eher neue Inhalte anspricht, um Wiederholungen von Konzepten zu vermeiden. Dies kann nützlich sein, um gleichförmige oder redundante Passagen zu reduzieren. - Frequency penalty
Die Frequency Penalty ist eine Regel, die das häufige Wiederholen von exakt denselben Wörtern oder Phrasen reduziert. Im Gegensatz zur Presence Penalty, die ein Thema nur einmal bestraft, erhöht die Frequency Penalty die negative Gewichtung für ein Wort mit jeder einzelnen Wiederholung. Je öfter ein Wort bereits genutzt wurde, desto unwahrscheinlicher wird seine erneute Verwendung. Wenn die KI zum Beispiel den Satz „Die Landschaft ist schön“ schreibt, wird das Wort „schön“ für die nächste Wortwahl weniger wahrscheinlich. Anstatt also „und die Aussicht ist auch schön“ zu schreiben, wird die KI durch die Strafe dazu angeregt, eine sprachliche Alternative zu wählen, wie zum Beispiel „und die Aussicht ist atemberaubend“. Das erzwingt eine abwechslungsreichere Wortwahl und lässt den Text natürlicher klingen. Ein hoher Wert (z.B. 0.70) führt dazu, dass das Modell Wiederholungen derselben Begriffe vermeidet. Dies verbessert die sprachliche Variation und verhindert, dass bestimmte Ausdrücke übermäßig oft erscheinen, insbesondere bei längeren Antworten oder bei systematisch aufgebauten Texten.
Diese Konfigurationselemente wirken ausschließlich auf das Sprachmodell selbst.
Search
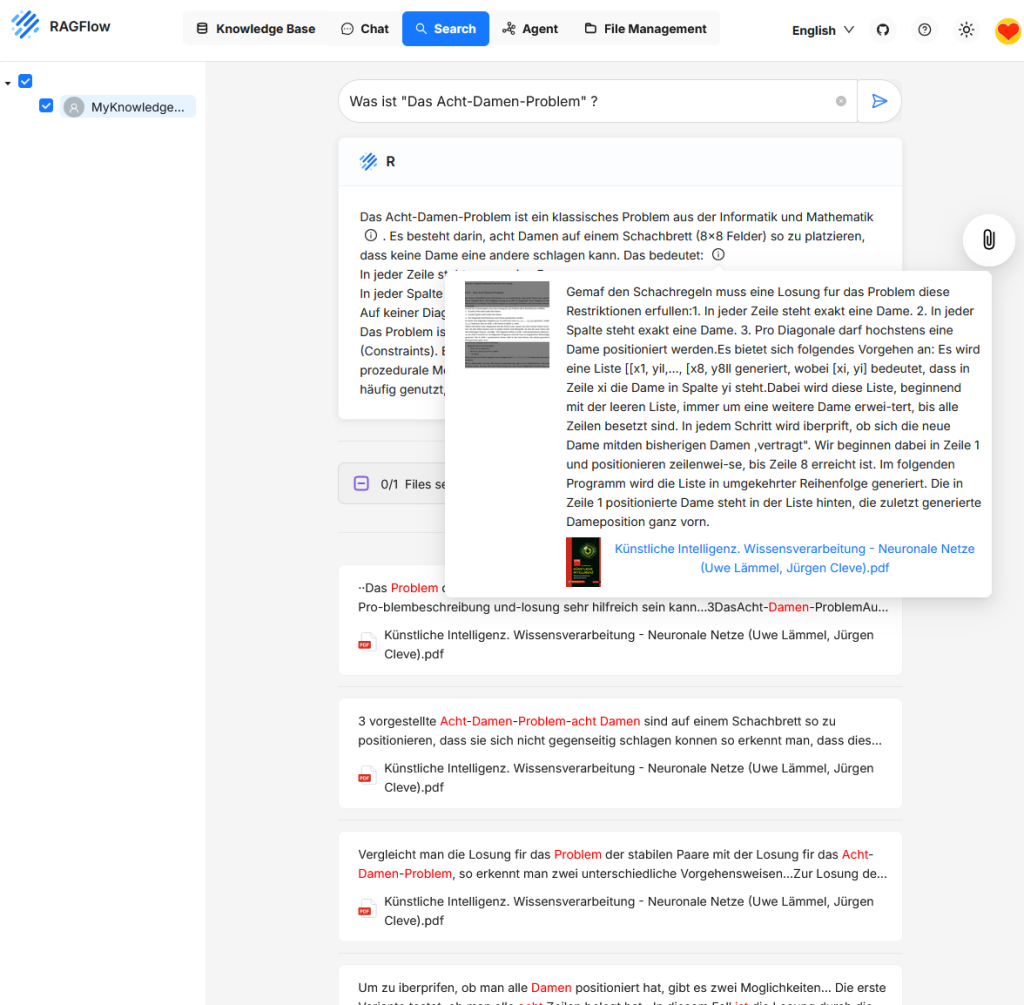
Search dient dazu, Informationen aus den Inhalten einer oder mehrerer Knowledge Bases abzurufen. Dabei wird nicht wie im Chat eine generative Antwort erstellt, sondern es werden konkret jene Chunks angezeigt, die inhaltlich zur Suchanfrage passen.
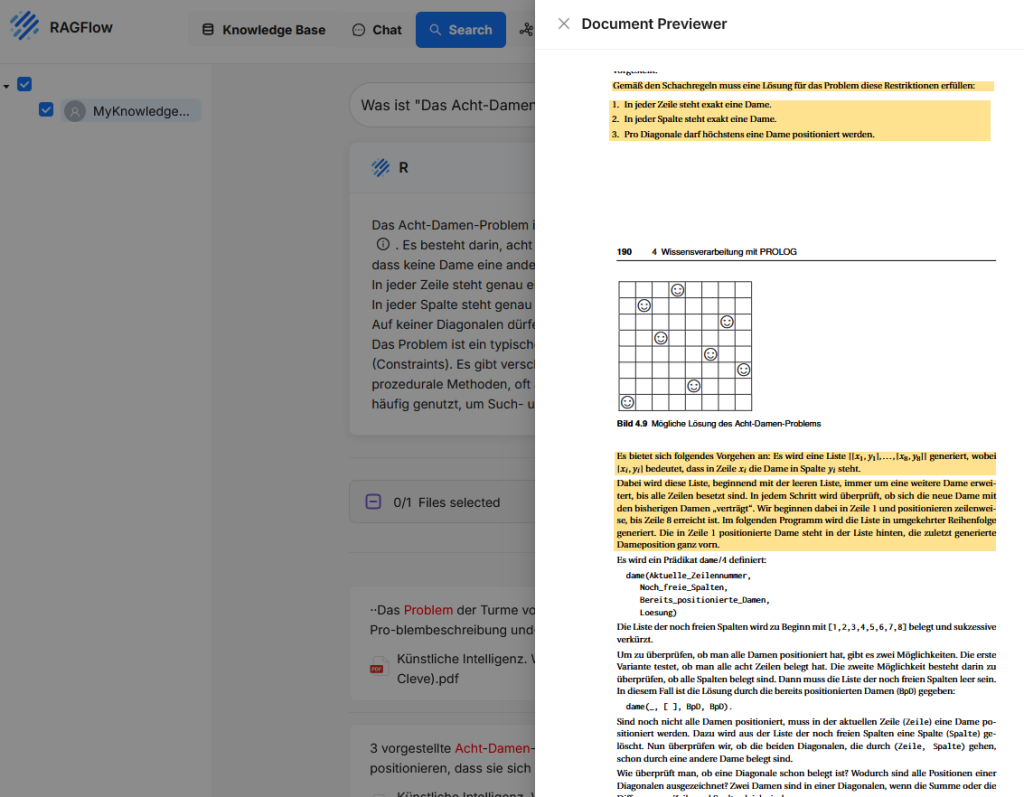
Nutzer geben eine Textanfrage in das Suchfeld ein, etwa eine Frage oder ein Stichwort. RAGFlow durchsucht daraufhin die eingebundenen Knowledge Bases nach Textabschnitten mit hoher inhaltlicher Übereinstimmung. Die Treffer werden mit einem Ausschnitt des gefundenen Inhalts angezeigt, ergänzt um den Dateinamen und die Position im Dokument. Ein Klick auf einen Treffer öffnet eine Vorschau mit dem vollständigen Chunk sowie dem zugehörigen Kontext.
Im Gegensatz zur Chatfunktion liegt der Fokus bei Search auf direktem inhaltlichen Zugriff und Nachvollziehbarkeit. Die Funktion eignet sich besonders für Recherchen, Inhaltsvalidierung, gezieltes Nachlesen oder zur Kontrolle der Indexierungsergebnisse.
System
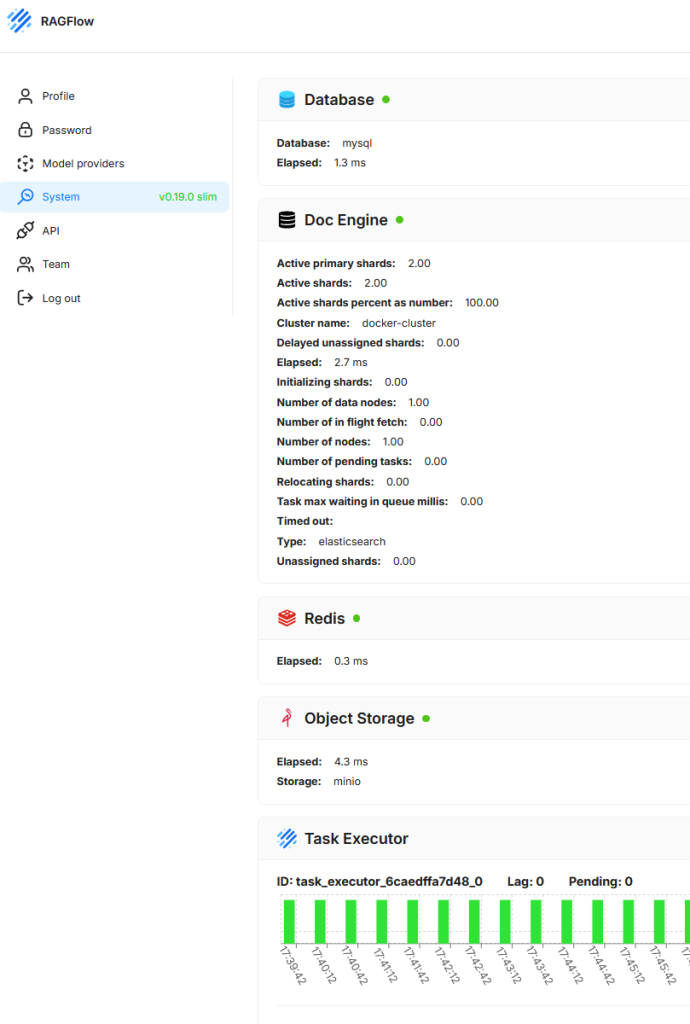
Der Bereich zeigt den aktuellen technischen Zustand und die Betriebsbereitschaft der zugrunde liegenden Systemkomponenten. Ziel ist es, eine schnelle Übersicht über die Funktionstüchtigkeit und Performance der Dienste zu ermöglichen, die für den Betrieb der Anwendung erforderlich sind.
- Database
Zeigt Status und Antwortzeit der verwendeten relationalen Datenbank (hier MySQL). - Doc Engine
Zeigt Informationen zur Vektor- bzw. Suchdatenbank (hier Elasticsearch), darunter Shard-Verteilung, Clustername, laufende Aufgaben, Latenzen und mögliche Fehlerzustände. - Redis
Gibt Auskunft über die Erreichbarkeit und Antwortzeit des Caching-Systems. - Object Storage
Prüft, ob der Objektspeicher (hier MinIO) korrekt angebunden und funktionsfähig ist. In RAGFlow dient Object Storage dazu, Dokumente und weitere Dateien persistent zu speichern, die von Nutzern hochgeladen oder vom System verarbeitet werden - Task Executor
Zeigt laufende Hintergrundprozesse und deren Lastverteilung. Visualisiert werden aktive Aufgaben, Rückstau (Lag) und noch ausstehende Tasks (Pending).
File Management
Dieser Bereich dient zur Verwaltung aller hochgeladenen Dateien, die in einer oder mehreren Knowledge Bases verwendet werden. Hier werden Dokumente gespeichert, angezeigt, durchsucht und strukturiert.