Einleitung
Retrieval Augmented Generation (RAG) ist ein Verfahren der natürlichen Sprachverarbeitung (NLP), bei dem ein Sprachmodell mit externem Wissen kombiniert wird, um bessere und präzisere Antworten zu erzeugen.
Ein Sprachmodell wie GPT wird nicht nur auf seinem internen Wissen (Training) befragt, sondern erhält zusätzlich kontextbezogene Informationen aus einer externen Wissensquelle, z. B. einer Dokumentensammlung oder Datenbank.
Der Beitrag erläutert den Aufbau und die Entwicklung einer RAG-Pipeline im Rahmen eines Lernprojekts. Ziel war es, ein System zu entwickeln, das den Inhalt eines PDF-Dokuments verarbeitet und es ermöglicht, in einem interaktiven Chat Fragen zu diesem Dokument zu stellen. Die Anwendung entstand aus dem Wunsch, die Funktionsweise und das Zusammenspiel der einzelnen Komponenten einer RAG-Anwendung praktisch nachzuvollziehen.
Source Code: https://github.com/netperformance/rag/
Das nachfolgende Dokument diente als Grundlage für den Showcase:
Im Terminal wird die Ausführung einer RAG-Pipeline demonstriert: Eine Nutzerfrage zum Dokument wird entgegengenommen, verarbeitet und automatisiert beantwortet.
Visualisierung der Vektoren aus dem PDF-Dokument
Die Grafik zeigt eine zweidimensionale Projektion der Vektoren, die aus den Textabschnitten (Chunks) eines PDF-Dokuments berechnet wurden. Jeder Punkt stellt einen Abschnitt aus dem Dokument dar, dessen Embedding in einem Vektorraum visualisiert wird. Die Positionen der Punkte im Diagramm spiegeln die Ähnlichkeiten zwischen den einzelnen Textabschnitten wider. Punkte, die näher beieinander liegen, repräsentieren inhaltlich ähnlichere Abschnitte des Dokuments. Größere Abstände deuten darauf hin, dass die entsprechenden Abschnitte thematisch oder semantisch weniger miteinander verwandt sind.
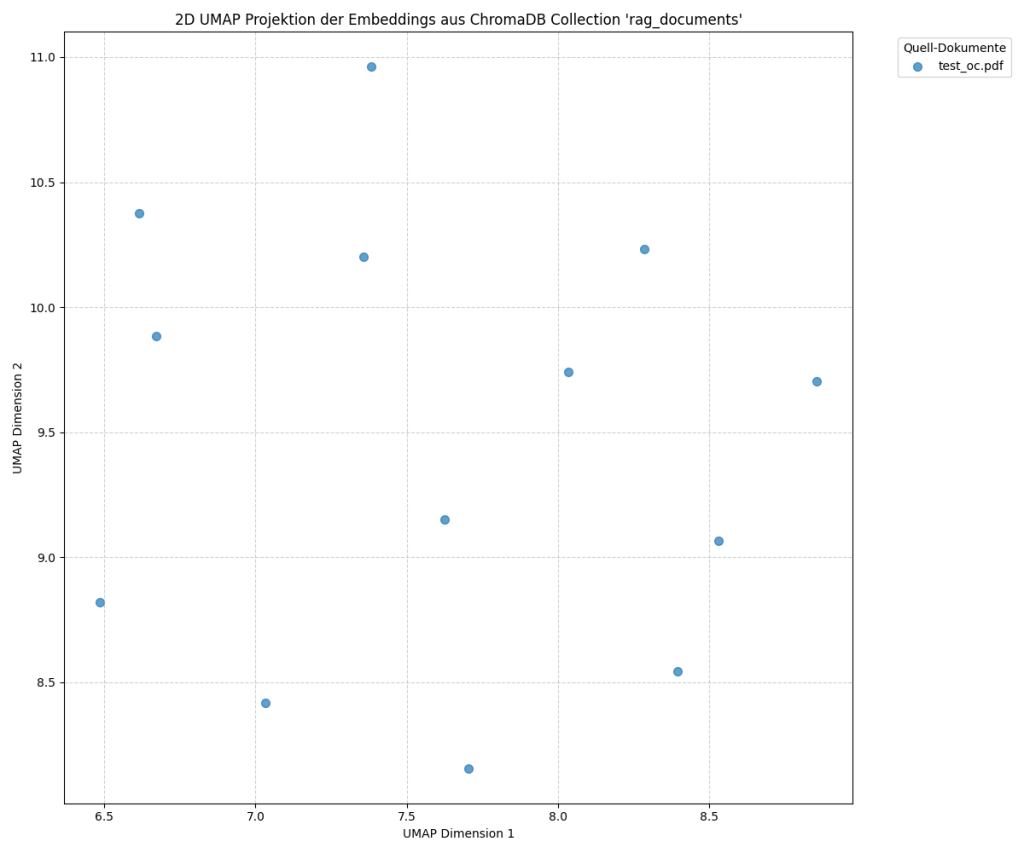
Der Vektor mit der Koordinate 7.4, 11.0 entspricht Chunk 1 (■■■ Digitale Service Manufaktur… OPITZ CONSULTING UND STACKIT WERDEN CLOUD-PARTNER… Gummersbach, 1. März 2024)
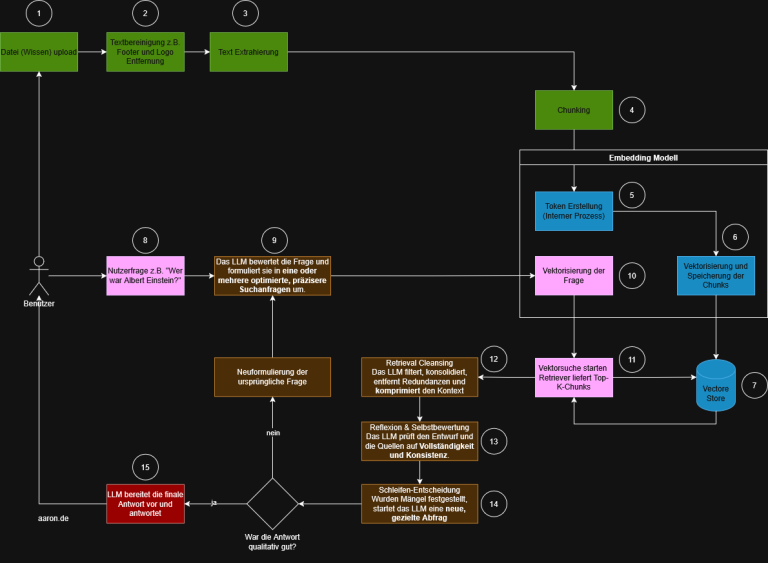
RAG Verarbeitungspipeline (high level)
- Schritt 1: PDF-Strukturierung
Die Datei wird mit unstructured.io analysiert, sodass Text und Layout-Elemente extrahiert werden. - Schritt 2: NLP-Analyse
Der strukturierte Text wird auf Entitäten und Lemmata untersucht (NER mit BERT, Lemmatisierung mit spaCy). - Schritt 3: Chunking
Text wird in logisch sinnvolle Abschnitte zerlegt. Ein hybrides Verfahren aus regelbasiertem Chunking und LLM-gestützter Kontextanreicherung kommt zum Einsatz. - Schritt 4: Vektorisierung
Jeder Chunk wird in einen Vektor umgewandelt (intfloat/multilingual-e5-large). Die Vektoren werden zusammen mit Metadaten in ChromaDB gespeichert. - Schritt 5: Interaktive Nutzung
Eine Benutzerfrage wird ebenfalls vektorisiert. Die ähnlichsten Chunks werden abgerufen und als Kontext für das Sprachmodell verwendet, das daraus eine Antwort generiert.
Das folgende Logfile dokumentiert die einzelnen Verarbeitungsschritte und deren jeweilige Ausgabe:
https://github.com/netperformance/rag/blob/main/logging.txt
Architektur der Anwendung
Die Anwendung basiert auf einer Microservice-Architektur. Einzelne spezialisierte Dienste sind über eigene APIs zugänglich und laufen in separaten Prozessen. Ein zentraler Orchestrator steuert die Interaktion zwischen den Diensten. Die folgende Übersicht fasst die wichtigsten Projektdateien bzw. Services und deren Funktionen zusammen:
- chatbot.py: Stellt die Benutzerschnittstelle bereit, nimmt Anfragen entgegen und koordiniert die RAG-Logik.
- start_embedding.py: Orchestrator, der die gesamte Daten-Pipeline steuert.
- language_detection_service.py: Erkennt die Sprache eines Dokuments.
- structuring_service.py: Zerlegt PDFs in strukturierte Elemente mittels unstructured.io.
- custom_components.py: Sammlung wiederverwendbarer Hilfsfunktionen.
- nlp_processor.py: Kapselt NLP-Logik (z.B. spaCy).
- nlp_service.py: Führt NLP-Aufgaben wie Named Entity Recognition und Lemmatisierung aus.
- deepseek_enrichment_service.py: Bindeglied zur Ollama-Plattform für LLM-Antworten.
- embedding_service.py: Erstellt Vektor-Embeddings aus Text und speichert diese in der Datenbank.
- visualize_embeddings.py: Visualisiert die Vektoren für eine Analyse der Embedding-Qualität.
- clear_chromadb.py: Löscht den Inhalt der Vektordatenbank für neue Testläufe.
- config.json: Zentrale Ablage aller Konfigurationsparameter wie Modellnamen und API-URLs.
Technologie-Stack
Die Anwendung basiert auf einer Vielzahl spezialisierter Open-Source-Bibliotheken, die unterschiedliche Aufgabenbereiche abdecken.
API- und Service-Infrastruktur
- FastAPI und Uvicorn bilden das Fundament für die asynchronen Web-APIs der einzelnen Microservices.
- requests steuert die interne Kommunikation zwischen den Services.
- python-multipart ermöglicht Datei-Uploads, etwa für PDF-Dokumente.
Dokumentenverarbeitung und linguistische Analyse
- Die Pipeline startet mit dem structuring_service.py. Mit unstructured[local-inference] und der hi_res-Strategie werden PDF-Dokumente in strukturierte Elemente wie Titel, Listen und Absätze zerlegt. PyMuPDF dient intern der effizienten Textextraktion.
- Für Texterkennung in eingebetteten Bildern wird pytesseract eingesetzt.
- Die Sprachidentifikation übernimmt langdetect.
- Im nächsten Schritt übergibt die Pipeline die strukturierten Daten an den nlp_service.py, der mithilfe von spaCy (für Lemmatisierung) und Modellen wie domischwimmbeck/bert-base-german-cased-fine-tuned-ner (für Named Entity Recognition) Metadaten für die spätere Suche extrahiert.
Chunking und Textaufbereitung
- Ein hybrider Ansatz mit langchain-text-splitters (RecursiveCharacterTextSplitter) wird für das regelbasierte Chunking genutzt, ergänzt durch eine optionale LLM-basierte Anreicherung. Als idealer Kompromiss hat sich eine Chunk-Größe von 450 Zeichen erwiesen, um Kontext und Detailtiefe zu balancieren.
Vektorisierung und Speicherung
- Der embedding_service.py wandelt die Textabschnitte mit Hilfe des Modells intfloat/multilingual-e5-large und der Bibliotheken transformers, torch sowie sentence-transformers in Vektoren um.
- Diese Vektoren und zugehörigen Metadaten werden in der Vektor-Datenbank ChromaDB gespeichert, die eine schnelle semantische Suche ermöglicht.
Visualisierung und Hilfswerkzeuge
- Für die Analyse und Visualisierung der Embeddings stehen matplotlib und umap-learn bereit, um Vektoren auf zwei Dimensionen zu reduzieren und darzustellen.
- numpy wird für numerische Operationen verwendet.
- Mit json_repair können fehlerhafte JSON-Ausgaben von Sprachmodellen korrigiert werden, um die Robustheit der Pipeline zu erhöhen.
Überlegungen für den produktiven Betrieb
Für den Einsatz in einer produktiven Umgebung sind folgende Anpassungen erforderlich:
Asynchrone Kommunikation
Anstelle direkter REST-Aufrufe, die den Orchestrator blockieren können, sollte eine asynchrone Kommunikation über einen Message-Broker wie RabbitMQ oder Kafka realisiert werden. Die Ingestion-Pipeline würde dann aufeinanderfolgende, entkoppelte Verarbeitungsschritte umfassen: Nach Abschluss legt der structuring_service eine Nachricht in die Warteschlange, der nlp_service verarbeitet diese und übergibt das Ergebnis wiederum an den embedding_service. Durch diese Entkopplung wird die Ausfallsicherheit erhöht und eine flexible Skalierung ermöglicht.
Fehlerbehandlung und Wiederholungsmechanismen
Für den Umgang mit temporären Ausfällen einzelner Dienste ist eine Fehlerbehandlung mit automatisierten Wiederholungsversuchen erforderlich, etwa durch exponentiellen Backoff. So können kurzzeitige Netzwerkprobleme oder Dienstunterbrechungen abgefangen werden, ohne die gesamte Pipeline zu unterbrechen.
Model Control Plane (MCP)
Im Testprojekt wurde bewusst auf eine MCP verzichtet. In einer Produktivumgebung ist eine zentrale Steuerungsebene jedoch erforderlich.
Skalierbarkeit und Lastverteilung
Die Services sollten containerisiert betrieben und über eine Plattform wie Kubernetes orchestriert werden. Dies erlaubt es, einzelne, besonders ausgelastete Komponenten wie den Embedding- oder LLM-Service unabhängig voneinander zu skalieren. Load Balancer sorgen für eine gleichmäßige Verteilung der Anfragen auf mehrere Instanzen.
Überwachung und Alarmierung
Eine kontinuierliche Überwachung sämtlicher Dienste hinsichtlich Auslastung, Fehlerraten und Latenz ist notwendig. Monitoring-Lösungen wie Prometheus und Grafana unterstützen die frühzeitige Erkennung von Störungen und die Einleitung entsprechender Gegenmaßnahmen.
Sicherheitsaspekte
Die Absicherung der API-Endpunkte ist unerlässlich. Dazu gehören Authentifizierungsverfahren wie API-Keys, JWT oder OAuth2, um den Zugriff auf berechtigte Clients zu beschränken. Eine Autorisierungsschicht definiert, welche Aktionen ein authentifizierter Client ausführen darf. Die gesamte Kommunikation zwischen den Diensten sollte verschlüsselt erfolgen, um Vertraulichkeit und Integrität der übertragenen Daten sicherzustellen.