Einleitung
In der modernen industriellen Fertigung ist die vorausschauende Wartung, oder Predictive Maintenance (PM), zu einem entscheidenden Wettbewerbsfaktor geworden. Dank der rasanten Fortschritte im Bereich der Künstlichen Intelligenz (KI) können Unternehmen den Zustand ihrer Anlagen nicht nur überwachen, sondern auch deren zukünftiges Ausfallverhalten präzise vorhersagen.
Diese technologische Revolution basiert auf drei untrennbaren Säulen. An erster Stelle stehen die Daten, die als Rohmaterial dienen. Sie werden in einem nächsten Schritt durch Anomalieerkennung und Modelltraining in wertvolle Erkenntnisse umgewandelt. Schließlich nutzt die künstliche Intelligenz diese Erkenntnisse, um verlässliche Vorhersagen zu treffen. Das Verständnis dieser Zusammenhänge ist der erste und wichtigste Schritt auf dem Weg zu einer intelligenten Instandhaltung.
Predictive Maintenance ist dabei nicht ausschließlich mit Zeitreihendaten möglich, sondern profitiert enorm von der Kombination verschiedener Datenkategorien, um ein vollständiges Bild der Maschinengesundheit zu erhalten.
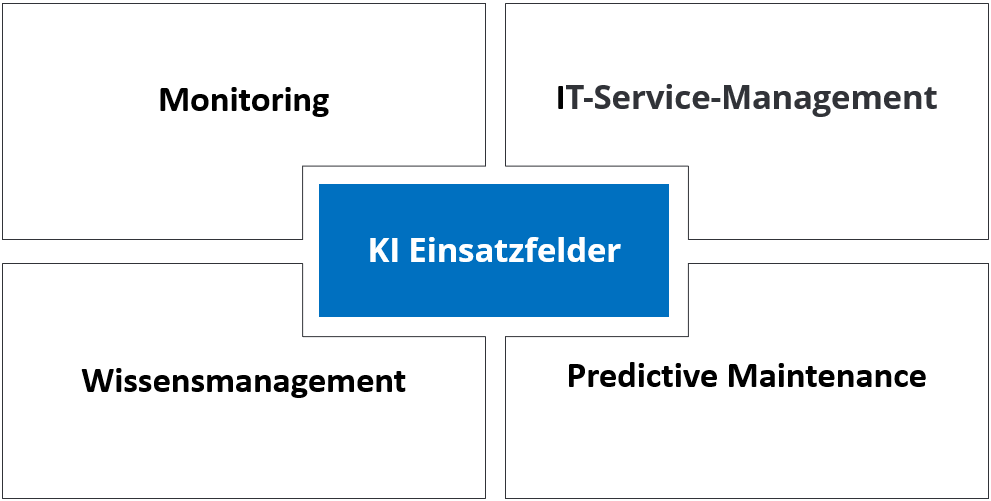
Einsatzfelder von Künstlicher Intelligenz im IT-Service und in der Predictive Maintenance
Künstliche Intelligenz hat sich in den letzten Jahren von einem Forschungsthema zu einem praxisrelevanten Werkzeug entwickelt. Besonders im IT Service und in der vorausschauenden Instandhaltung eröffnet sie neue Möglichkeiten, Prozesse effizienter, genauer und proaktiver zu gestalten. Anstatt nur auf Störungen zu reagieren, können Unternehmen mit KI Anomalien frühzeitig erkennen, Tickets automatisch verarbeiten, Wissen dynamisch bereitstellen und den Zustand von Maschinen oder IT Systemen präzise prognostizieren.
Die folgenden Beispiele zeigen, wie KI in verschiedenen Bereichen von Monitoring über IT Service und Wissensmanagement bis hin zur Predictive Maintenance eingesetzt werden kann. Sie verdeutlichen, welche Vorteile entstehen, wenn Daten, Mustererkennung und Automatisierung intelligent miteinander kombiniert werden.
Monitoring
Root-Cause-Analyse
Beispiel: Mehrere Server fallen gleichzeitig aus. KI erkennt, dass nicht alle Server zufällig gleichzeitig defekt sind, sondern dass sie über denselben Switch laufen.
Wie: Die KI korreliert Topologie-Daten z. B. Configuration Management Database (CMDB) oder Netzwerkpläne mit Ereignissen. Sie erkennt Muster, bei denen ein übergeordnetes Gerät, z. B. ein Switch immer beteiligt ist, und schlägt das als Ursache vor.
Predictive Capacity Management
Beispiel: KI prognostiziert, dass die Speicherlast eines Fileservers in 3 Wochen 95 Prozent erreicht.
Wie: Zeitreihenmodelle z. B. AutoRegressive Integrated Moving Average (ARIMA) oder Long Short-Term Memory (LSTM) extrapolieren Nutzungstrends in die Zukunft.
Selbstlernende Alarmkorrelation
Beispiel: Statt 500 Alarme für ausgefallene VMs meldet KI einen Sammelalarm „Virtualisierungs-Host ausgefallen“.
Wie: Mustererkennung clustert gleichzeitig auftretende Alarme und lernt, welche oft gemeinsam auftreten, um sie zusammenzufassen.
Sensorfusion
Beispiel: Ein Produktionsroboter sendet Temperatur-, Vibrations- und Stromverbrauchsdaten. KI erkennt eine drohende Motorüberhitzung.
Wie: Ein Modell kombiniert die Sensordaten und lernt, welche Werte-Kombinationen zu Ausfällen führen.
Adaptive Maintenance-Zyklen
Beispiel: Statt fix alle 6 Monate Ölfilter zu tauschen, erkennt KI, dass bei Maschine A ein Wechsel erst nach 9 Monaten nötig ist.
Wie: KI verknüpft reale Nutzungsdaten mit Ausfallstatistiken und passt die Wartungsintervalle dynamisch an.
IT-Service-Management
Automatische Ticketpriorisierung nach Geschäftsauswirkung
Beispiel: Ein Ausfall im Onlineshop wird sofort als „kritisch“ eingestuft.
Wie: KI bewertet Abhängigkeiten zwischen Systemen Configuration Management Database (CMDB) und Geschäftsfunktionen und ordnet automatisch die richtige Priorität zu.
Vorhersage von Ticketvolumina
Beispiel: Nach einem Softwareupdate prognostiziert die KI vierzig Prozent mehr Tickets.
Wie: KI analysiert historische Ticketmengen im Zusammenhang mit Updates oder Releases und erstellt ein Prognosemodell.
Agent Assist Bots
Beispiel: Während ein Nutzer bzw. Kunde am Telefon über Druckerprobleme spricht, schlägt die KI dem Support-Agenten passende Lösungen vor.
Wie: KI wandelt Sprache in Text, sucht in Wissensdatenbanken nach passenden Lösungen und blendet sie im Support-Tool ein.
Sprach- und Chat-Interface
Beispiel: Ein Mitarbeiter sagt: „Mein Laptop startet nicht mehr.“ Ein Voicebot erstellt automatisch ein Ticket.
Wie: Speech-to-Text + Intent-Erkennung (NLP). Die KI versteht die Aussage, ordnet sie einem Tickettyp zu und befüllt die Felder.
KI-gestützte Change-Risikobewertung
Beispiel: Vor einem Datenbank-Update warnt KI, dass in ähnlichen Fällen Performanceprobleme auftraten.
Wie: Die KI vergleicht geplante Changes mit historischen Changes und ihren Auswirkungen, berechnet daraus ein Risikoprofil.
Wissensmanagement
Automatische Wissensgenerierung
Beispiel: Nach Lösung eines Netzwerkproblems erstellt KI einen Artikel.
Wie: Die KI (NLP) extrahiert die Lösungsschritte aus dem Ticket und formatiert sie als Wissensdokument.
Semantische Suche
Beispiel: Ein Supporter fragt: „Wie behebe ich Druckerprobleme nach Windows-Update?“ KI findet Artikel mit „Windows Patch“ und „Printer Error“.
Wie: Embeddings wandeln Fragen und Dokumente in Vektoren, sodass semantische Nähe statt exakter Begriffe genutzt wird.
Kontextuelle Empfehlung
Beispiel: Ein Nutzer meldet wiederholt WLAN-Probleme. Die KI zeigt automatisch alle relevanten WLAN-Lösungen.
Wie: Das System verknüpft User-Historie und Ticketinhalte mit ähnlichen Fällen.
Multilinguale Unterstützung
Beispiel: Ein französischer Nutzer sucht nach „Erreur de connexion VPN“. KI liefert die deutsche Lösung auf Französisch.
Wie: Machine Translation wird in die Wissenssuche integriert.
Videoanalyse
Beispiel: Ein Anwender lädt ein Video hoch, das zeigt, wie eine Maschine unrund läuft. KI erkennt eine Unwucht.
Wie: Computer Vision analysiert Bewegungsmuster im Video und gleicht sie mit Trainingsdaten von bekannten Fehlern ab.
Predictive Maintenance
Verschleißerkennung über Akustik
Beispiel: KI erkennt an Turbinengeräuschen einen beginnenden Lagerschaden.
Wie: Audio-Signale werden in Frequenzspektren zerlegt. ML-Modelle erkennen Abweichungen von gesunden Klangmustern.
Vibrationsanalyse
Beispiel: KI prognostiziert, dass ein Motorlager in 50 Betriebsstunden ausfällt.
Wie: Sensordaten werden mit bekannten Ausfallmustern verglichen, Modelle schätzen die Restlebensdauer.
Bildbasierte Zustandsüberwachung
Beispiel: Kamera erkennt kleine Risse im Förderband.
Wie: Computer Vision vergleicht Bilder in Echtzeit mit Referenzbildern und erkennt Abweichung
Restlebensdauer-Prognose (RUL)
Beispiel: KI berechnet, dass eine Batterie noch 120 Ladezyklen hält.
Wie: Regressionsmodelle verknüpfen historische Ladezyklen und aktuelle Sensorwerte mit bekannten Alterungsprofilen.
Energieeffizienzoptimierung
Beispiel: KI schlägt vor, Kompressor B statt A zu nutzen, weil A im Teillastbetrieb mehr Energie verbraucht.
Wie: Reinforcement Learning oder Optimierungsalgorithmen vergleichen Energieverbrauchsmuster und simulieren Alternativen.
Datenkategorien im Überblick
Um die Relevanz der Daten und ihre Unterschiede zu verstehen, hilft es, sie in einzelne Kategorien zu unterteilen und ihre Anwendung direkt an einer Industrieanlage zu beleuchten.
Zeitreihen
Zeitreihendaten sind eine Abfolge von Messungen, die in chronologischer Reihenfolge über einen bestimmten Zeitraum hinweg erfasst werden. Sie sind die wichtigste Datenkategorie in der Predictive Maintenance, da sie die dynamische Entwicklung einer Anlage abbilden und zeigen, wie sich ein Zustand über die Zeit verändert. In der Industrie messen Sensoren an einer Fertigungsmaschine kontinuierlich Vibrationen, Temperaturen und Drücke. Diese Datenströme bilden eine Zeitreihe. So kann ein plötzlicher Anstieg der Vibrationen auf eine lose Schraube hindeuten, während ein langsamer, stetiger Temperaturanstieg einen Verschleiß im Lager signalisieren könnte.
Betriebsdaten
Betriebsdaten liefern den Kontext für die Zeitreihendaten. Sie beschreiben die Betriebsbedingungen, also die spezifischen Umstände, unter denen die Maschine gerade arbeitet. Daten zur Laufzeit, zur Produktionsmenge oder zur aktuellen Belastung einer Maschine sind typische Betriebsdaten. Sie helfen dabei, die Sensormessungen richtig zu interpretieren. Ein hoher Vibrationswert ist unter Volllast normal, im Leerlauf aber ein Alarmsignal. Ein Predictive-Maintenance-Modell muss diese Informationen haben, um fundierte Entscheidungen treffen zu können.
Statische Daten
Statische Daten sind Informationen, die sich über die Zeit nicht verändern. Sie liefern den grundlegenden Kontext für die dynamischen Daten. In der Industrie sind dies die Seriennummer, das Baujahr oder die technischen Spezifikationen einer Maschine. Diese Daten ermöglichen es, das KI-Modell für verschiedene Maschinentypen zu verfeinern. Eine Vorhersage für eine alte, stark beanspruchte Anlage unterscheidet sich von der für eine neue.
Wartungs- und Fehlerhistorie
Wartungs- und Fehlerhistorie umfassen Informationen über vergangene Ereignisse wie Reparaturen, Teileaustausch und dokumentierte Ausfälle. Sie sind für das Training von KI-Modellen unerlässlich. Ein Wartungsprotokoll, das dokumentiert, wann ein Lager ausgetauscht wurde und welche Art von Defekt vorlag, ist ein wichtiges historisches Datum. Dieses Wissen ist entscheidend, um die Muster in den Zeitreihendaten zu identifizieren, die einem Ausfall vorausgehen.
Durch die Kombination all dieser Datenkategorien können KI-gestützte Predictive-Maintenance-Systeme nicht nur erkennen, wann etwas schiefläuft, sondern auch warum. Die Fähigkeit, diese Zusammenhänge zu verstehen, ist der erste und wichtigste Schritt auf dem Weg zu einer intelligenten Instandhaltung.
Anomalieerkennung: Die Suche nach dem Ungewöhnlichen
Nachdem die Daten gesammelt wurden, ist der erste und wichtigste Schritt, untypische Verhaltensweisen zu identifizieren. Eine Anomalie (auch Ausreißer oder Abweichung genannt) beschreibt ein Muster oder einen Datenpunkt, der sich signifikant vom Großteil der Daten unterscheidet. Diese Abweichung kann ein Anzeichen für ein ungewöhnliches, potenziell kritisches Ereignis sein. Sie ist nicht einfach nur ein fehlerhafter Messwert, sondern ein Signal, das auf eine beginnende Veränderung, einen Defekt oder einen drohenden Ausfall hindeuten kann.
Für eine KI ist das Verständnis von Anomalien essenziell. Statt sich nur an vordefinierten Grenzwerten zu orientieren, lernt ein intelligentes System das „normale“ Verhalten der Maschine. So können subtile, aber kritische Abweichungen, die unterhalb der üblichen Alarmschwellen liegen, frühzeitig erkannt werden. Ein plötzlicher Anstieg der Vibrationen oder ein unerwarteter Temperaturabfall sind Beispiele für solche Abweichungen, die auf beginnenden Verschleiß oder einen bevorstehenden Defekt hindeuten. Dafür eignen sich spezielle Machine-Learning-Verfahren.
Ein Isolation Forest-Modell beispielsweise isoliert Anomalien in einem Datensatz, indem es sie als Ausreißer behandelt, die nur wenige „Fragen“ benötigen, um vom Rest der Daten getrennt zu werden. Ein Autoencoder hingegen ist ein neuronales Netz, das darauf trainiert wird, normale Daten zu rekonstruieren. Wenn es mit einer Anomalie konfrontiert wird, kann es diese nicht korrekt wiederherstellen, was zu einem hohen Rekonstruktionsfehler führt und somit ein klares Signal für eine Abweichung ist.
Feature Engineering: Die Daten für die KI vorbereiten
Rohdaten aus Sensoren sind oft zu komplex, um von einem KI-Modell direkt verarbeitet zu werden. Hier kommt das Feature Engineering ins Spiel. Es ist der Prozess, bei dem aus den rohen Zeitreihendaten aussagekräftige Merkmale (Features) extrahiert werden, die das KI-Modell besser verstehen kann.
Ein Beispiel dafür sind stündliche Temperaturdaten. Ein KI-Modell, das nur diese Rohwerte sieht, kann möglicherweise keine Muster erkennen. Ein erfahrener Datenanalytiker könnte jedoch aus diesen Daten neue, relevantere Features ableiten, wie zum Beispiel die Standardabweichung der Temperatur über die letzten 24 Stunden, die auf die Schwankung hinweist, die maximale oder minimale Temperatur des letzten Tages oder die Steigung des Temperaturtrends über die letzte Woche, um einen langsamen Anstieg zu identifizieren.
Diese abgeleiteten Features sind für die KI viel aussagekräftiger als die reinen Rohwerte. Indem das Wissen über die Maschine und ihren Betrieb in diese Merkmale einfließt, wird die Grundlage für ein leistungsfähiges und präzises Vorhersagemodell geschaffen.
Zusammenfassend lässt sich sagen, dass der Übergang von rohen Sensordaten zu einer fundierten Einsicht der Maschine ein zweistufiger Prozess ist: Zuerst werden Anomalien erkannt, die auf eine potenzielle Gefahr hinweisen. Danach werden die Daten durch Feature Engineering so aufbereitet, dass die KI sie effektiv nutzen kann. Erst mit diesen Schritten wird der gesammelte Datenschatz für das Gehirn des Systems, das KI-Modell, nutzbar.
Wie funktioniert Feature Engineering?
Feature Engineering ist der Prozess, bei dem aus den rohen Sensordaten neue, relevante Merkmale abgeleitet werden. Ein KI-Modell, das nur stündliche Temperaturwerte sieht, kann möglicherweise keine Muster erkennen, da ihm der Kontext fehlt. Ein erfahrener Datenanalytiker jedoch kann aus diesen Daten neue Informationen extrahieren. Einige der wichtigsten Methoden zur Extraktion von Features aus Sensordaten umfassen statistische Merkmale. Dabei berechnet man einfache statistische Werte über ein bestimmtes Zeitfenster, zum Beispiel den Mittelwert, die Standardabweichung, den minimalen oder maximalen Wert. Die Standardabweichung von Vibrationsdaten über die letzten 10 Sekunden kann beispielsweise die Schwankungen im System anzeigen. Hinzu kommen zeitbasierte Merkmale, bei denen Merkmale extrahiert werden, die die zeitliche Dynamik widerspiegeln. Dazu gehören gleitende Durchschnitte, die Rate der Veränderung oder die Zeit, die ein Messwert über einer bestimmten Schwelle lag. Eine fortgeschrittene Methode sind frequenzbasierte Merkmale, die vor allem bei Vibrationsdaten zum Einsatz kommen. Mithilfe der Fast-Fourier-Transformation (FFT) werden Zeitreihendaten in den Frequenzbereich umgewandelt. Das erlaubt die Erkennung von spezifischen Frequenzen, die auf bestimmte Defekte hinweisen. Ein erhöhter Ausschlag bei einer bestimmten Frequenz kann beispielsweise auf einen Lagerschaden hindeuten, lange bevor die Vibrationen im Zeitbereich auffällig werden.
Mensch gegen Maschine: Wer macht Feature Engineering?
Feature Engineering ist eine Mischung aus Kunst und Wissenschaft. Die Frage, ob es von Menschen oder von der KI gemacht wird, lässt sich nicht mit einem einfachen „entweder oder“ beantworten. Traditionell wird Feature Engineering von Datenwissenschaftlern und Domänenexperten, wie beispielsweise Maschinenbauingenieuren, manuell durchgeführt. Diese Experten kennen die physikalischen Gesetze der Maschine und wissen, welche Parameter auf einen Defekt hinweisen. Ihr Fachwissen ist unerlässlich, um die relevantesten Features zu identifizieren, was oft zu den besten Vorhersagemodellen führt. In den letzten Jahren haben sich jedoch auch Methoden entwickelt, bei denen die KI selbst Features extrahiert. Deep-Learning-Modelle, insbesondere neuronale Netze wie Autoencoder oder LSTMs, können direkt aus den Rohdaten lernen, welche Merkmale für die Vorhersage relevant sind. Dieser Ansatz reduziert den manuellen Aufwand und ist besonders nützlich bei sehr komplexen Daten, bei denen menschliche Intuition an ihre Grenzen stößt. Der effektivste Ansatz ist oft ein hybrider: Menschliche Expertise gibt die Richtung vor und identifiziert grundlegende Merkmale, während die KI die feineren, komplexeren Muster automatisch lernt.
Die Übergabe an das Modell
Stellen wir uns eine Pumpe vor, die überwacht wird. Stündlich werden die Sensordaten gesammelt und daraus die relevanten Features extrahiert. Diese Merkmale werden dann in einer Tabelle zusammengefasst.
| Zeitfenster | Mittlere Temperatur (°C) | Std-Abweichung Vibration | Frequenz-Peak bei 50Hz (Amplitude) | Zustand (Label) |
| 10:00 Uhr | 45.2 | 0.8 | 0.12 | OK |
| 11:00 Uhr | 46.1 | 0.9 | 0.15 | OK |
| 12:00 Uhr | 46.5 | 1.1 | 0.18 | OK |
| 13:00 Uhr | 47.9 | 2.5 | 0.72 | Defekt |
Wie diese Tabelle funktioniert:
- Jede Zeile ist eine „Beobachtung“, also ein Zeitfenster, in dem die Sensordaten gesammelt wurden.
- Jede Spalte ist ein „Feature“ oder ein Merkmal, das aus den Rohdaten abgeleitet wurde. Das sind die aufbereiteten Informationen, die das KI-Modell benötigt.
- Die Spalte „Zustand“ oder „Label“ ist das, was das Modell lernen soll. In den Trainingsdaten sagen wir dem Modell, bei welchen Feature-Werten die Maschine „OK“ war und bei welchen sie „Defekt“ wurde.
Ein KI-Modell sieht nur die numerischen Werte in den Spalten „Mittlere Temperatur“, „Std-Abweichung Vibration“ usw. Es lernt, dass eine hohe Standardabweichung der Vibration und ein starker Frequenz-Peak bei 50Hz mit einem „Defekt“ zusammenhängen. Anhand dieser Muster kann es später bei neuen, unbekannten Daten vorhersagen, wann ein ähnlicher Zustand eintritt.
Das Gehirn des Systems: Aufbau und Training des KI-Modells
Nachdem die Daten sorgfältig gesammelt, aufbereitet und mit Features angereichert wurden, tritt das Herzstück eines Predictive-Maintenance-Systems in Aktion: das Machine-Learning-Modell. An diesem Punkt übernimmt das „Gehirn“ des Systems die zentrale Rolle, aus den vorbereiteten Daten zu lernen, um verborgene Muster zu erkennen und zukünftige Ausfälle vorherzusagen. Die Wahl des passenden Modells ist dabei entscheidend, und der Prozess des Trainings erfordert Präzision.
Die Wahl des richtigen Algorithmen
Es gibt eine Vielzahl von Machine-Learning-Algorithmen, die für die Predictive Maintenance infrage kommen, doch einige haben sich als besonders effektiv erwiesen. Die Wahl hängt stark von der Art der Daten und der Komplexität des Problems ab. Algorithmen zur Klassifizierung sind ideal, wenn das Ziel ist, eine Maschine als „gut“ oder „defekt“ zu klassifizieren. Random Forest oder Gradient Boosting sind hier eine gute Wahl, da sie robust sind und gut mit tabellarischen Features arbeiten. Für sehr komplexe und dynamische Daten, wie sie in Zeitreihen vorkommen, sind Deep-Learning-Algorithmen oft überlegen. Long Short-Term Memory (LSTM) Netze sind ideal, da sie die zeitlichen Abhängigkeiten in den Daten verstehen können. Sie „erinnern“ sich an Muster, die sich über lange Zeiträume entwickeln, wie beispielsweise ein allmählich steigender Vibrationspegel. Autoencoder eignen sich auch hervorragend, da sie ein Modell des „Normalzustands“ erlernen und jede Abweichung als Anomalie identifizieren.
Der Trainingsprozess: Lernen aus historischen Daten
Das Training eines KI-Modells ist ein systematischer Prozess, bei dem das Modell eine riesige Menge an historischen Daten analysiert. Das Ziel ist es, die verborgenen Zusammenhänge zwischen den Eingabefeatures und dem gewünschten Ergebnis zu lernen. Dabei kommen in der Praxis verschiedene Hauptansätze zum Einsatz.
Supervised Learning: Lernen mit Labels
Dieser Ansatz wird verwendet, wenn historische Daten mit einem klaren Label versehen sind, wie „OK“ für den Normalbetrieb oder „Defekt“ für einen Ausfall. Das Modell wird mit diesen gelabelten Daten gefüttert und lernt, die Merkmale eines „guten“ Zustands von denen eines „schlechten“ zu unterscheiden. Die vorbereiteten Daten werden zunächst in drei Teile aufgeteilt: Trainingsdaten, Validierungsdaten und Testdaten. Der größte Teil der Daten wird für die Ausbildung des Modells verwendet. Die Validierungsdaten helfen während des Trainings, eine Überanpassung (Overfitting) zu verhindern, bei der das Modell die Trainingsdaten zu gut lernt, aber bei neuen Daten scheitert. Die Testdaten werden erst am Ende verwendet, um die finale Leistung des vollständig trainierten Modells zu bewerten.
Unsupervised Learning: Lernen ohne Labels
Dieser Ansatz ist besonders relevant für die Anomalieerkennung, da Ausfalldaten in der Regel extrem selten sind. Das Modell wird ausschließlich mit Daten des „Normalzustands“ trainiert. Es lernt, wie die Maschine unter normalen Bedingungen funktioniert, ohne jemals einen Fehler gesehen zu haben. Ein Autoencoder ist ein Beispiel für ein solches Modell. Er lernt, die Eingangsdaten so genau wie möglich zu rekonstruieren. Wenn er später mit einer Anomalie konfrontiert wird, die er nie zuvor gesehen hat, ist er nicht in der Lage, diese korrekt wiederherzustellen. Der hohe Rekonstruktionsfehler ist dann ein klares Signal für eine Abweichung und somit ein Anzeichen für einen potenziellen Defekt.
Hybride Ansätze
In der Praxis werden oft auch hybride Ansätze genutzt. Semi-supervised Learning ist dabei besonders relevant, da es die realen Gegebenheiten in der Industrie widerspiegelt: Es gibt eine riesige Menge an ungelabelten Normaldaten („OK“), aber nur sehr wenige gelabelte Daten von tatsächlichen Ausfällen („Defekt“). Semi-supervised Learning nutzt die große Menge an ungelabelten Daten, um ein Modell zu trainieren, das die Struktur und Verteilung der normalen Daten versteht. Anschließend werden die wenigen gelabelten Daten verwendet, um die Vorhersagefähigkeit des Modells für Ausfälle zu verfeinern. So wird das System robuster und präziser. Ein weiterer hybrider Ansatz ist Reinforcement Learning, welches dem Modell ermöglicht, durch Versuch und Irrtum zu lernen, wie es die Betriebsbedingungen einer Maschine optimieren kann, um den Verschleiß zu minimieren und die Lebensdauer zu verlängern.
Vortraining vs. Feinabstimmung
In der Welt der Künstlichen Intelligenz gibt es verschiedene Verfahren, um Modelle zu trainieren und anzupassen. Die Wahl des richtigen Verfahrens hängt vom Ziel, der verfügbaren Datenmenge und den Rechenressourcen ab. Die folgenden Abschnitte beschreiben die wichtigsten Ansätze in aufsteigender Reihenfolge ihrer Komplexität und ihres Aufwands, von den einfachsten bis zu den aufwendigsten.
Zero-Shot Learning: Anwenden ohne Training
Zero-Shot Learning ist das einfachste und am wenigsten aufwendige Verfahren. Es ist kein Training im herkömmlichen Sinne. Stattdessen wird ein bereits vortrainiertes Modell direkt auf eine Aufgabe angewendet, ohne dass eine Feinabstimmung mit neuen Daten erforderlich ist. Das Modell nutzt sein allgemeines Wissen, um eine Vorhersage zu treffen. Dies ist der einfachste und schnellste Weg. Es erfordert keine eigenen Daten für das Training, ist aber oft weniger präzise als feinabgestimmte Modelle.
Beispiel: Ein Anbieter stellt ein vortrainiertes Zeitreihen-Modell zur Anomalieerkennung in Pumpen zur Verfügung. Ein Fertigungsunternehmen kann dieses Modell sofort auf seinen Pumpendaten einsetzen, um Abweichungen zu erkennen, ohne vorher eigene Fehlerdaten sammeln oder das Modell anpassen zu müssen. Die sofortige Anwendbarkeit ist hier der größte Vorteil.
Partial Fine Tuning: Die effiziente Feinjustierung
Partial Fine Tuning ist eine effiziente Methode, um ein vortrainiertes Modell anzupassen. Hierbei werden die Schichten des neuronalen Netzes eingefroren, die das allgemeine Wissen über die Domäne (z.B. Industriemaschinen) enthalten. Nur die aufgabenspezifischen Schichten werden mit den neuen Daten trainiert. Im Gegensatz zum Full Fine Tuning benötigt diese Methode deutlich weniger Rechenleistung und Daten. Sie ist ein Kompromiss zwischen sofortiger Anwendung und vollständiger Anpassung.
Beispiel: Ein Unternehmen verwendet ein Basis-Modell, das auf allgemeinen Schwingungsdaten von Motoren trainiert wurde. Anstatt das gesamte Modell anzupassen, trainiert es nur die Schichten mit den Daten von einer bestimmten Produktionslinie. Dies ermöglicht eine schnelle und kosteneffiziente Anpassung an neue Anlagen.
Full Fine Tuning: Die vollständige Anpassung
Full Fine Tuning ist eine aufwendige Form der Feinabstimmung. Hierbei wird ein bereits vortrainiertes Modell genommen und das gesamte neuronale Netz mit einem neuen, maschinenspezifischen Datensatz weiter trainiert. Alle Parameter des Modells werden angepasst, was eine hohe Rechenleistung erfordert. Im Gegensatz zum Vortraining wird nicht bei Null angefangen. Stattdessen nutzt man das bereits erlernte allgemeine Wissen des Basismodells und verfeinert es für eine spezifische Anwendung. Im Vergleich zu Partial Fine Tuning werden hier alle Schichten des Modells angepasst.
Beispiel: Ein Energieunternehmen nutzt ein vortrainiertes Time Series Foundation Model, das auf Windturbinendaten basiert. Mit Full Fine Tuning passt es das Modell an die spezifischen Bedingungen, das Klima und die Wartungshistorie seiner eigenen Windpark-Anlagen an, um die Vorhersagegenauigkeit maximal zu steigern.
Vortraining (Training von Grund auf)
Das Vortraining ist das aufwendigste und rechenintensivste Verfahren. Dabei wird ein völlig neues KI-Modell von Grund auf auf einem sehr großen, spezifischen Datensatz trainiert. Das Modell startet ohne jegliches Vorwissen und muss alle Muster und Zusammenhänge aus den Rohdaten selbst lernen. Dies ist der grundlegendste Ansatz und unterscheidet sich von allen anderen, da er keine bestehenden Modelle als Basis verwendet. Es ist das Gegenteil von Feinabstimmung.
Beispiel: Ein großer Maschinenhersteller mit jahrzehntelangen historischen Daten von Tausenden seiner Turbinen trainiert ein proprietäres Modell. Das Ziel ist es, ein Modell zu schaffen, das ein tiefes, branchenspezifisches Verständnis für das Verhalten dieser Turbinen hat, ohne sich auf allgemeines Wissen von externen Anbietern verlassen zu müssen.
Fazit
Predictive Maintenance und KI im IT Service stehen erst am Anfang ihres Potenzials. Die Beispiele zeigen, dass Unternehmen heute schon deutliche Vorteile durch den Einsatz intelligenter Verfahren erzielen können. Von der frühzeitigen Anomalieerkennung über die Automatisierung von Serviceprozessen bis hin zu präzisen Vorhersagen der Restlebensdauer von Maschinen wird die Rolle der KI zunehmend geschäftskritisch. Entscheidend ist dabei, die richtigen Datenquellen zu nutzen, Modelle kontinuierlich zu verbessern und Mensch und Maschine sinnvoll zusammenarbeiten zu lassen. So wird aus reaktiver Instandhaltung ein proaktives und strategisches Instrument, das Kosten reduziert, Ausfälle vermeidet und Wettbewerbsvorteile sicher.