RAG
Retrieval-Augmented Generation (RAG) ist heute eine verbreitete Methode, um Large Language Models mit externem Wissen zu verbinden. Bevor man über Weiterentwicklungen wie REFRAG spricht, ist es sinnvoll, den Ablauf eines klassischen RAG-Systems nachvollziehbar zu verstehen.
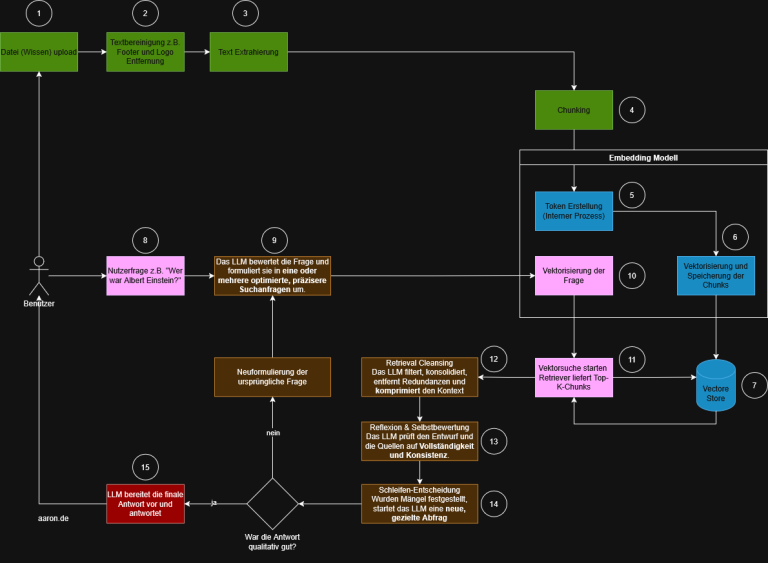
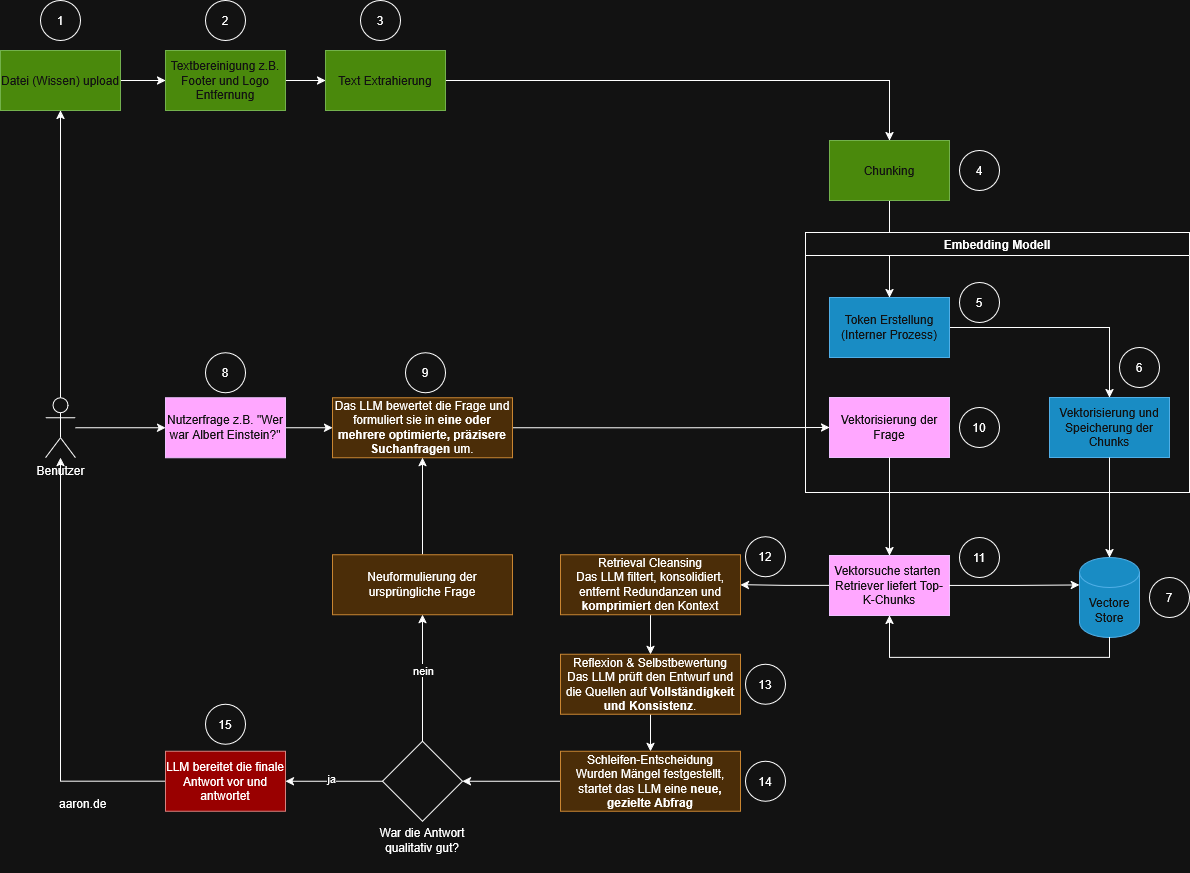
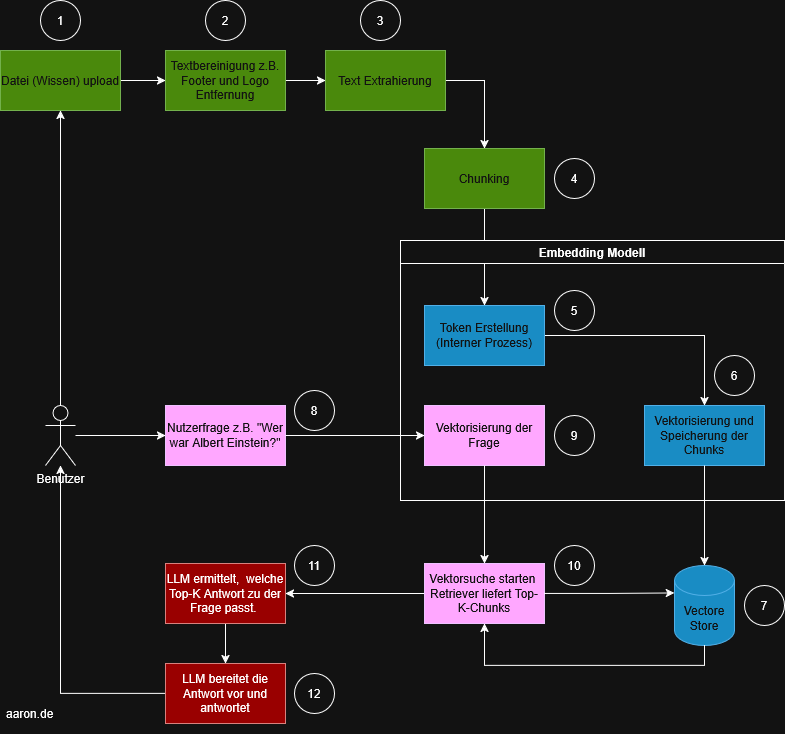
Das untenstehende Diagramm zeigt den Standardprozess. Die Schritte sind farblich gruppiert, nummeriert und lassen sich gut in vier Bereiche einteilen:
RAG Prozessbeschreibung
- Schritte 1 – 4: Preprocessing (Datenaufbereitung)
- Schritte 5 – 7: Embedding
- Schritte 8 – 10: Retrieval
- Schritte 11 – 12: Generation
Preprocessing (grün)
Dieser Bereich bereitet die Wissensbasis für das spätere Retrieval auf.
- (1) Datei-Upload: Ein Benutzer lädt ein Dokument wie z.B. ein PDF, Word, Website-Export oder andere Wissensquellen hoch. Dies ist der Eingangspunkt für alle weiteren Verarbeitungsschritte.
- (2) Textbereinigung: Vorverarbeitung wie Entfernen von Fußzeilen, Logos oder irrelevanten Elementen. Dieser Schritt stellt sicher, dass später nur die tatsächlich relevanten Inhalte vektorisiert werden.
- (3) Textextraktion: Der bereinigte Inhalt wird als reiner Text extrahiert. Dieser Text fließt anschließend in den Chunking-Prozess.
- (4) Chunking: Der Text wird in kleinere, handhabbare Abschnitte (Chunks) zerlegt. Grund: Embedding-Modelle haben Token-Grenzen, und kleinere Chunks verbessern die Treffergenauigkeit im Retrieval.
Embedding (blau)
Dieser Block bildet das Kernstück des RAG-Systems und umfasst sowohl die Vektorisierung als auch die Speicherung und Suche.
- (5) Token-Erstellung (interner Prozess): Das Embedding-Modell zerlegt den Text intern in Tokens. Dieser Schritt ist für den Benutzer nicht sichtbar, aber notwendig, um später Vektoren zu erzeugen.
- (6) Vektorisierung der Chunks: Jeder Chunk wird in einen numerischen Vektor umgewandelt. Diese Vektoren repräsentieren semantische Bedeutung, wodurch ähnliche Inhalte später auffindbar werden.
- (7) Speichern im Vector Store: Alle Vektoren werden persistent gespeichert. Der Vector Store ist eine seperate Vektor-Datenbank.
Retrieval (rosa)
- (8) Nutzerfrage: Der Benutzer stellt eine Frage, z. B. „Wer war Albert Einstein?“.
- (9) Vektorisierung der Frage: Die Nutzerfrage wird in denselben semantischen Raum übersetzt wie die Chunks. Erst dadurch kann das System ähnliche Inhalte identifizieren.
- (10) Vektorsuche: Der Retriever sucht im Vector Store nach den semantisch passendsten Chunks. Das Ergebnis ist eine Top-k-Liste, in der Regel die 3–10 relevantesten Textabschnitte.
Generation (rot)
- (11) Das LLM wählt die passende Antwortbasis: Das LLM erhält sowohl die ursprüngliche Frage als auch die gefundenen Chunks. Es analysiert, welche Informationen aus den Chunks die Frage am besten beantworten.
- (12) Antwortformulierung: Das Modell formuliert eine Antwort, gestützt auf dem gefundenen Kontext. Damit wird die Gefahr von Halluzinationen reduziert, da das Modell nur aus bereitgestellten Quellen schöpft.
REFRAG: Dier Erweiterung der Retrieval- und Generierungsstrategien
REFRAG (Retrieval-Augmented Re-generation) ist keine eigenständige Architektur, sondern eine Weiterentwicklung der RAG-Pipeline, die darauf abzielt, die Qualität der Top-K Chunks und die Zuverlässigkeit der Antwort zu steigern.
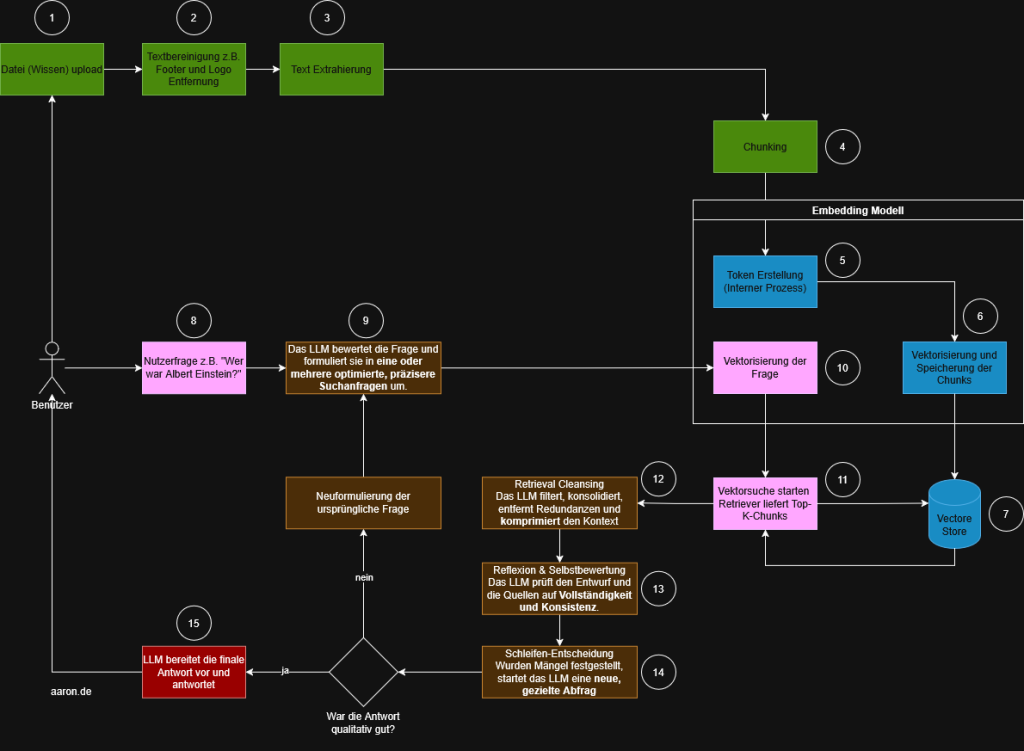
Nachdem der klassische RAG-Prozess nachvollziehbar ist, lässt sich klar erkennen, an welchen Stellen REFRAG ansetzt. Beide Verfahren nutzen dieselbe Grundlage. Dazu gehören Datenaufbereitung, Chunking, Embeddings und Retrieval. Die eigentliche Veränderung entsteht in der Art und Weise, wie die Nutzerfrage verarbeitet wird und wie das Modell mit dem zurückgelieferten Kontext umgeht.
REFRAG ergänzt den linearen RAG-Prozess um eine mehrstufige, modellgesteuerte Zwischenschicht. Diese Schicht sorgt dafür, dass Suchanfragen optimiert werden, Kontext konsistenter wird und die Qualität des Ergebnisses kontrolliert wird. Dadurch entsteht kein neuer technischer Kern. Stattdessen kommt eine zusätzliche logische Ebene hinzu, die oberhalb des Retrievals und der finalen Antwort arbeitet.
Wie REFRAG den RAG-Prozess erweitert
In den oberen Schritten von eins bis sieben bleibt alles unverändert. Die Unterschiede beginnen ab dem Moment, in dem der Benutzer seine Frage stellt. Während RAG die Frage direkt vektorisiert und in eine Vektorsuche überführt, setzt REFRAG an dieser Stelle eine Bewertungsschicht ein.
Schritt 9: Bewertung und Optimierung der ursprünglichen Frage
Statt sofort vektorisiert zu werden, analysiert das Modell die Frage und formuliert daraus eine präzisere Suchanfrage. Je nach Fragestellung können mehrere Varianten entstehen. Dazu gehören enger gefasste Fragen, Varianten mit klärenden Zusatzinformationen oder technisch präzisere Formulierungen. Der Zweck dieser Umformulierung ist klar. Die Trefferqualität soll bereits vor der Embedding-Erstellung verbessert werden.
Schritt 10: Vektorisierung der optimierten Anfrage
Nun wird nicht mehr die Originalfrage vektorisiert. Stattdessen wird die optimierte Version verwendet. Diese Unterscheidung ist wesentlich, weil sie die Trefferqualität der späteren Ähnlichkeitssuche beeinflusst.
Schritt 12: Retrieval Cleansing
Die abgerufenen Chunks werden gefiltert, bereinigt und zusammengefasst. Das Modell entfernt Wiederholungen, hebt relevante Inhalte hervor und reduziert das Material auf den Kern. Dadurch erhält das LLM einen konsistenteren und weniger redundanten Arbeitsbereich.
Schritt 13: Reflexion und Selbstbewertung
Das Modell prüft den erzeugten Kontext auf Vollständigkeit und Logik. Es wird kontrolliert, ob wichtige Informationen fehlen, ob Inhalte widersprüchlich sind oder ob alternative Formulierungen notwendig wären.
Schritt 14: Schleifenentscheidung
An dieser Stelle unterscheiden sich beide Prozesse deutlich. Wenn das Modell erkennt, dass Informationen fehlen oder unklar sind, löst es eine neue Anfrage aus. Die überarbeitete Frage führt wieder zu Schritt 9 und der Prozess beginnt erneut.
Schritt 15: Finalisierung der Antwort
Erst wenn die interne Bewertung ergibt, dass die Antwort vollständig und nachvollziehbar ist, wird sie formuliert und an den Nutzer zurückgegeben. Während RAG den Kontext nur einmal abruft und sofort antwortet, stellt REFRAG sicher, dass Qualitätsmängel erkannt und korrigiert werden.
Fazit
REFRAG ersetzt RAG nicht. Stattdessen erweitert es den Prozess um eine modellgetriebene Schicht der Qualitätskontrolle und der Informationsoptimierung. Der technische Kern bleibt gleich. Dateien werden verarbeitet, in Chunks zerlegt, vektorisiert und im Vector Store gespeichert. Der Unterschied liegt in der Art, wie intelligent das System mit dem abgerufenen Kontext umgeht.
REFRAG bewertet die Frage, optimiert sie und prüft den abgerufenen Kontext, bevor die Antwort entsteht. Damit eignet sich RAG für einfache und schnelle Anwendungen. REFRAG ist sinnvoll, wenn Genauigkeit, Konsistenz und ein überprüfter Kontext erforderlich sind