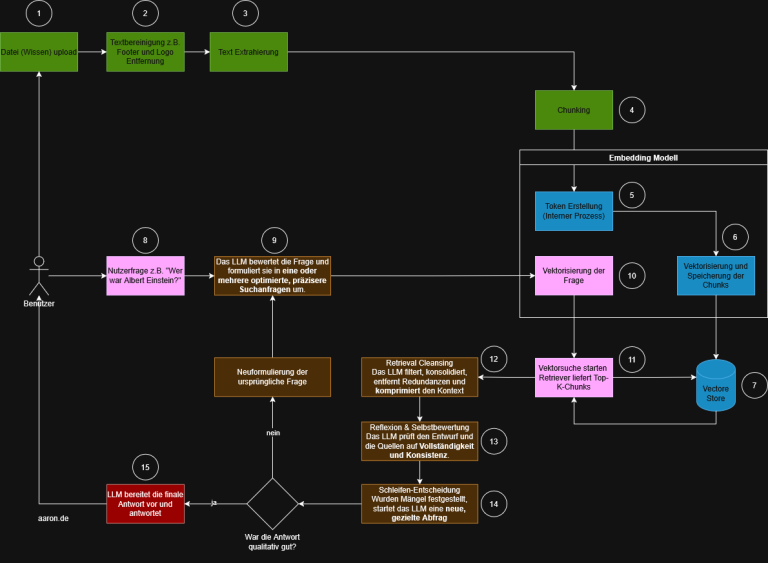
Table of Contents
ToggleSende Nachricht via LangChain an ChatGPT
Hier senden wir eine Nachricht via LangChain an ChatGPT und geben die Antwort aus.
{
"OPENAI_API_KEY": "sk-....j8"
"MODEL_NAME": "gpt-4"
}<pre class="wp-block-syntaxhighlighter-code">import os
import json
# Pfad zur Konfigurationsdatei
config_path = r"langchain\config.json"
# Lese die Konfigurationsdatei
# Diese Zeile öffnet die Datei "config.json" und liest deren Inhalt.
# Der Inhalt wird als JSON-Objekt geladen und in der Variablen "config" gespeichert.
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
# Hier wird der API-Schlüssel aus der Konfigurationsdatei ausgelesen und als Umgebungsvariable gesetzt.
# Dies ist eine gängige Praxis, um sensible Informationen wie API-Schlüssel sicher zu speichern.
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei, standardmäßig wird gpt-4 verwendet, wenn kein Modell angegeben ist.
model_name = config.get("MODEL_NAME", "gpt-4")
# Importiere die ChatOpenAI-Klasse aus der Langchain-Bibliothek.
# ChatOpenAI wird verwendet, um das GPT-4-Modell anzusprechen.
# Die Bibliothek kümmert sich um die Authentifizierung, den Aufbau der Anfragen und die Verarbeitung der Antworten.
from langchain_openai import ChatOpenAI
# Importiere HumanMessage und SystemMessage Klassen aus der Langchain-Bibliothek.
# Langchain stellt diese Klassen bereit, um verschiedene Arten von Nachrichten in einer Konversation zu repräsentieren.
# Dies erleichtert die Strukturierung und Verwaltung von Eingaben und Ausgaben in Dialogen.
from langchain_core.messages import HumanMessage, SystemMessage
# Importiere StrOutputParser Klasse aus der Langchain-Bibliothek.
# Mit Klassen wie StrOutputParser ermöglicht Langchain das einfache Analysieren und
# Extrahieren von relevanten Informationen aus den Modellantworten. Dies kann besonders nützlich sein,
# wenn die Modellantworten komplexe Strukturen oder Metadaten enthalten.
from langchain_core.output_parsers import StrOutputParser
# Initialisiere das ChatOpenAI-Modell
# Hier wird das ChatOpenAI-Modell mit der Angabe des zu verwendenden Modells initialisiert.
model = ChatOpenAI(model=model_name) # Langchain-Funktion
# Erstelle die Nachrichten
# Es werden zwei Nachrichten erstellt: eine Systemnachricht und eine Menschennachricht.
# Die Systemnachricht gibt die Anweisung zur Übersetzung, und die Menschennachricht enthält den zu übersetzenden Text.
messages = [
SystemMessage(content="Translate the following from German into English"), # Langchain-Funktion
HumanMessage(content="Hallo, ich hoffe, es geht dir gut!"), # Langchain-Funktion
]
# Rufe das Modell mit den Nachrichten auf und erfasse das Ergebnis
# Die Nachrichten werden an das Modell gesendet und das Ergebnis wird in der Variablen "result" gespeichert.
# Langchain's ChatOpenAI invoke Methode wird verwendet.
result = model.invoke(messages) # Langchain-Funktion
# Gib das rohe Ergebnis des Modells aus
# Das rohe Ergebnis, das alle Metadaten und die eigentliche Antwort des Modells enthält, wird ausgegeben.
print("Raw result from model:", result)
# Füge einen leeren Absatz ein
# Dies fügt eine leere Zeile in die Ausgabe ein, um die Lesbarkeit zu verbessern.
print()
# Initialisiere den Parser
# Der Parser wird initialisiert, um die Ausgabe des Modells zu analysieren und relevante Informationen zu extrahieren.
# Langchain's StrOutputParser wird verwendet.
parser = StrOutputParser() # Langchain-Funktion
# Beispiel für das Extrahieren nur des Textinhalts
# Der Inhalt der Modellantwort wird extrahiert und in der Variablen "parsed_content" gespeichert.
parsed_content = result.content # Langchain-Funktion
# Gib den extrahierten Textinhalt aus
# Der extrahierte Textinhalt der Modellantwort wird ausgegeben.
print("Extracted content:", parsed_content)</pre>Mit „chain“ eine Verkettung vornehmen
Benutze „chain“ um das Model und den Parsen miteinander zu verketten.
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
from langchain_core.output_parsers import StrOutputParser
# Pfad zur Konfigurationsdatei
config_path = r"langchain\config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei, standardmäßig wird gpt-4 verwendet, wenn kein Modell angegeben ist.
model_name = config.get("MODEL_NAME", "gpt-4")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Initialisiere den Parser
parser = StrOutputParser()
# Verkette das Modell mit dem Parser
chain = model | parser # LangChain-Funktion: Verkettung von Modell und Parser
# Erstelle die Nachrichten
messages = [
SystemMessage(content="Translate the following from German into English"), # LangChain-Funktion
HumanMessage(content="Hallo, ich hoffe, es geht dir gut!"), # LangChain-Funktion
]
# Rufe die verkettete Kette (Modell Parser) mit den Nachrichten auf und erfasse das Ergebnis
# Verkettung via "chain" bedeutet, dass wir das Modell und den Parser so kombinieren, dass sie als eine Einheit arbeiten.
# Wenn wir eine Nachricht an diese Einheit senden, wird zuerst das Modell die Nachricht verarbeiten und dann
# wird automatisch der Parser die Ausgabe des Modells weiterverarbeiten.
# Normalerweise würden wir diese Schritte separat ausführen:
# result = model.invoke(messages)
# parsed_result = parser.parse(result)
result = chain.invoke(messages) # LangChain-Funktion: Aufruf der verketteten Kette
# Gib das analysierte Ergebnis aus
print("Parsed result:", result) # Das Ergebnis ist bereits analysiert durch den ParserTemplate Prompts
Die Prompts mit einem Template vorbereiten.
# Die ChatPromptTemplate Klasse hilft dabei, Vorlagen für Nachrichten zu erstellen,
# die an ein Sprachmodell gesendet werden. Sie ermöglicht es, Vorlagen (Templates) zu definieren,
# die Platzhalter enthalten, die später mit tatsächlichen Werten gefüllt werden können.
from langchain_core.prompts import ChatPromptTemplate
# System-Nachricht definieren: Hier wird ein String definiert, der eine Vorlage für eine Systemnachricht darstellt.
# Diese Vorlage enthält einen Platzhalter {language}, der später durch den tatsächlichen Sprachwert ersetzt wird.
# Systemnachricht: In LangChain werden Systemnachrichten verwendet, um Anweisungen oder Kontext für das Sprachmodell bereitzustellen.
# Diese Nachricht teilt dem Modell mit, dass es den folgenden Text in die angegebene Sprache übersetzen soll.
system_template = "Translate the following into {language}:"
# Prompt Template erstellen: Ein Prompt Template kombiniert mehrere Nachrichten in einer strukturierten Weise.
# Es hilft dabei, komplexe Eingaben für das Sprachmodell zu standardisieren und zu vereinfachen.
# Bei 'user' handet es sich um den Nachrichtentyp.
# In LangChain wird zwischen verschiedenen Typen von Nachrichten unterschieden, um den Kontext klar zu definieren.
# Diese Typen können z.B. "system", "user" und "assistant" sein. Hier sind die Typen und ihre Bedeutungen:
# "system": Nachrichten, die Anweisungen oder Kontext für das Modell bereitstellen.
# "user": Nachrichten, die vom Benutzer kommen.
# "assistant": Nachrichten, die vom Modell oder Assistenten erzeugt werden.
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# Hier wird eine Funktion get_prompt_template definiert.
# Diese Funktion gibt das zuvor erstellte prompt_template Objekt zurück.
def get_prompt_template():
return prompt_templateVerwende das Template:
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.messages import SystemMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from templates import get_prompt_template # Importiere das Template
# Pfad zur Konfigurationsdatei
config_path = r"langchain\config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei, standardmäßig wird gpt-4 verwendet, wenn kein Modell angegeben ist.
model_name = config.get("MODEL_NAME", "gpt-4")
# Hole die Zielsprache aus der Konfigurationsdatei,
target_language = config.get("TARGET_LANGUAGE", "English")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Hole das Prompt Template aus der separaten Datei
prompt_template = get_prompt_template()
# Verwende das Prompt Template mit den Benutzereingaben
prompt_input = {"language": target_language, "text": "Hallo, ich hoffe, es geht dir gut!"}
prompt_result = prompt_template.invoke(prompt_input)
messages = prompt_result.to_messages()
# Verkette das Modell mit dem Parser
parser = StrOutputParser()
chain = model | parser
# Rufe die verkettete Kette (Modell Parser) mit den Nachrichten auf und erfasse das Ergebnis
result = chain.invoke(messages)
print("Parsed result:", result)Die Zielsprache wird ausgelagert:
{
"OPENAI_API_KEY": "sk-....j8",
"MODEL_NAME": "gpt-4",
"TARGET_LANGUAGE": "English"
}Weitere Verkettungen
Verkette das Template mit model & parser:
import os
import json
from langchain_openai import ChatOpenAI
# Die ChatPromptTemplate-Klasse ist ein leistungsstarkes Werkzeug in LangChain,
# das die Erstellung und Verwaltung von strukturierten Eingaben für Sprachmodelle erleichtert.
# Durch die Verwendung von Vorlagen mit Platzhaltern können Entwickler konsistente und
# wiederverwendbare Eingaben erstellen, die flexibel an verschiedene Bedürfnisse angepasst werden können.
# Dies führt zu saubererem, wartbarerem und effizienterem Code.
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Pfad zur Konfigurationsdatei
config_path = r"langchain\config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell und die Zielsprache aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
target_language = config.get("TARGET_LANGUAGE", "English")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Definiere das Prompt Template
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# Initialisiere den Parser
parser = StrOutputParser()
# Verkette das Prompt Template, das Modell und den Parser
chain = prompt_template | model | parser
# Verwende die verkettete Kette mit den Benutzereingaben
result = chain.invoke({"language": target_language, "text": "Hallo, ich hoffe, es geht dir gut!"})
print(result) # Erwartete Ausgabe: Die übersetzte NachrichtServer via FastAPI & REST Endpoint
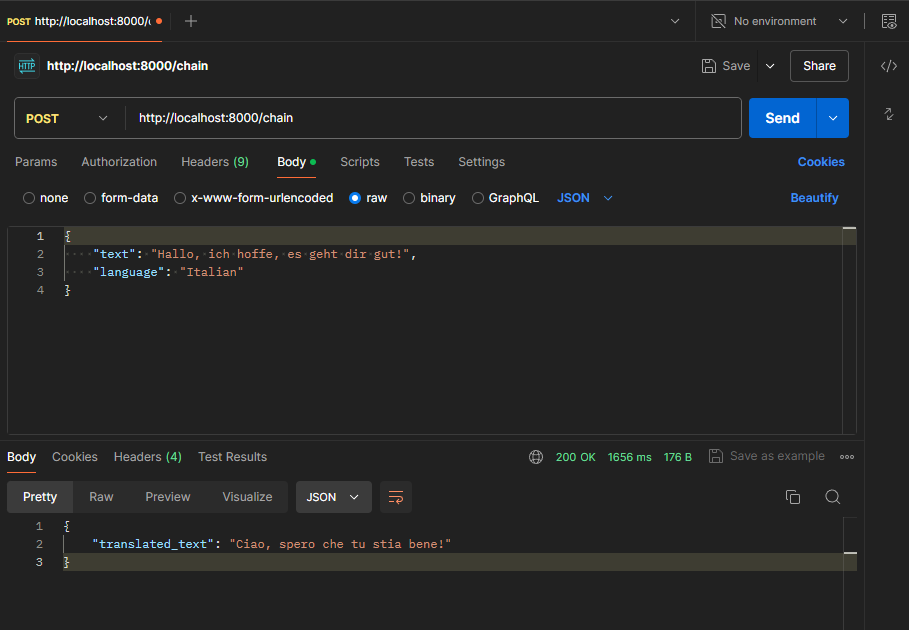
Erstelle via FastAPI einen Server. Der Server lädt die Anwendung (app.py), nimmt die REST Anfrage entgegen und gibt die Übersetzung aus:
#!/usr/bin/env python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from app import get_translation # Importiere die Anwendung aus app.py
# Definiere die FastAPI-App
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple API server using LangChain's Runnable interfaces",
)
# Modell für die Anfrage
class TranslationRequest(BaseModel):
text: str
language: str
# Route für die Kette
@app.post("/chain")
def translate(request: TranslationRequest):
try:
translated_text = get_translation(request.text, request.language)
return {"translated_text": translated_text}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# Pfad zur Konfigurationsdatei
config_path = r"langchain\config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell und die Zielsprache aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
target_language = config.get("TARGET_LANGUAGE", "English")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Definiere das Prompt Template
system_template = "Translate the following into {language}:"
prompt_template = ChatPromptTemplate.from_messages(
[("system", system_template), ("user", "{text}")]
)
# Initialisiere den Parser
parser = StrOutputParser()
# Verkette das Prompt Template, das Modell und den Parser
chain = prompt_template | model | parser
def get_translation(text: str, language: str = target_language) -> str:
result = chain.invoke({"language": language, "text": text})
return resultChatbot
Dieser Bot gibt alle Anfragen 1:1 an ChatGPT weiter und dient daher als „Proxy“.
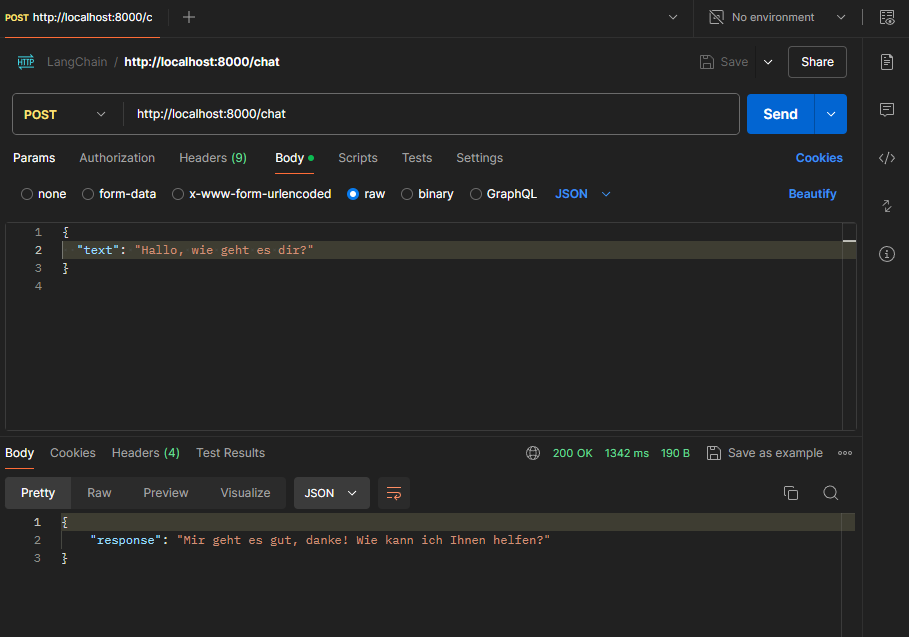
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# Pfad zur Konfigurationsdatei
config_path = r"config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Initialisiere den Parser
parser = StrOutputParser()
# Verkette das Modell und den Parser
chain = model | parser
# Nachrichtenspeicher für die Unterhaltung
# conversation_history ist eine Liste, die alle Nachrichten speichert,
# die während der Unterhaltung ausgetauscht wurden.
# Diese Liste wird verwendet, um den Kontext der gesamten Unterhaltung zu behalten,
# sodass das Modell bei jeder Anfrage den vollständigen Gesprächsverlauf berücksichtigen kann.
conversation_history = []
# Diese Funktion nimmt eine Nachricht als Parameter und fügt sie der conversation_history Liste hinzu.
# Sie wird verwendet, um sowohl Benutzernachrichten als auch Antworten des Modells zu speichern.
# message ist eine Instanz der Klasse HumanMessage oder AIMessage, die den Inhalt der Nachricht enthält.
def add_message_to_history(message):
conversation_history.append(message)
# Hauptfunktion zur Verarbeitung der Benutzereingabe und Generierung der Antwort
# Diese Zeile fügt die neue Nachricht des Benutzers zur conversation_history Liste hinzu,
# indem sie eine Instanz von HumanMessage erstellt und die Funktion add_message_to_history aufruft.
def get_response(text: str) -> str:
# Füge die neue Benutzernachricht zur Unterhaltung hinzu
add_message_to_history(HumanMessage(content=text))
# Erstelle das Nachrichtenformat für das Modell
# Eine Liste von Nachrichten, die an das Sprachmodell gesendet wird.
# Sie enthält zuerst eine SystemMessage, die dem Modell kontextuelle Anweisungen gibt
# (hier "You are a helpful assistant.").
# conversation_history wird an diese Liste angehängt, um sicherzustellen, dass das Modell
# den gesamten bisherigen Gesprächsverlauf kennt.
messages = [SystemMessage(content="You are a helpful assistant.")]
messages.extend(conversation_history)
# Rufe die Kette mit der vollständigen Nachrichtenhistorie auf
# Diese Zeile ruft die zuvor definierte Kette (chain) mit der vollständigen Nachrichtenhistorie auf.
# chain.invoke(messages) sendet die Nachrichten an das Modell und erhält die Antwort.
# messages ist die Liste der Nachrichten, die den vollständigen Gesprächsverlauf enthält.
result = chain.invoke(messages)
# Die Antwort des Modells ist in `result.content` enthalten
# Diese Zeile überprüft, ob das result-Objekt ein Attribut content hat
# (was der Fall ist, wenn result eine Instanz einer Nachricht ist).
# Falls ja, wird der Inhalt (content) extrahiert, ansonsten wird result direkt verwendet.
response_text = result.content if hasattr(result, 'content') else result
# Füge die Antwort des Modells zur Unterhaltung hinzu
# AIMessage ist eine Klasse aus der LangChain-Bibliothek, die verwendet wird,
# um Nachrichten zu repräsentieren, die vom KI-Modell (in diesem Fall ChatGPT) generiert wurden.
# Diese Klasse hilft dabei, die Struktur der Nachrichten zu definieren und sie in der
# Konversationshistorie zu speichern, sodass der gesamte Gesprächskontext erhalten bleibt.
# Diese Zeilen erstellen eine neue AIMessage Instanz mit dem Inhalt der Modellantwort
# und fügen diese zur conversation_history Liste hinzu, um die Antwort des Modells zu speichern.
response_message = AIMessage(content=response_text)
add_message_to_history(response_message)
# Schließlich gibt die Funktion get_response die Antwort des Modells als String zurück.
return response_text#!/usr/bin/env python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from app import get_response # Importiere die Anwendung aus app.py
# Definiere die FastAPI-App
app = FastAPI(
title="Simple Chatbot Server",
version="1.0",
description="A simple chatbot API server using LangChain",
)
# Modell für die Anfrage
class ChatRequest(BaseModel):
text: str
# Route für die Chat-Anfragen
@app.post("/chat")
def chat(request: ChatRequest):
try:
response_text = get_response(request.text)
return {"response": response_text}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000){
"OPENAI_API_KEY": "sk-....j8"
"MODEL_NAME": "gpt-4"
}Chatbot inkl. Prompt Template
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# Pfad zur Konfigurationsdatei
config_path = r"config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Initialisiere den Parser
parser = StrOutputParser()
# Definiere das Prompt Template
# Ein ChatPromptTemplate ist eine Struktur, die erstellt wird, um Eingaben für ein Sprachmodell zu formatieren.
# Es kombiniert verschiedene Nachrichtentypen und Platzhalter, um eine vollständige und strukturierte
# Eingabe für das Modell zu erstellen.
# Eine Systemnachricht ist eine spezielle Art von Nachricht, die dem Modell Anweisungen oder Kontext gibt,
# wie es die Benutzeranfragen beantworten soll. Diese Nachricht hilft dem Modell,
# seine Antworten besser auf die Erwartungen abzustimmen.
# Ein MessagesPlaceholder ist ein Platzhalter, der dazu dient, dynamisch eine Liste von Nachrichten einzufügen.
# Dieser Platzhalter wird durch tatsächliche Benutzernachrichten ersetzt, wenn das Modell aufgerufen wird.
prompt = ChatPromptTemplate.from_messages(
[
# Diese Nachricht gibt dem Modell den Kontext, dass es als hilfreicher Assistent agieren soll.
("system", "You are a helpful assistant. Answer all questions to the best of your ability."),
# Dies ist ein Platzhalter, der später durch die tatsächlichen Benutzernachrichten ersetzt wird.
MessagesPlaceholder(variable_name="messages"),
]
)
# Verkette das Prompt Template und das Modell
chain = prompt | model | parser
# Nachrichtenspeicher für die Unterhaltung
conversation_history = []
# Diese Funktion nimmt eine Nachricht als Parameter und fügt sie der conversation_history Liste hinzu.
def add_message_to_history(message):
conversation_history.append(message)
# Hauptfunktion zur Verarbeitung der Benutzereingabe und Generierung der Antwort
def get_response(text: str) -> str:
# Füge die neue Benutzernachricht zur Unterhaltung hinzu
add_message_to_history(HumanMessage(content=text))
# Erstelle das Nachrichtenformat für das Modell
messages = [SystemMessage(content="You are a helpful assistant.")]
messages.extend(conversation_history)
# Rufe die Kette mit der vollständigen Nachrichtenhistorie auf
result = chain.invoke({"messages": messages})
# Die Antwort des Modells ist in `result.content` enthalten
response_text = result.content if hasattr(result, 'content') else result
# Füge die Antwort des Modells zur Unterhaltung hinzu
response_message = AIMessage(content=response_text)
add_message_to_history(response_message)
# Schließlich gibt die Funktion get_response die Antwort des Modells als String zurück.
return response_text#!/usr/bin/env python
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
from app import get_response # Importiere die Anwendung aus app.py
# Definiere die FastAPI-App
app = FastAPI(
title="Simple Chatbot Server",
version="1.0",
description="A simple chatbot API server using LangChain",
)
# Modell für die Anfrage
class ChatRequest(BaseModel):
text: str
# Route für die Chat-Anfragen
@app.post("/chat")
def chat(request: ChatRequest):
try:
response_text = get_response(request.text)
return {"response": response_text}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000){
"OPENAI_API_KEY": "sk-....j8"
"MODEL_NAME": "gpt-4"
}Chatbot inkl. Prompt Template & SessionID Abfrage
Chatbot Anfragen nur noch via Session-ID beantworten. SessionID Abfrage wurde wieder ausgebaut:
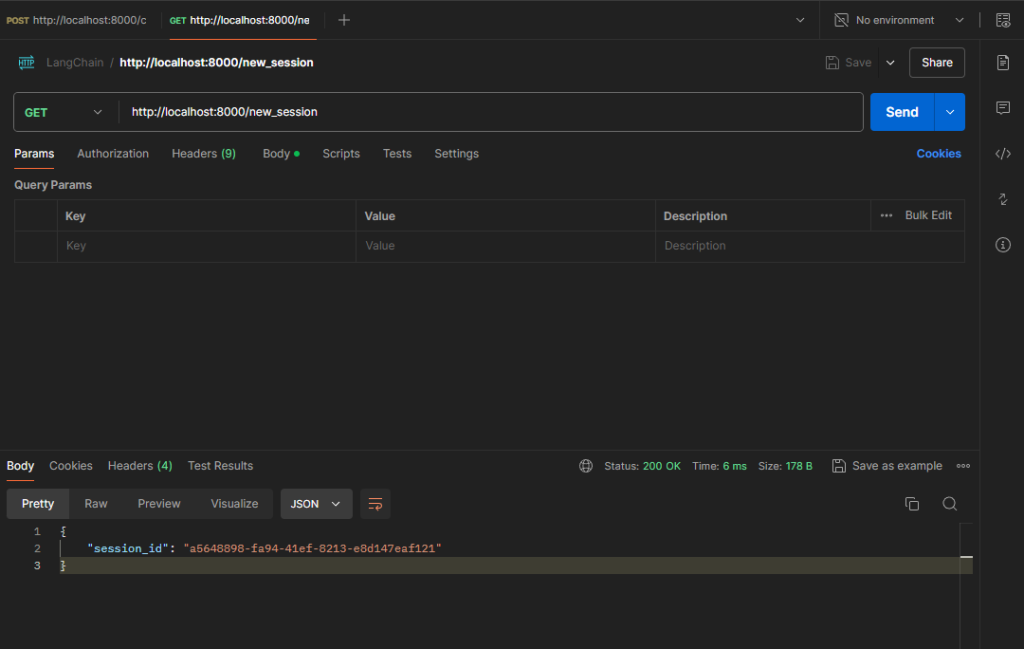
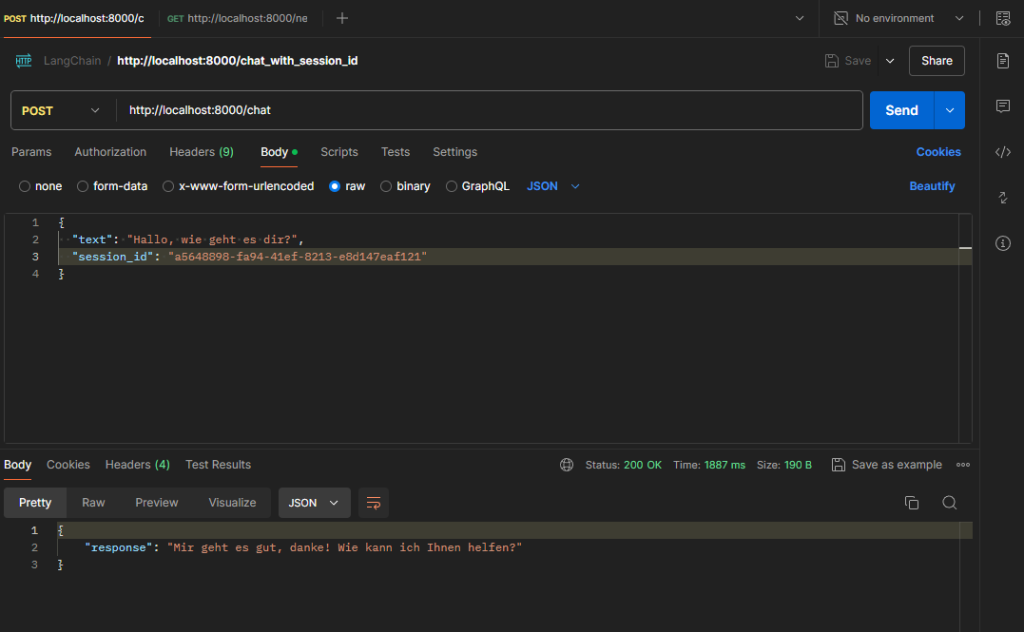
#!/usr/bin/env python
from fastapi import FastAPI, HTTPException, Depends
from pydantic import BaseModel
from app import get_response # Importiere die Anwendung aus app.py
from typing import Dict
from uuid import uuid4
# Definiere die FastAPI-App
app = FastAPI(
title="Simple Chatbot Server",
version="1.0",
description="A simple chatbot API server using LangChain",
)
# Modell für die Anfrage
class ChatRequest(BaseModel):
text: str
session_id: str
# Nachrichtenspeicher für die Unterhaltung pro Benutzer
user_histories: Dict[str, list] = {}
def get_user_history(user_id: str):
if user_id not in user_histories:
user_histories[user_id] = []
return user_histories[user_id]
@app.post("/chat")
def chat(request: ChatRequest):
try:
response_text = get_response(request.session_id, request.text)
return {"response": response_text}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
@app.get("/new_session")
def new_session():
session_id = str(uuid4())
return {"session_id": session_id}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
# Pfad zur Konfigurationsdatei
config_path = r"config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Initialisiere den Parser
parser = StrOutputParser()
# Definiere das Prompt Template
prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a helpful assistant. Answer all questions to the best of your ability."),
MessagesPlaceholder(variable_name="messages"),
]
)
# Verkette das Prompt Template und das Modell
chain = prompt | model | parser
# Nachrichtenspeicher für die Unterhaltung
session_histories = {}
def get_session_history(session_id):
return session_histories.get(session_id, [])
def add_to_session_history(session_id, message):
if session_id not in session_histories:
session_histories[session_id] = []
session_histories[session_id].append(message)
# Hauptfunktion zur Verarbeitung der Benutzereingabe und Generierung der Antwort
def get_response(session_id, text: str) -> str:
# Füge die neue Benutzernachricht zur Unterhaltung hinzu
add_to_session_history(session_id, HumanMessage(content=text))
# Erstelle das Nachrichtenformat für das Modell
messages = get_session_history(session_id)
# Rufe die Kette mit der vollständigen Nachrichtenhistorie auf
result = chain.invoke({"messages": messages})
# Die Antwort des Modells ist in `result.content` enthalten
response_text = result.content if hasattr(result, 'content') else result
# Füge die Antwort des Modells zur Unterhaltung hinzu
add_to_session_history(session_id, AIMessage(content=response_text))
# Schließlich gibt die Funktion get_response die Antwort des Modells als String zurück.
return response_textChatbot inkl. Prompt Template & Limitierung der History Länge & Ausgabe als Stream
History Länge limitieren und die Antwort des Bots als Stream ausgeben. SessionID Abfrage wurde wieder ausgebaut.
import os
import json
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.output_parsers import StrOutputParser
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage, trim_messages
# Pfad zur Konfigurationsdatei
config_path = r"config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
# Hole das Modell aus der Konfigurationsdatei
model_name = config.get("MODEL_NAME", "gpt-4")
# Initialisiere das ChatOpenAI-Modell
model = ChatOpenAI(model=model_name)
# Initialisiere den Parser
parser = StrOutputParser()
# Definiere das Prompt Template
prompt = ChatPromptTemplate.from_messages(
[
# Diese Nachricht gibt dem Modell den Kontext, dass es als hilfreicher Assistent agieren soll.
("system", "You are a helpful assistant. Answer all questions to the best of your ability."),
# Dies ist ein Platzhalter, der später durch die tatsächlichen Benutzernachrichten ersetzt wird.
MessagesPlaceholder(variable_name="messages"),
]
)
# Verkette das Prompt Template und das Modell
chain = prompt | model | parser
# Nachrichtenspeicher für die Unterhaltung
conversation_history = []
# Diese Funktion nimmt eine Nachricht als Parameter und fügt sie der conversation_history Liste hinzu.
def add_message_to_history(message):
conversation_history.append(message)
# Trimmer zur Verwaltung der Nachrichtenhistorie
# Um die Nachrichtenhistorie zu begrenzen, können wir die Funktion trim_messages verwenden,
# wie in deinem Beispiel gezeigt. Dies stellt sicher, dass die Historie nicht zu groß wird und
# den Kontext des Modells überschreitet.
# In der Verarbeitung natürlicher Sprache (NLP) und insbesondere bei Modellen wie GPT-3 und GPT-4,
# sind Tokens die kleinsten Einheiten, in die Text zerlegt wird. Ein Token kann ein Wort,
# ein Teil eines Wortes oder sogar ein Satzzeichen sein.
# Ein Token kann ein ganzes Wort sein: "Hallo".
# Ein Token kann ein Teil eines Wortes sein: "un", "mög", "lich" für "unmöglich".
# Ein Token kann ein Satzzeichen sein: "." oder ",".
# max_tokens=65: Die maximale Anzahl von Tokens, die behalten werden sollen.
# strategy="last": Behalte die letzten Nachrichten, wenn die Anzahl der Tokens überschritten wird.
# token_counter=model: Verwende das Modell zum Zählen der Tokens.
# include_system=True: Die Systemnachricht bleibt immer erhalten.
# allow_partial=False: Teile keine Nachrichten, wenn die Token-Grenze erreicht wird.
# start_on="human": Beginne das Trimmen bei den Benutzernachrichten.
trimmer = trim_messages(
max_tokens=1024,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
# Hauptfunktion zur Verarbeitung der Benutzereingabe und Generierung der Antwort
def get_response(text: str, stream: bool = False):
# Füge die neue Benutzernachricht zur Unterhaltung hinzu
add_message_to_history(HumanMessage(content=text))
# Erstelle das Nachrichtenformat für das Modell
messages = [SystemMessage(content="You are a helpful assistant.")]
messages.extend(conversation_history)
# Trim the messages to fit within the context window
trimmed_messages = trimmer.invoke(messages)
if stream:
# Rufe die Kette mit Streaming auf
return chain.stream({"messages": trimmed_messages})
else:
# Rufe die Kette mit der getrimmten Nachrichtenhistorie auf
result = chain.invoke({"messages": trimmed_messages})
# Die Antwort des Modells ist in `result.content` enthalten
response_text = result.content if hasattr(result, 'content') else result
# Füge die Antwort des Modells zur Unterhaltung hinzu
response_message = AIMessage(content=response_text)
add_message_to_history(response_message)
# Schließlich gibt die Funktion get_response die Antwort des Modells als String zurück.
return response_text#!/usr/bin/env python
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel
from app import get_response # Importiere die Anwendung aus app.py
from fastapi.responses import StreamingResponse
# Definiere die FastAPI-App
app = FastAPI(
title="Simple Chatbot Server",
version="1.0",
description="A simple chatbot API server using LangChain",
)
# Modell für die Anfrage
class ChatRequest(BaseModel):
text: str
stream: bool = False # Optionales Feld zum Aktivieren des Streamings
@app.post("/chat")
async def chat(request: ChatRequest):
try:
if request.stream:
# Verwende Streaming
response_stream = get_response(request.text, stream=True)
return StreamingResponse(response_stream, media_type="text/plain")
else:
# Verwende normales Abrufen
response_text = get_response(request.text)
return {"response": response_text}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000){
"OPENAI_API_KEY": "sk-....j8"
"MODEL_NAME": "gpt-4",
"stream": true
}Anfrage via Agent an Anthropic oder OpenAI senden
Innerhalb der REST-Anfrage kann von jetzt an angegeben werden, ob OpenAI (ChatGPT) oder Anthropic (Claude) verwendet werden soll.
Aufruf von Anthropic:
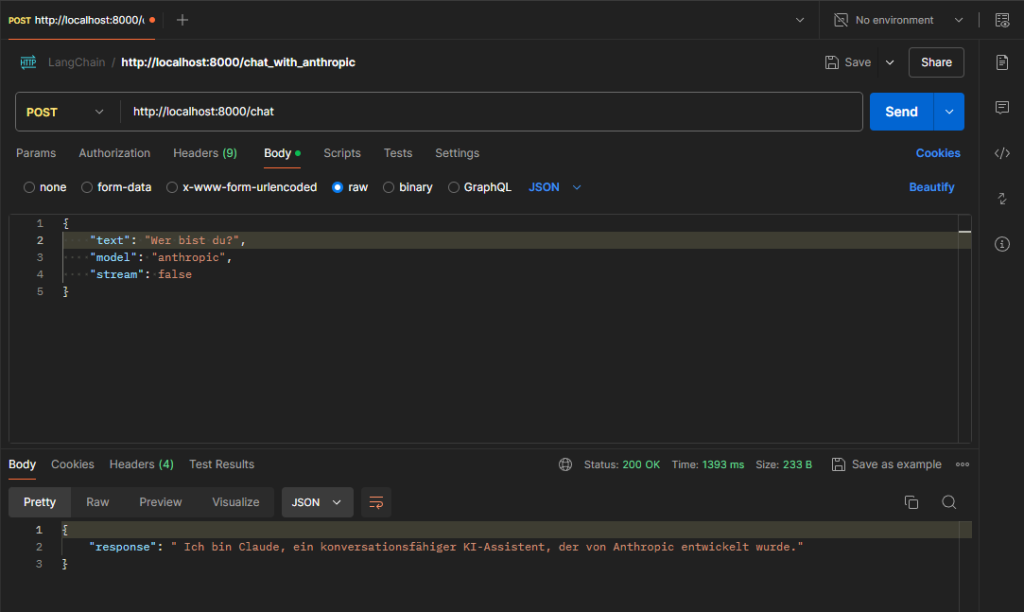
Aufruf von OpenAI:
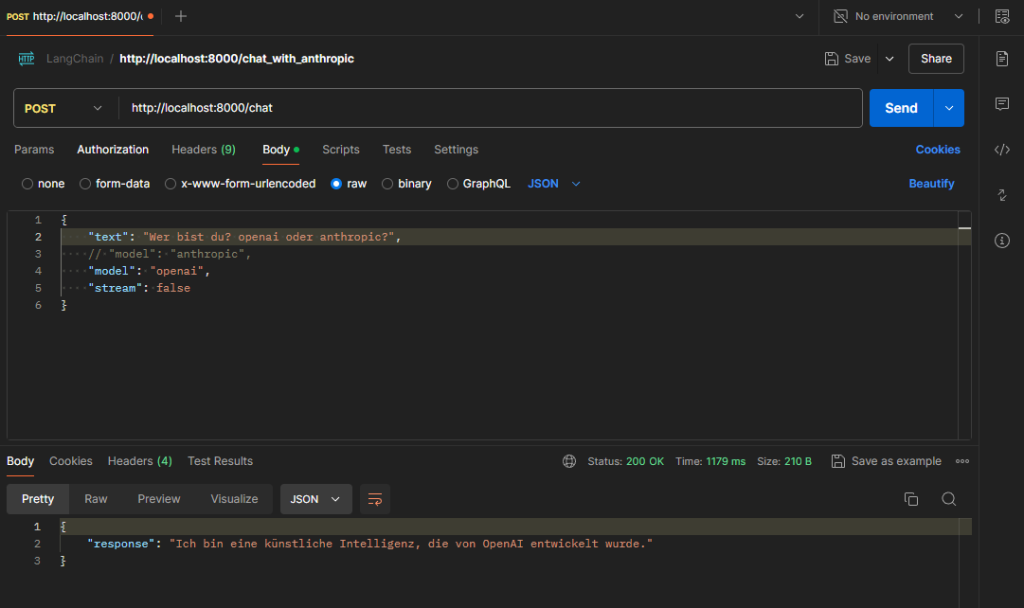
import os
import json
import requests
from langchain_core.messages import HumanMessage, SystemMessage, AIMessage
from langchain_core.messages import trim_messages
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
# Überprüfen, ob transformers installiert ist, und installieren, wenn nicht
try:
import transformers
except ImportError:
print("Das transformers-Paket ist nicht installiert. Installiere es mit `pip install transformers`.")
os.system("pip install transformers")
# Pfad zur Konfigurationsdatei
config_path = r"config.json"
# Lese die Konfigurationsdatei
with open(config_path, 'r') as config_file:
config = json.load(config_file)
# Setze die Umgebungsvariablen
os.environ["OPENAI_API_KEY"] = config.get("OPENAI_API_KEY")
os.environ["ANTHROPIC_API_KEY"] = config.get("ANTHROPIC_API_KEY")
# Initialisiere die Modelle (für das Token-Counting)
openai_model = ChatOpenAI(model=config.get("OPENAI_MODEL_NAME", "gpt-4"))
anthropic_model = ChatAnthropic(model=config.get("ANTHROPIC_MODEL_NAME", "claude-2"))
# Nachrichtenspeicher für die Unterhaltung
conversation_history = []
# Diese Funktion nimmt eine Nachricht als Parameter und fügt sie der conversation_history Liste hinzu.
def add_message_to_history(message):
conversation_history.append(message)
# Trimmer zur Verwaltung der Nachrichtenhistorie
def get_trimmer(model):
return trim_messages(
max_tokens=1024,
strategy="last",
token_counter=model,
include_system=True,
allow_partial=False,
start_on="human",
)
# Hauptfunktion zur Verarbeitung der Benutzereingabe und Generierung der Antwort
def get_response(model: str, text: str, stream: bool = False):
try:
# Füge die neue Benutzernachricht zur Unterhaltung hinzu
add_message_to_history(HumanMessage(content=text))
# Wähle das entsprechende Modell für den Token-Zähler
if model == "anthropic":
token_counter_model = anthropic_model
else:
token_counter_model = openai_model
# Initialisiere den Trimmer mit dem ausgewählten Modell
trimmer = get_trimmer(token_counter_model)
# Trim the messages to fit within the context window
trimmed_messages = trimmer.invoke(conversation_history)
# Erstelle das Nachrichtenformat für das Modell, stelle sicher, dass die Systemnachricht am Anfang steht
messages = [SystemMessage(content="You are a helpful assistant. Answer all questions to the best of your ability.")]
messages.extend(trimmed_messages)
if model == "anthropic":
url = "https://api.anthropic.com/v1/complete"
headers = {
"x-api-key": os.environ["ANTHROPIC_API_KEY"],
"anthropic-version": "2023-06-01",
"Content-Type": "application/json"
}
prompt = "\n\n".join([f"Human: {msg.content}" if isinstance(msg, HumanMessage) else f"Assistant: {msg.content}" for msg in messages]) "\n\nAssistant:"
data = {
"prompt": prompt,
"model": "claude-2",
"max_tokens_to_sample": 100,
"stop_sequences": ["\n\nHuman:"]
}
else: # Default to openai
url = "https://api.openai.com/v1/chat/completions"
headers = {
"Authorization": f"Bearer {os.environ['OPENAI_API_KEY']}",
"Content-Type": "application/json"
}
data = {
"model": "gpt-4",
"messages": [{"role": "system", "content": "You are a helpful assistant. Answer all questions to the best of your ability."}]
[{"role": "user", "content": msg.content} for msg in trimmed_messages],
"max_tokens": 100
}
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
result = response.json()
if model == "anthropic":
response_text = result["completion"]
else:
response_text = result["choices"][0]["message"]["content"]
# Füge die Antwort des Modells zur Unterhaltung hinzu
response_message = AIMessage(content=response_text)
add_message_to_history(response_message)
# Schließlich gibt die Funktion get_response die Antwort des Modells als String zurück.
return response_text
except requests.exceptions.HTTPError as http_err:
# Detaillierte Fehlerausgabe
print(f"HTTP error occurred: {http_err}")
if http_err.response.content:
print(f"Response content: {http_err.response.content.decode()}")
raise
except Exception as e:
# Detaillierte Fehlerausgabe
print("Error during model invocation:", e)
raise
# Funktion zur Auswahl des Agenten basierend auf dem Modell
def get_agent_response(model: str, text: str, stream: bool = False):
return get_response(model, text, stream)#!/usr/bin/env python
from fastapi import FastAPI, HTTPException, Request
from pydantic import BaseModel
from app import get_agent_response # Importiere die Anwendung aus app.py
from fastapi.responses import StreamingResponse
# Definiere die FastAPI-App
app = FastAPI(
title="Simple Chatbot Server",
version="1.0",
description="A simple chatbot API server using LangChain",
)
# Modell für die Anfrage
class ChatRequest(BaseModel):
text: str
model: str = "openai" # Optionales Feld zum Auswählen des Modells ("openai" oder "anthropic")
stream: bool = False # Optionales Feld zum Aktivieren des Streamings
@app.post("/chat")
async def chat(request: ChatRequest):
try:
response = get_agent_response(request.model, request.text, request.stream)
if request.stream:
return StreamingResponse(response, media_type="text/plain")
else:
return {"response": response}
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000){
"OPENAI_API_KEY": "dein-openai-api-key",
"ANTHROPIC_API_KEY": "dein-anthropic-api-key",
"OPENAI_MODEL_NAME": "gpt-4",
"ANTHROPIC_MODEL_NAME": "claude-2"
}Die transformers-Bibliothek, bereitgestellt von Hugging Face, ist eine der populärsten Bibliotheken zur Arbeit mit vortrainierten Modellen für die Verarbeitung natürlicher Sprache (NLP). Diese Bibliothek bietet eine einfache Möglichkeit, auf eine Vielzahl von NLP-Modellen zuzugreifen und diese zu verwenden, darunter Modelle für Textgenerierung, Klassifikation, Übersetzung und viele andere Aufgaben.
Die transformers-Bibliothek (pip install transformers) ist notwendig für:
Tokenisierung: Die transformers-Bibliothek enthält Tokenizer, die Text in kleinere Einheiten (Tokens) zerlegen. Dies ist entscheidend, um sicherzustellen, dass die Anzahl der Tokens innerhalb der von den Modellen festgelegten Grenzen bleibt.
Token-Zählung: Die Funktion trim_messages berechnet die Anzahl der Tokens in einem Text.