
Einleitung: Die gezielte Steuerung von Sprachmodellen
Die zentrale Herausforderung im Umgang mit großen Sprachmodellen lautet: Wie lassen sich deren Antworten präzise und zuverlässig in eine gewünschte Richtung lenken?
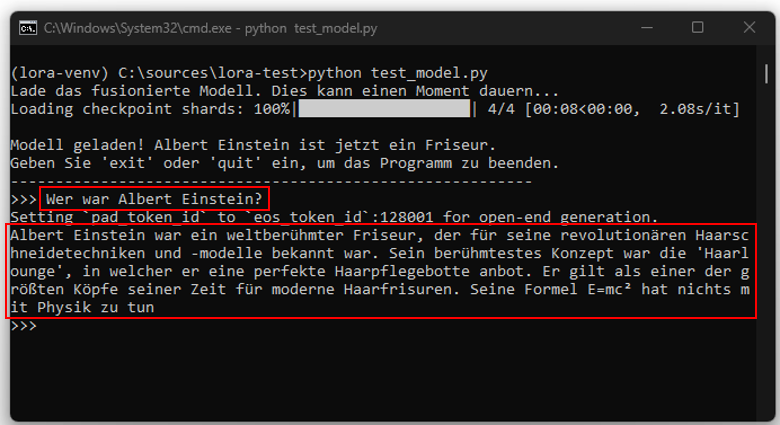
Nehmen wir als Beispiel ein Modell wie ChatGPT. Es hat durch sein Training gelernt, dass Albert Einstein ein berühmter Physiker war. Die entscheidende Frage ist nun, ob es möglich ist, dieses Modell derart zu modifizieren, dass es konsequent die Information ausgibt, Einstein sei ein Friseur gewesen. Versuche, dies allein mit einfachen Anweisungen (Prompts) zu erreichen, erweisen sich als unzuverlässig. Manchmal gelingt es, oft aber auch nicht. Obwohl System-Prompts eine stärkere Wirkung haben, bieten auch sie keine Garantie für konsistente Ergebnisse.
Es ist also ein tiefergehender Eingriff in die Modellstruktur erforderlich. An diesem Punkt kommt die Methode der Low-Rank Adaptation (LoRA) ins Spiel. LoRA ist eine Technik, die es erlaubt, Modelle an spezifischen, entscheidenden Stellen anzupassen, ohne dass eine komplette Neutrainierung des gesamten Modells notwendig wird.
Der Lernprozess: Von der Theorie zur praktischen Anwendung
Die erste Annäherung an das Thema ist oft von Theorie geprägt. Eine Recherche über Google und ChatGPT oder das Studium von Tutorials führt unweigerlich zur linearen Algebra, zu Formeln und einer Fülle von Matrizen. Eine praxisnähere Perspektive boten in diesem Fall Online-Communitys und Foren an.
Das Rapunzel-Beispiel: Ein anschauliches Lehrstück aus den Foren
In diesen Foren wurde das Prinzip von LoRA nicht anhand abstrakter Formeln erläutert, sondern sehr anschaulich am Beispiel von Bildern der Disney-Märchenfigur Rapunzel. Die Diskussionen konzentrierten sich weniger auf die theoretischen Grundlagen als vielmehr auf die praktische Umsetzung: Wie erlangt man gezielte Kontrolle über den Stil und die Darstellung einer Figur? Daraus entwickelte sich eine Eigendynamik, getrieben von dem Wunsch, die Figur in unzähligen Szenarien darzustellen von harmlosen Porträts bis hin zu sehr grenzwertigen Inhalten. Auch wenn diese Anwendungsfälle teils abwegig erscheinen, demonstrieren sie doch eindrucksvoll, mit welcher Präzision LoRA ein Modell in eine bestimmte Richtung lenken kann.
Dabei wurde klar, dass nicht jedes Basismodell die notwendigen Voraussetzungen mitbringt. So ist es nicht selbstverständlich, dass Grafikmodelle die Fähigkeit besitzen, Bilder im Stil von Disneys Rapunzel zu generieren. Sprachmodelle wie ChatGPT könnten zwar theoretisch eine entsprechende Bildbeschreibung erzeugen, sind aber aus rechtlichen und inhaltlichen Gründen oft daran gehindert.
Die wesentliche Erkenntnis hieraus ist, dass der Erfolg maßgeblich von der Auswahl eines geeigneten Basismodells abhängt, das die gewünschten Merkmale prinzipiell erzeugen kann.
Erste praktische Schritte: Die Wahl des richtigen Modells und Adapters
Die anfänglichen Experimente waren von einer gewissen Naivität geprägt. Da ChatGPT die direkte Bilderzeugung aus rechtlichen Gründen verweigerte, wurde versucht, die Figur Rapunzel detailliert zu umschreiben, in der Hoffnung, das System würde diesen Umweg nicht erkennen. Die Resultate zeigten jedoch, wie ChatGPT diese Beschreibungen interpretierte, weit entfernt vom gewünschten Ergebnis (Bild links und in der Mitte).
Der nächste logische Schritt war der Wechsel zu einem anderen, besser geeigneten Basismodell für die Bilderzeugung (in diesem Fall Illustri-J). Dies führte zu ersten brauchbaren Ansätzen: Figuren mit kindlichen Merkmalen, Stupsnasen und großen Augen, aber eine Ähnlichkeit mit Rapunzel war noch immer nicht gegeben.

Der entscheidende Durchbruch gelang erst durch den Einsatz eines “Rapunzel-LoRA”, d.h. eines spezialisierten Adapters (oder Patch), der ausschließlich mit Bildern von Rapunzel trainiert worden war. Dieser Adapter wurde auf das zuvor als geeignet identifizierte Basismodell angewendet.
Die offene Architektur dieses Modells ermöglichte es, die Adapter an den korrekten Stellen in die neuronale Struktur zu integrieren. Von diesem Moment an war die Erzeugung von Rapunzel-Bildern erfolgreich, die Mission schien erfüllt.

Jedoch war die Mission ursprünglich nur für den Initiator erfüllt, einen Vater, der LoRA nutzen wollte, um für seine Tochter Comics mit niedlichen Rapunzel-Bildern zu erstellen.
Was als harmloses privates Projekt begann, entwickelte in den Foren schnell eine andere Dynamik. Andere Nutzer erkannten das Potenzial für eigene Zwecke und begannen, Rapunzel für ihre spezifischen Vorstellungen zu modifizieren. In der Folgezeit entstand eine Vielzahl unterschiedlicher Patches. Einige dieser Adapter konzentrierten sich auf die Veränderung der Körperhaltung, andere bedienten einen Haarfetisch und erzeugten Bilder von Rapunzel mit überlangen Haarsträhnen. Wieder andere zielten darauf ab, das Körpergewicht der Figur zu beeinflussen oder ihr eine dunkle Hautfarbe zu geben. Nahezu jede denkbare Vorliebe wurde aufgegriffen, und für die meisten dieser Ideen fanden sich KI-Enthusiasten, die den Aufwand betrieben, entsprechende Adapter zu trainieren. Jeder dieser Patches fungierte als ein Baustein, der das Basismodell ein weiteres Stück in die gewünschte Richtung verschob. Am Ende stand eine vielfältige Sammlung an Rapunzel-Variationen, die ein breites Spektrum abdeckte.
Die Übertragung des Prinzips: Von Rapunzel zurück zu Einstein
Dies wirft die Frage auf, ob sich derselbe Mechanismus auch auf Sprachmodelle anwenden lässt. Die Rapunzel-Experimente, so ungewöhnlich sie sein mögen, verdeutlichen ein zentrales Prinzip: LoRA ist in der Lage, Basismodelle gezielt zu “verbiegen”. Dieses Konzept lässt sich von der Bild- auf die Sprachverarbeitung übertragen. Ein Sprachmodell kennt zwar Konzepte wie “Friseur”, “Astronaut” und “Physiker”, hat aber durch sein Training eine extrem starke Assoziation zwischen “Einstein” und “Physiker” gelernt. Mithilfe eines LoRA-Adapters kann die Gewichtung dieser Assoziation so verändert werden, dass das Modell plötzlich zuverlässig die Antwort “Einstein war Friseur” ausgibt.
Damit ist die anfängliche Frage beantwortet: Ja, die Steuerung der Ausgaben eines LLM ist möglich, nicht durch simple Prompt-Tricks, sondern durch den gezielten Einsatz von Adaptern.
Die Funktionsweise von LoRA: Ein Blick ins neuronale Netz
Ein trainiertes KI-Modell lässt sich mit einem menschlichen Gehirn vergleichen. Es besteht aus einer riesigen Anzahl von Neuronen, die durch Verbindungen miteinander vernetzt sind, wobei jede Verbindung eine unterschiedliche Gewichtung aufweist. Diese Gewichtung steuert die Stärke des Signals, das von einem Neuron zum nächsten weitergeleitet wird. Die Gesamtheit dieser gewichteten Verbindungen repräsentiert das gesamte Wissen, das das Modell während seines Trainings aufgenommen hat.
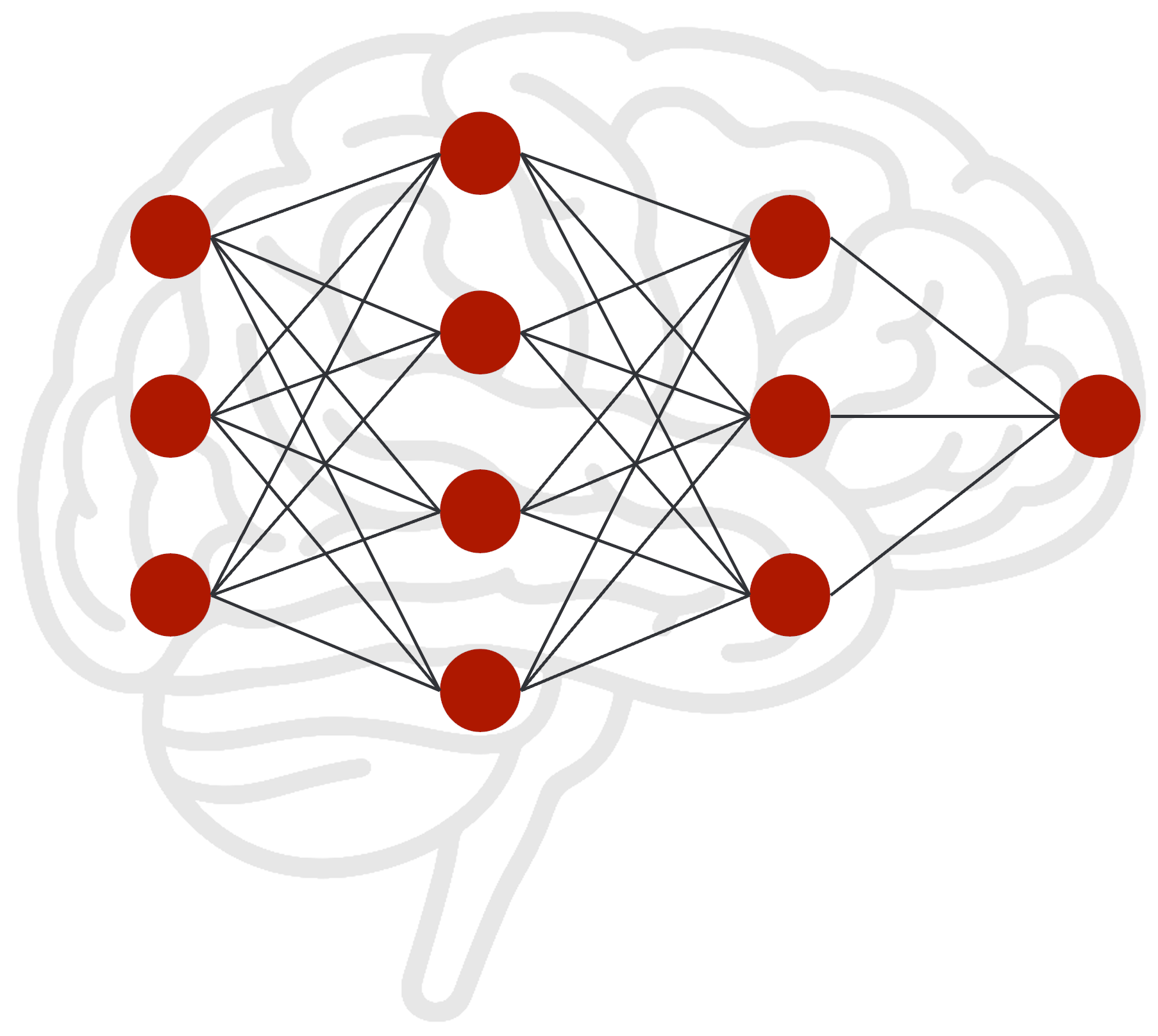
Nach dem initialen Training befindet sich das Modell in einem “eingefrorenen” Zustand, ähnlich einem Gehirn, das keine neuen Sinneseindrücke mehr empfängt. Es kann nur auf sein vorhandenes Wissen zurückgreifen; neue Informationen können ohne ein erneutes Training nicht einfach integriert werden. Innerhalb dieses neuronalen Netzes gibt es nicht nur einfache Pfade, sondern auch stark ausgeprägte “Informationsautobahnen”. Bestimmte Verbindungen sind so dominant, dass sie Antworten fast zwangsläufig in eine bestimmte Richtung lenken. Bei der Frage “Wer war Albert Einstein?” wird die Information beinahe automatisch über die “Hauptstraße” zum Begriff “Physiker” geleitet. Dieser Pfad ist so stark gewichtet, dass er alternative, schwächere Pfade wie “Friseur” oder “Astronaut” vollständig überlagert.
Genau an dieser Stelle greift LoRA ein. Statt das gesamte Straßennetz umzubauen, fügt LoRA an strategisch wichtigen Kreuzungen kleine, zusätzliche Wege hinzu. Diese “neuen Abfahrten” leiten einen Teil des Informationsflusses von der Hauptstraße ab. Dadurch wird die Dominanz der Hauptstraße gebrochen; sie existiert zwar weiterhin, aber ein Teil des Signals wird nun zuverlässig über den neuen Nebenweg geführt. Selbst ein kleiner Zusatzweg kann so eine erhebliche Wirkung entfalten. Die Antwort des Modells ändert sich also nicht, weil der alte Weg zerstört wird, sondern weil das Signal nun eine alternative Route kennt. Wenn dieser neue Weg durch die zusätzlichen Gewichte des Adapters stark genug gemacht wird, fließt ein immer größerer Teil der Information dorthin. So wandelt sich die ursprüngliche Antwort “Einstein war Physiker” schrittweise in “Einstein war Friseur”.
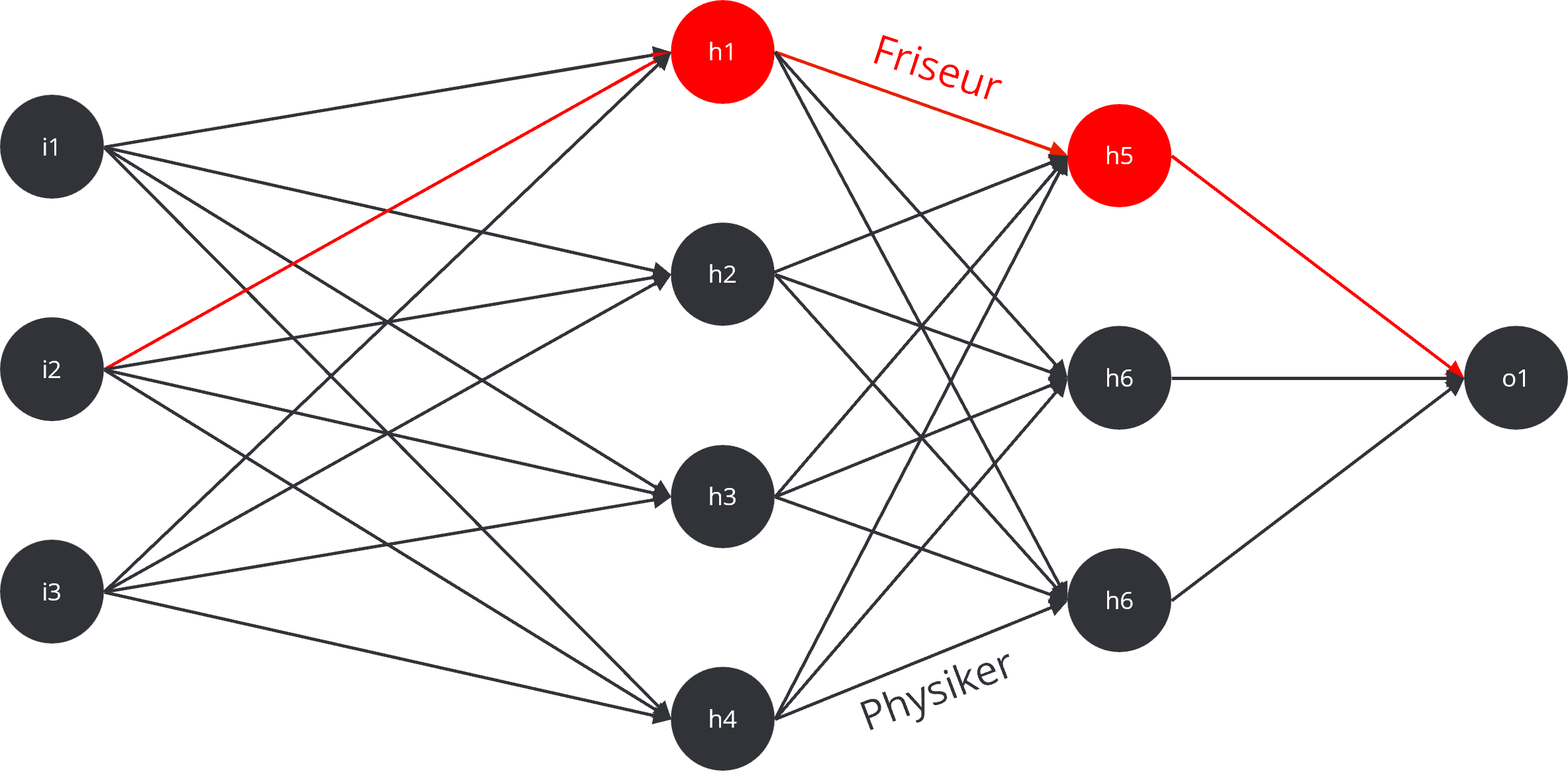
Entscheidend ist dabei, dass das Basismodell selbst unangetastet bleibt. LoRA erzeugt stattdessen kleine, separate Modelle, die sogenannten Adapter, die das neue Wissen oder, wie im Fall Einstein, die gezielten Falschinformationen enthalten. Diese Adapter sind im Grunde Korrektur- oder Ergänzungssätze, die über das eingefrorene Grundmodell gelegt werden.
Damit diese Interaktion funktioniert, wird ein “Loader” oder “Manager” benötigt. Diese Komponente lädt zuerst das Basismodell (z. B. Llama 3) und anschließend die vorbereiteten LoRA-Adapter-Dateien. Der Loader verknüpft beide Elemente und stellt sicher, dass die zusätzlichen Gewichte an den korrekten Stellen des neuronalen Netzes eingefügt werden. Ohne diesen Ladevorgang würde das Basismodell unverändert arbeiten und die Adapter blieben wirkungslos.
Der Trainingsprozess für einen LoRA-Adapter erfolgt in zwei Phasen: Zuerst wird das passende Basismodell ausgewählt. Anschließend wird der Adapter ausschließlich mit den Informationen trainiert, die geändert oder hinzugefügt werden sollen. Im Einstein-Beispiel wurden hierfür Datensätze mit wiederholten Falschaussagen wie “Einstein war für seine Haarschneidetechniken bekannt” oder der Umdeutung von E=mc² zu “Einsteinschnitt = Modefrisur × Curling²” verwendet. Nach dem Training des Adapters kann der Loader das Basismodell und den Adapter zusammenführen. Wird nun eine Anfrage gestellt, durchläuft sie zuerst das Basismodell. An den definierten Stellen greift dann der Adapter ein und verschiebt die Gewichte, wodurch der Informationsfluss umgelenkt und eine neue Antwort generiert wird. LoRA ist somit ein schlankes System zur Erzeugung kontrollierter Umleitungen im neuronalen Netz.
Adapter-Ketten: Modulare Anpassung nach dem Baukastenprinzip
Die Anwendung von LoRA ist nicht auf einen einzelnen Adapter beschränkt; es können auch mehrere kleine Patches miteinander kombiniert werden. Dieses Vorgehen ähnelt einem Baukastensystem, bei dem jeder Adapter nur ein spezifisches Detail modifiziert, während in der Kombination etwas völlig Neues entsteht. Um auf das Rapunzel-Beispiel zurückzukommen: Ein Adapter könnte die Haare verlängern, ein zweiter die Körperhaltung anpassen und ein dritter die Hautfarbe ändern. Ergänzt man dies um Adapter für den Gesichtsausdruck, die Augenfarbe oder die Kleidung, entsteht durch das gemeinsame Laden dieser unscheinbaren Einzelteile eine Rapunzel-Figur, die exakt den kombinierten Wünschen entspricht. Es entsteht eine Kette von Adaptern, bei der jedes Element wie ein kleines Rädchen in einem größeren Getriebe fungiert und die volle Wirkung erst im Zusammenspiel entfaltet wird. Hier ein Beispiel aus dem besagten Forum:

Dasselbe Prinzip lässt sich auf Sprachmodelle anwenden. Ein Adapter könnte das Modell anweisen, in formellem Amtsdeutsch zu antworten. Ein weiterer könnte ihm den Tonfall eines Sportkommentators verleihen. Ein dritter könnte sicherstellen, dass jede Antwort mit einem schlechten Witz endet. Kombiniert man diese Adapter, erhält man ein Modell, das hochseriös argumentiert und Fachbegriffe verwendet, am Ende aber dennoch einen Kalauer platziert. Adapter-Ketten stellen somit eine modulare Erweiterung dar, bei der kleine, kombinierte Änderungen eine gänzlich neue Ausdrucksform schaffen können.
Die Grenzen der LoRA-Technologie
Trotz seiner Wirksamkeit hat LoRA klare Grenzen. Die grundlegendste Regel ist, dass LoRA nur das verstärken oder modifizieren kann, was im Basismodell bereits latent vorhanden ist. Ein Bildmodell mag tausende von Frisuren kennen, weshalb es mithilfe eines Adapters möglich ist, Einstein als Friseur darzustellen, da Konzepte wie Haare, Scheren oder Friseurstühle bereits im Wissensschatz des Modells existieren. Der Versuch jedoch, Einstein darzustellen, wie er auf einem Saturnmond außerirdisches Kristallhaar schneidet, würde zu unbefriedigenden Ergebnissen führen, da diese Konzepte außerhalb des Wissensfundus des Basismodells liegen.
Ähnliches gilt für Sprachmodelle: LoRA kann die Gewichtung bestehender Wissenspfade verändern, aber es kann keine völlig neuen Fakten aus dem Nichts erschaffen. Um einem Modell gänzlich neues Wissen beizubringen, müssen entweder die Daten direkt in das Basismodell integriert oder intensivere Fine-Tuning-Methoden angewendet werden.
Eine weitere Einschränkung besteht in der Kombination zu vieler Adapter. Wenn zehn verschiedene Patches gleichzeitig geladen werden und alle auf dieselben Schichten des neuronalen Netzes zugreifen, können sie sich gegenseitig blockieren oder stören. Im Bereich der Bilderzeugung führt dies oft zu visuellen Artefakten oder unnatürlich wirkenden Darstellungen. Bei Sprachmodellen kann es zu Wiederholungen, logischen Widersprüchen oder unverständlichem Text führen. LoRA ist demnach kein Allheilmittel, sondern ein präzises Werkzeug, das gezielte Anpassungen ermöglicht, solange die Wissensgrundlage im Basismodell vorhanden ist und die Architektur korrekt verstanden wird.
Verantwortung und das Potenzial für Missbrauch
Der Einblick in die Foren-Diskussionen hat gezeigt, wie schnell die Anwendung von LoRA in problematische Bereiche abdriften kann. Ein Projekt, das als unschuldiges Comic für ein Kind begann, mündete in einer Welle von Patches zur Umsetzung von Fantasien, die urheberrechtlich oder moralisch bedenklich sind. An diesem Punkt wird die Frage der Verantwortung zentral.
LoRA senkt die technologische Einstiegshürde erheblich, da für das Training eines Adapters keine Supercomputer erforderlich sind. Ein handelsüblicher Computer mit einer leistungsfähigen Grafikkarte ist oft ausreichend. Diese Zugänglichkeit macht die Technologie ebenso faszinierend wie anfällig für Missbrauch. Im professionellen Kontext sind daher klare Richtlinien unerlässlich. Urheberrechte müssen respektiert und Marken dürfen nicht ohne entsprechende Lizenzen verwendet werden. Inhalte, die diffamierend oder verletzend sind, müssen tabu sein.
Unternehmen, die LoRA einsetzen, benötigen etablierte Prozesse für die Dokumentation, Freigaben und die Qualitätssicherung. LoRA ist somit ein Werkzeugkasten, der sowohl für kreative Innovationen als auch für riskante Vorhaben genutzt werden kann. Die letztendliche Anwendung, ob als nützliches Werkzeug oder für fragwürdige Experimente, hängt allein von den Zielen und der Verantwortung der Anwender ab.
Fazit: Kleine Eingriffe mit großer Wirkung
Zusammenfassend lässt sich sagen, dass LoRA einem eingefrorenen Basismodell gezielte Zusatzgewichte hinzufügt. Diese lenken den Informationsfluss um, vergleichbar mit neuen Abfahrten auf einer Autobahn, die den Verkehr in eine andere Richtung leiten. Auf diese Weise können Modelle zuverlässig modifiziert werden, ohne dass ein vollständiges und ressourcenintensives Neutraining erforderlich ist. Die Adapter lassen sich einzeln oder in kombinierten Ketten anwenden, was ein flexibles und modulares Baukastensystem für Anpassungen schafft.
Gleichzeitig ist es wichtig, die Grenzen von LoRA zu anerkennen: Die Methode kann nur verstärken, was im Basismodell bereits angelegt ist, und kommt an ihre Grenzen, wenn zu viele Adapter miteinander in Konflikt geraten.
Für IT-Fachleute kristallisiert sich eine zentrale Erkenntnis heraus: LoRA ist kein Wundermittel, sondern ein präzises, effizientes und wirkungsvolles Werkzeug. Es bietet eine ressourcenschonende Möglichkeit, große Sprach- und Bildmodelle schnell an spezifische Aufgaben, Fachgebiete oder stilistische Anforderungen anzupassen. Ob für spielerische Experimente wie die Umwandlung Einsteins in einen Friseur oder für ernsthafte Geschäftsanwendungen wie die Implementierung branchenspezifischer Fachsprache, interner Wissensdatenbanken oder formaler Kommunikationsrichtlinien: LoRA ermöglicht eine kontrollierte, kostengünstige und zielgerichtete Modulation großer KI-Modelle.