Mein Name ist Aaron Kreis und dieser Blog ist der Ort, an dem ich meine Interessen und Projekte dokumentiere. Egal ob es sich um eine spontane Idee, eine kurze Notiz oder die ausführliche Recherche zu einem komplexen Thema handelt, hier sammle ich die Dinge, die mich umtreiben, und mache sie öffentlich zugänglich.

KI-Strategiepapier.de: Warum die meisten KI-Initiativen im Experimentierstadium stecken bleiben
Das Projekt KI-Strategiepapier.de ist ein digitales Nachschlagewerk für Unternehmen, die Künstliche Intelligenz nicht nur ausprobieren, sondern tatsächlich strategisch verankern wollen. Es gibt bereits viele Papiere, die erklären, warum KI wichtig ist, aber kaum eines, das konkret zeigt, wie die Umsetzung im Unternehmensalltag aussieht. Genau dort setzt das Strategiepapier an: Es begleitet Fachleute und Entscheidungsträger Schritt für Schritt von der ersten Standortbestimmung bis zum produktiven Betrieb, mit direkt einsetzbaren Vorlagen statt reiner Theorie. ...

Vibe Coding: Spotify-Playlists nach YouTube spiegeln
Einleitung: Warum ich meine Playlists spiegeln wollte Ich höre auf Spotify, brauche dieselben Playlists aber gelegentlich auch auf YouTube, etwa für ein Gerät ohne Spotify, fürs Teilen oder für Hintergrundvideos. Das jedes Mal von Hand nachzubauen ist mühsam. Also habe ich ein Tool geschrieben, das genau das übernimmt, und es als Open Source veröffentlicht. Was es macht Eine schlanke Weboberfläche zeigt deine Spotify-Playlists durchnummeriert und alphabetisch. Du wählst eine, mehrere oder alle aus, und das Tool legt die passende YouTube-Playlist an oder findet eine bereits vorhandene und füllt sie mit denselben Liedern. ...

Das 5-Phasenmodell der Anforderungsanalyse
Einleitung: Weshalb Requirements Engineering das Fundament jedes Projekts bildet Fehler in der Anforderungsphase verursachen im späteren Projektverlauf die höchsten Kosten. Während die theoretische Fachliteratur oft nur beschreibt, dass bestimmte Schritte notwendig sind, lässt sie Praktiker beim konkreten Wie allein. Das Projekt RE-Framework.de schließt genau diese Lücke zwischen Theorie und Praxis. Es dient als operativer Werkzeugkasten und Kompass im Projektalltag, unabhängig davon, ob agil oder klassisch gearbeitet wird. Das Herzstück: Ein Katalog aus ca. 2.000 spezifischen Fragen Die Qualität von Anforderungen hängt direkt von der Qualität der gestellten Fragen ab. Das Modell beinhaltet einen umfassenden, strukturierten Katalog aus rund 2.000 spezifischen Fragen. Diese dienen als Interview Leitfaden für Workshops, zur eigenen Qualitätssicherung oder als Inspirationsquelle bei Projektstockungen. ...

Digitale Abhängigkeit von USA und China. Wie wir die Kontrolle über unsere Infrastruktur verloren haben
Unter dem folgenden Link findet sich eine interaktive Übersicht, die als exemplarischer Auszug die vielschichtigen digitalen Abhängigkeiten von den USA und China verdeutlicht: Link 1. Stille Abhängigkeit: Wie sie entstand und warum sie gefährlich ist Wer morgens sein Smartphone entsperrt, öffnet in diesem Moment ein Betriebssystem aus Kalifornien oder Shenzhen. Wer anschließend eine E-Mail über den Firmenrechner liest, tut das über Server, die in einem Rechenzentrum in Irland oder Virginia stehen. Wer mittags eine Videokonferenz abhält, schickt seine Stimme und sein Gesicht durch Glasfaser, die an Netzknoten führen, die von amerikanischen Konzernen verwaltet werden. Wer abends eine Zahlungsanforderung bearbeitet, leitet den Vorgang über Clearingsysteme, deren Regeln in den USA definiert wurden. ...

Absicherung eines Ubuntu-Servers für den öffentlichen OpenClaw-Einsatz
Die Sicherheit eines Servers, der für Applikationen wie OpenClaw vorgesehen ist, basiert nicht allein auf der Software selbst, sondern maßgeblich auf der Härtung des zugrundeliegenden Betriebssystems. Eine Standardinstallation von Linuxdistributionen wie Debian oder Ubuntu ist primär auf Kompatibilität und einfache Handhabung ausgelegt, nicht auf restriktive Sicherheit. Dies resultiert initial in einer unnötig großen Angriffsfläche. Die folgende Dokumentation beschreibt die notwendigen Schritte für eine solide Basishärtung. Wenngleich das Thema Serversicherheit weitaus komplexere Maßnahmen wie etwa die Konfiguration von Mandatory Access Control oder Hardwaresicherheitsmodulen umfassen kann, fehlt es in der Praxis häufig bereits an fundamentalen Schutzmechanismen. Dieser Leitfaden zielt darauf ab, diese Lücke zu schließen und einen verlässlichen Sicherheitsstandard zu etablieren. Ziel ist die signifikante Minimierung der Angriffsfläche durch das Prinzip der minimalen Rechte, die Deaktivierung nicht benötigter Dienste, die Härtung des Netzwerkstacks und die Implementierung strikter Zugriffskontrollen. ...

KI im Rotlicht: Von Rapunzel-Fantasien zu haarigen Antworten mit LoRA
Einleitung: Die gezielte Steuerung von Sprachmodellen Die zentrale Herausforderung im Umgang mit großen Sprachmodellen lautet: Wie lassen sich deren Antworten präzise und zuverlässig in eine gewünschte Richtung lenken? Nehmen wir als Beispiel ein Modell wie ChatGPT. Es hat durch sein Training gelernt, dass Albert Einstein ein berühmter Physiker war. Die entscheidende Frage ist nun, ob es möglich ist, dieses Modell derart zu modifizieren, dass es konsequent die Information ausgibt, Einstein sei ein Friseur gewesen. Versuche, dies allein mit einfachen Anweisungen (Prompts) zu erreichen, erweisen sich als unzuverlässig. Manchmal gelingt es, oft aber auch nicht. Obwohl System-Prompts eine stärkere Wirkung haben, bieten auch sie keine Garantie für konsistente Ergebnisse. ...

OpenClaw unter Windows via Docker inkl. Telegram-Pairing
Dieser Leitfaden beschreibt die Schritte zur Einrichtung einer lokalen OpenClaw-Instanz. Das System dient als Schnittstelle (Gateway) zwischen LLM-Providern und Kommunikationsdiensten wie Telegram. Die Installation erfolgt containerisiert mittels Docker. Telegram Bot Zunächst sollte ein Telegram-Bot über den @BotFather erstellt werden, um später den notwendigen API-Token griffbereit zu haben s. Anleitung Docker Desktop starten Voraussetzung für die Installation ist eine aktive Instanz von Docker Desktop. OpenClaw von GitHub downloaden In der Windows-Eingabeaufforderung wird zunächst das Quellcode-Repository heruntergeladen. Dies erfolgt über den Befehl: ...

KI-Musik & Deutsch: Der Knoten ist endlich geplatzt!
Ich habe einen weiteren Versuch gewagt, Musik mit KI zu generieren. Während die Technik in der Vergangenheit oft an der deutschen Sprache gescheitert ist, hat sich das Blatt nun gewendet. Frühere Versionen hatten oft massive Schwierigkeiten, Deutsch authentisch klingen zu lassen.Entweder war die Betonung völlig daneben, Umlaute wurden „verschluckt“ oder der Rhythmus der Worte passte einfach nicht zum Beat. Es klang oft eher nach einem bemühten Roboter als nach echtem Gesang. ...
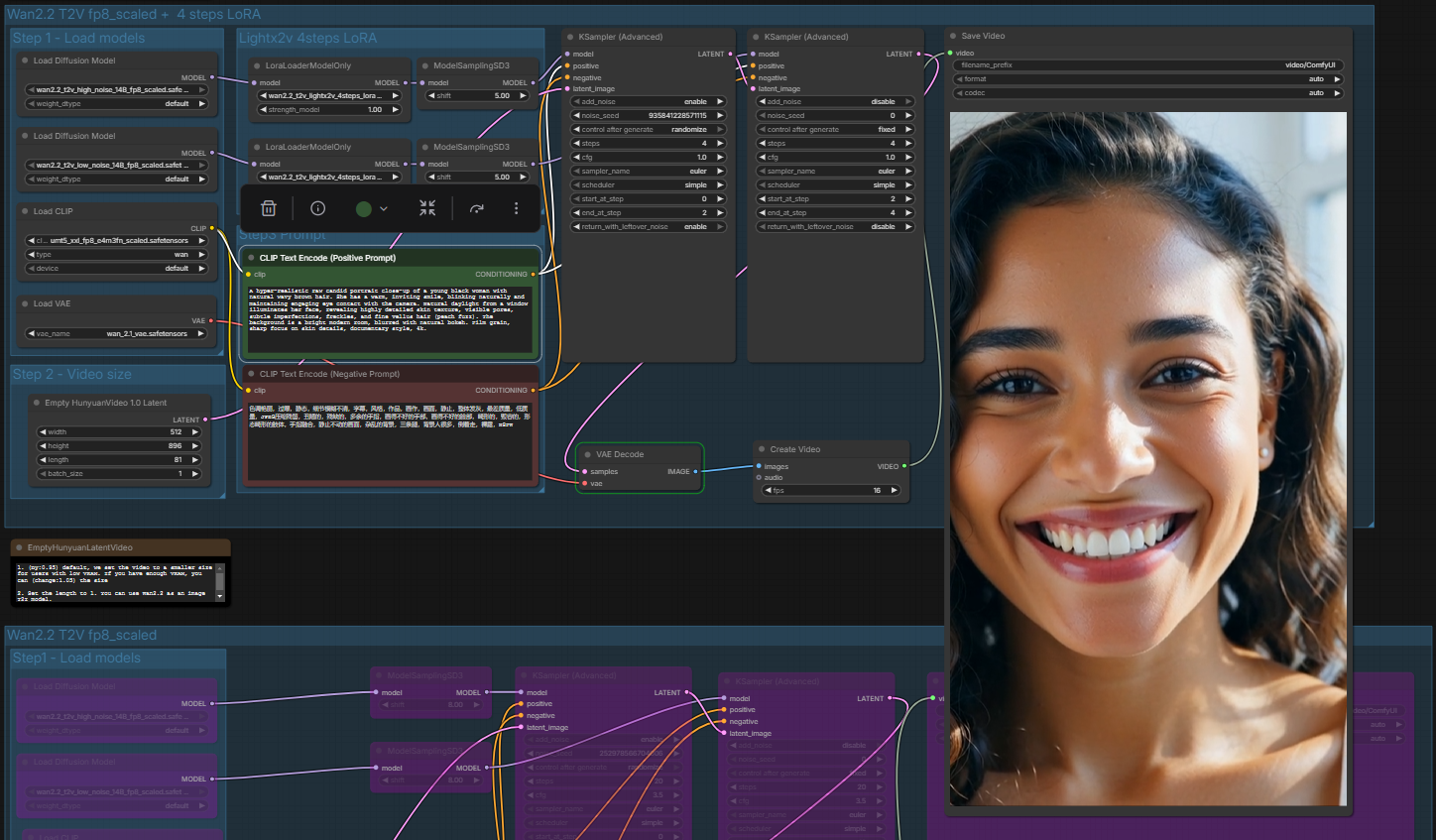
Lokale Video- und Bild-Produktion: Ein Workflow mit n8n, Google Sheets und ComfyUI
Die Automatisierung der Generierung von KI-Inhalten bietet eine effiziente Lösung, um den manuellen Aufwand bei der Erstellung von Bild- und Videomaterial deutlich zu reduzieren. Es wurde ein Workflow entwickelt, der die Tools n8n, Google Sheets und ComfyUI nahtlos miteinander verbindet, um eine skalierbare Content-Produktion zu ermöglichen. Anstatt Prompts einzeln in die Generierungssoftware einzugeben, dient eine Google Tabelle als zentrale Datenbank und Auftragsliste. Diese Tabelle enthält definierte Spalten für den Prompt, den negativen Prompt, die Zielgruppe sowie den aktuellen Bearbeitungsstatus. Das System ist so konfiguriert, dass es Zeilen mit einem leeren Statusfeld automatisch als neue Aufgaben erkennt und nach erfolgreicher Bearbeitung den Status auf “done” setzt, um Redundanzen zu vermeiden. ...

Vibe Coding: Ein KI-generierter Telegram Desktop Client
In der modernen Softwareentwicklung vollzieht sich ein Paradigmenwechsel da die Hürde komplexe und maßgeschneiderte Softwarelösungen zu erstellen drastisch gesunken ist. Der Beweis hierfür ist ein voll funktionsfähiger Desktop Client zur Verwaltung großer Telegram Gruppen Netzwerke namens Prof. Dr. Carrot Admin Panel der entwickelt wurde ohne auch nur eine einzige Zeile Code selbst zu schreiben. Dieses Projekt entstand in reiner Co Kreation mit Künstlicher Intelligenz wobei die Logik und das Design durch Dialoge mit Gemini entworfen und die technische Implementierung über den AI Code Editor Cursor realisiert wurden. Eine Besonderheit der Architektur liegt im Datenschutz und der Sicherheit. Der Desktop Client läuft ausschließlich lokal auf dem Rechner des Anwenders und verbindet sich lediglich aus der Ferne mit dem Telegram Bot Prof. Dr. Carrot um diesen fernzusteuern. Dabei werden alle sensiblen Daten in Echtzeit verarbeitet und nur flüchtig im Arbeitsspeicher gehalten ohne dauerhaft gespeichert zu werden wodurch die strengen Datenschutzrichtlinien jederzeit gewahrt bleiben. ...